 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Aug 04, 2023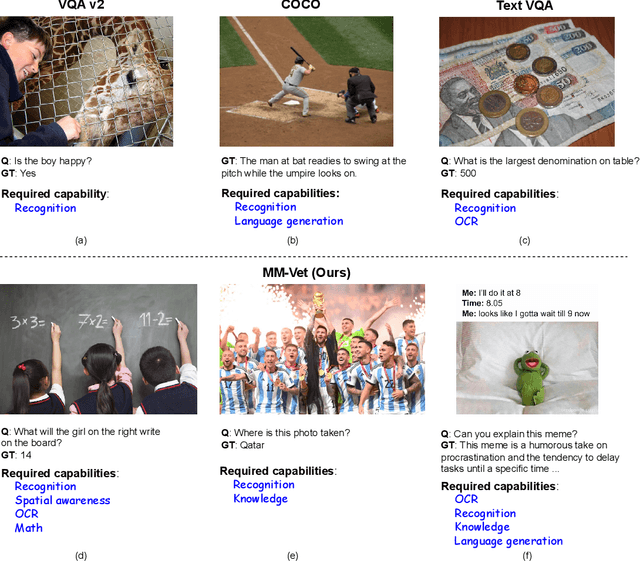

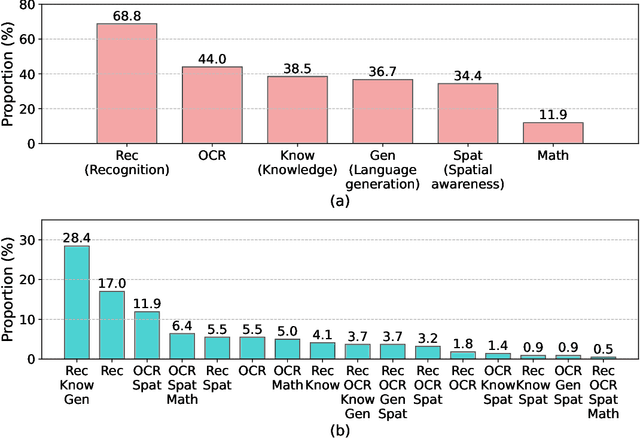
We propose MM-Vet, an evaluation benchmark that examines large multimodal models (LMMs) on complicated multimodal tasks. Recent LMMs have shown various intriguing abilities, such as solving math problems written on the blackboard, reasoning about events and celebrities in news images, and explaining visual jokes. Rapid model advancements pose challenges to evaluation benchmark development. Problems include: (1) How to systematically structure and evaluate the complicated multimodal tasks; (2) How to design evaluation metrics that work well across question and answer types; and (3) How to give model insights beyond a simple performance ranking. To this end, we present MM-Vet, designed based on the insight that the intriguing ability to solve complicated tasks is often achieved by a generalist model being able to integrate different core vision-language (VL) capabilities. MM-Vet defines 6 core VL capabilities and examines the 16 integrations of interest derived from the capability combination. For evaluation metrics, we propose an LLM-based evaluator for open-ended outputs. The evaluator enables the evaluation across different question types and answer styles, resulting in a unified scoring metric. We evaluate representative LMMs on MM-Vet, providing insights into the capabilities of different LMM system paradigms and models. Code and data are available at https://github.com/yuweihao/MM-Vet.
Spatial-Frequency U-Net for Denoising Diffusion Probabilistic Models
Jul 27, 2023In this paper, we study the denoising diffusion probabilistic model (DDPM) in wavelet space, instead of pixel space, for visual synthesis. Considering the wavelet transform represents the image in spatial and frequency domains, we carefully design a novel architecture SFUNet to effectively capture the correlation for both domains. Specifically, in the standard denoising U-Net for pixel data, we supplement the 2D convolutions and spatial-only attention layers with our spatial frequency-aware convolution and attention modules to jointly model the complementary information from spatial and frequency domains in wavelet data. Our new architecture can be used as a drop-in replacement to the pixel-based network and is compatible with the vanilla DDPM training process. By explicitly modeling the wavelet signals, we find our model is able to generate images with higher quality on CIFAR-10, FFHQ, LSUN-Bedroom, and LSUN-Church datasets, than the pixel-based counterpart.
Aligning Large Multi-Modal Model with Robust Instruction Tuning
Jun 26, 2023Despite the promising progress in multi-modal tasks, current large multi-modal models (LMM) are prone to hallucinating inconsistent descriptions with respect to the associated image and human instructions. This paper addresses this issue by introducing the first large and diverse visual instruction tuning dataset, named Large-scale Robust Visual (LRV)-Instruction. Our dataset consists of 120k visual instructions generated by GPT4, covering 16 vision-and-language tasks with open-ended instructions and answers. Unlike existing studies that primarily focus on positive instruction samples, we design LRV-Instruction to include both positive and negative instructions for more robust visual instruction tuning. Our negative instructions are designed at two semantic levels: (i) Nonexistent Element Manipulation and (ii) Existent Element Manipulation. To efficiently measure the hallucination generated by LMMs, we propose GPT4-Assisted Visual Instruction Evaluation (GAVIE), a novel approach to evaluate visual instruction tuning without the need for human-annotated groundtruth answers and can adapt to diverse instruction formats. We conduct comprehensive experiments to investigate the hallucination of LMMs. Our results demonstrate that existing LMMs exhibit significant hallucination when presented with our negative instructions, particularly with Existent Element Manipulation instructions. Moreover, by finetuning MiniGPT4 on LRV-Instruction, we successfully mitigate hallucination while improving performance on public datasets using less training data compared to state-of-the-art methods. Additionally, we observed that a balanced ratio of positive and negative instances in the training data leads to a more robust model. Our project link is available at https://fuxiaoliu.github.io/LRV/.
MultiSum: A Dataset for Multimodal Summarization and Thumbnail Generation of Videos
Jun 07, 2023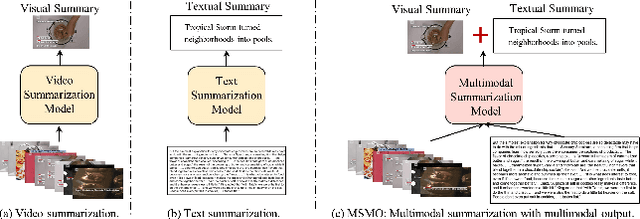
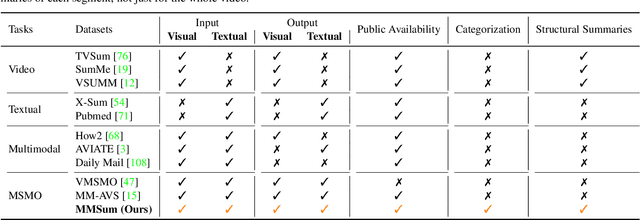
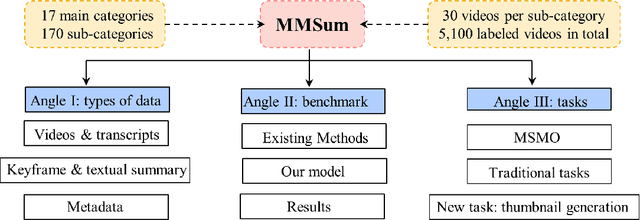
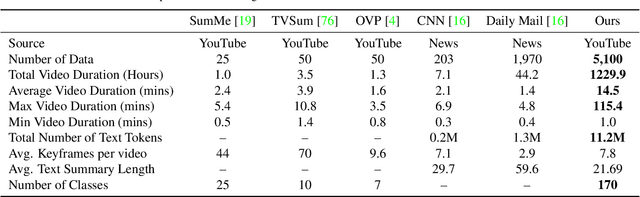
Multimodal summarization with multimodal output (MSMO) has emerged as a promising research direction. Nonetheless, numerous limitations exist within existing public MSMO datasets, including insufficient upkeep, data inaccessibility, limited size, and the absence of proper categorization, which pose significant challenges to effective research. To address these challenges and provide a comprehensive dataset for this new direction, we have meticulously curated the MultiSum dataset. Our new dataset features (1) Human-validated summaries for both video and textual content, providing superior human instruction and labels for multimodal learning. (2) Comprehensively and meticulously arranged categorization, spanning 17 principal categories and 170 subcategories to encapsulate a diverse array of real-world scenarios. (3) Benchmark tests performed on the proposed dataset to assess varied tasks and methods, including video temporal segmentation, video summarization, text summarization, and multimodal summarization. To champion accessibility and collaboration, we release the MultiSum dataset and the data collection tool as fully open-source resources, fostering transparency and accelerating future developments. Our project website can be found at https://multisum-dataset.github.io/.
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation
Mar 22, 2023



