 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA hybrid framework for effective and efficient machine unlearning
Dec 19, 2024Recently machine unlearning (MU) is proposed to remove the imprints of revoked samples from the already trained model parameters, to solve users' privacy concern. Different from the runtime expensive retraining from scratch, there exist two research lines, exact MU and approximate MU with different favorites in terms of accuracy and efficiency. In this paper, we present a novel hybrid strategy on top of them to achieve an overall success. It implements the unlearning operation with an acceptable computation cost, while simultaneously improving the accuracy as much as possible. Specifically, it runs reasonable unlearning techniques by estimating the retraining workloads caused by revocations. If the workload is lightweight, it performs retraining to derive the model parameters consistent with the accurate ones retrained from scratch. Otherwise, it outputs the unlearned model by directly modifying the current parameters, for better efficiency. In particular, to improve the accuracy in the latter case, we propose an optimized version to amend the output model with lightweight runtime penalty. We particularly study the boundary of two approaches in our frameworks to adaptively make the smart selection. Extensive experiments on real datasets validate that our proposals can improve the unlearning efficiency by 1.5$\times$ to 8$\times$ while achieving comparable accuracy.
DialCLIP: Empowering CLIP as Multi-Modal Dialog Retriever
Jan 03, 2024Recently, substantial advancements in pre-trained vision-language models have greatly enhanced the capabilities of multi-modal dialog systems. These models have demonstrated significant improvements by fine-tuning on downstream tasks. However, the existing pre-trained models primarily focus on effectively capturing the alignment between vision and language modalities, often ignoring the intricate nature of dialog context. In this paper, we propose a parameter-efficient prompt-tuning method named DialCLIP for multi-modal dialog retrieval. Specifically, our approach introduces a multi-modal context prompt generator to learn context features which are subsequently distilled into prompts within the pre-trained vision-language model CLIP. Besides, we introduce domain prompt to mitigate the disc repancy from the downstream dialog data. To facilitate various types of retrieval, we also design multiple experts to learn mappings from CLIP outputs to multi-modal representation space, with each expert being responsible to one specific retrieval type. Extensive experiments show that DialCLIP achieves state-of-the-art performance on two widely recognized benchmark datasets (i.e., PhotoChat and MMDialog) by tuning a mere 0.04% of the total parameters. These results highlight the efficacy and efficiency of our proposed approach, underscoring its potential to advance the field of multi-modal dialog retrieval.
Hierarchical Discrete Distribution Decomposition for Match Density Estimation
Dec 29, 2018
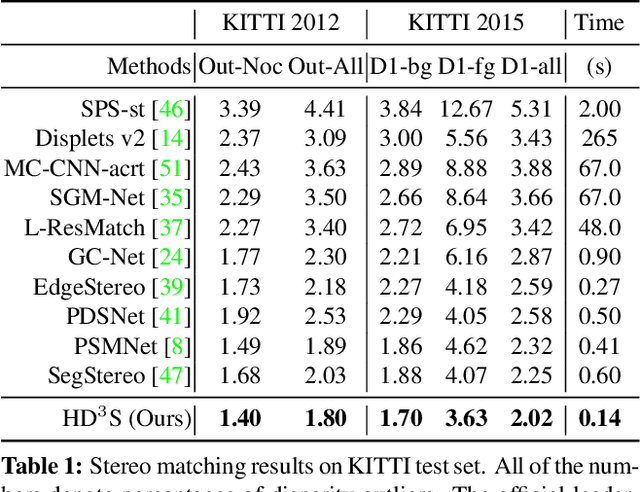
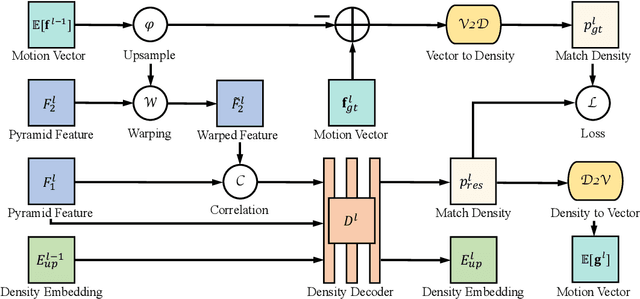
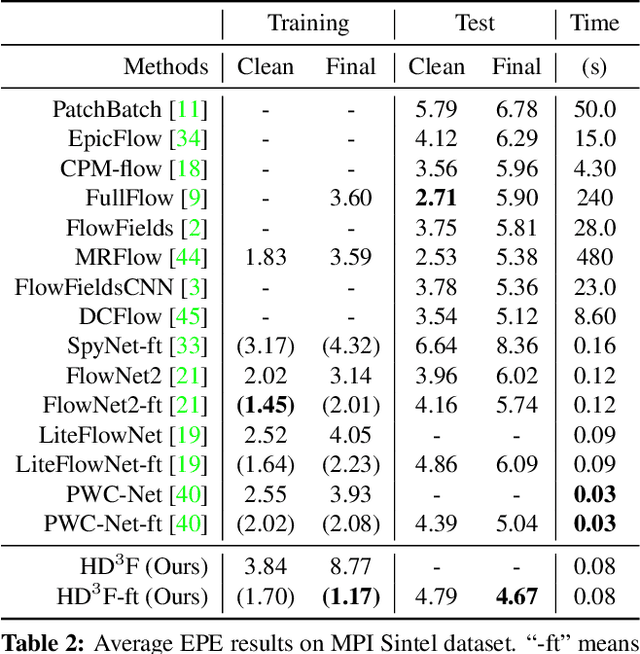
Existing deep learning methods for pixel correspondence output a point estimate of the motion field, but do not represent the full match distribution. Explicit representation of a match distribution is desirable for many applications as it allows direct representation of the correspondence probability. The main difficulty of estimating a full probability distribution with a deep network is the high computational cost of inferring the entire distribution. In this paper, we propose Hierarchical Discrete Distribution Decomposition, dubbed HD$^3$, to learn probabilistic point and region matching. Not only can it model match uncertainty, but also region propagation. To achieve this, we estimate the hierarchical distribution of pixel correspondences at different image scales without multi-hypotheses ensembling. Despite its simplicity, our method can achieve competitive results for both optical flow and stereo matching on established benchmarks, while the estimated uncertainty is a good indicator of errors. Furthermore, the point match distribution within a region can be grouped together to propagate the whole region even if the area changes across images.
Generative Adversarial Frontal View to Bird View Synthesis
Aug 01, 2018
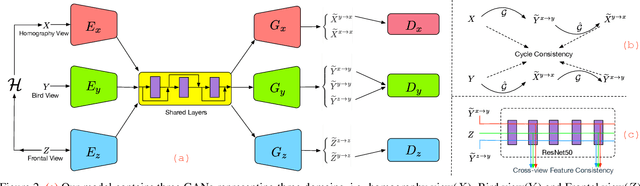
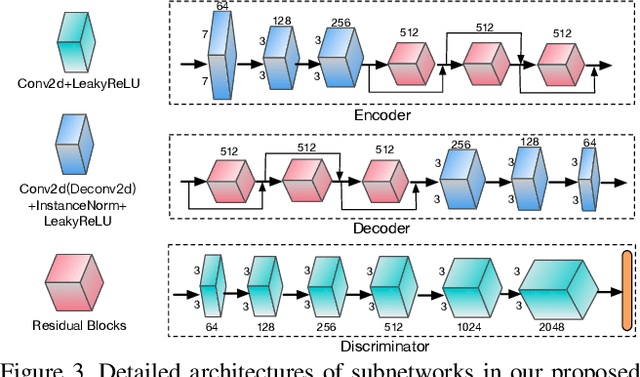
Environment perception is an important task with great practical value and bird view is an essential part for creating panoramas of surrounding environment. Due to the large gap and severe deformation between the frontal view and bird view, generating a bird view image from a single frontal view is challenging. To tackle this problem, we propose the BridgeGAN, i.e., a novel generative model for bird view synthesis. First, an intermediate view, i.e., homography view, is introduced to bridge the large gap. Next, conditioned on the three views (frontal view, homography view and bird view) in our task, a multi-GAN based model is proposed to learn the challenging cross-view translation. Extensive experiments conducted on a synthetic dataset have demonstrated that the images generated by our model are much better than those generated by existing methods, with more consistent global appearance and sharper details. Ablation studies and discussions show its reliability and robustness in some challenging cases.
GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose
Mar 12, 2018
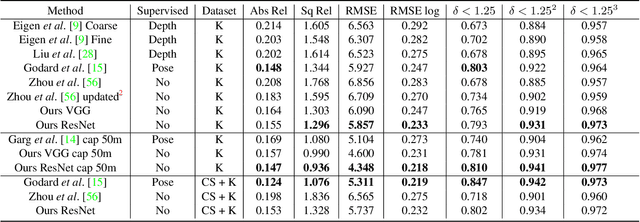
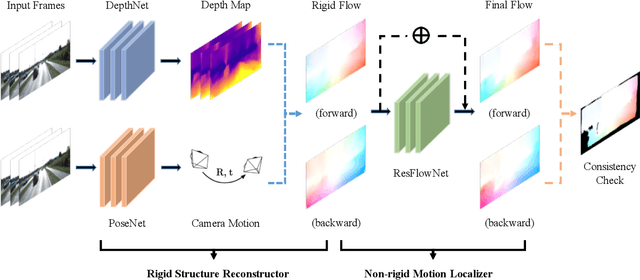
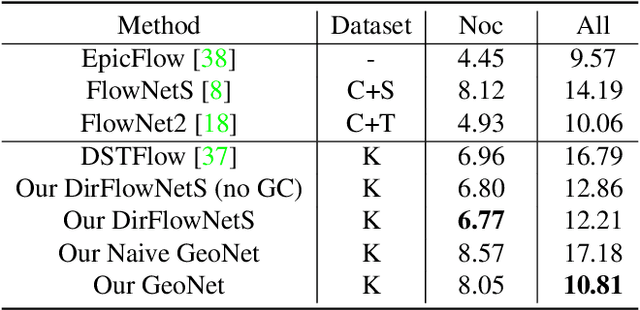
We propose GeoNet, a jointly unsupervised learning framework for monocular depth, optical flow and ego-motion estimation from videos. The three components are coupled by the nature of 3D scene geometry, jointly learned by our framework in an end-to-end manner. Specifically, geometric relationships are extracted over the predictions of individual modules and then combined as an image reconstruction loss, reasoning about static and dynamic scene parts separately. Furthermore, we propose an adaptive geometric consistency loss to increase robustness towards outliers and non-Lambertian regions, which resolves occlusions and texture ambiguities effectively. Experimentation on the KITTI driving dataset reveals that our scheme achieves state-of-the-art results in all of the three tasks, performing better than previously unsupervised methods and comparably with supervised ones.