In this paper, we propose NUWA-XL, a novel Diffusion over Diffusion architecture for eXtremely Long video generation. Most current work generates long videos segment by segment sequentially, which normally leads to the gap between training on short videos and inferring long videos, and the sequential generation is inefficient. Instead, our approach adopts a ``coarse-to-fine'' process, in which the video can be generated in parallel at the same granularity. A global diffusion model is applied to generate the keyframes across the entire time range, and then local diffusion models recursively fill in the content between nearby frames. This simple yet effective strategy allows us to directly train on long videos (3376 frames) to reduce the training-inference gap, and makes it possible to generate all segments in parallel. To evaluate our model, we build FlintstonesHD dataset, a new benchmark for long video generation. Experiments show that our model not only generates high-quality long videos with both global and local coherence, but also decreases the average inference time from 7.55min to 26s (by 94.26\%) at the same hardware setting when generating 1024 frames. The homepage link is \url{https://msra-nuwa.azurewebsites.net/}
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Mar 20, 2023



We propose MM-REACT, a system paradigm that integrates ChatGPT with a pool of vision experts to achieve multimodal reasoning and action. In this paper, we define and explore a comprehensive list of advanced vision tasks that are intriguing to solve, but may exceed the capabilities of existing vision and vision-language models. To achieve such advanced visual intelligence, MM-REACT introduces a textual prompt design that can represent text descriptions, textualized spatial coordinates, and aligned file names for dense visual signals such as images and videos. MM-REACT's prompt design allows language models to accept, associate, and process multimodal information, thereby facilitating the synergetic combination of ChatGPT and various vision experts. Zero-shot experiments demonstrate MM-REACT's effectiveness in addressing the specified capabilities of interests and its wide application in different scenarios that require advanced visual understanding. Furthermore, we discuss and compare MM-REACT's system paradigm with an alternative approach that extends language models for multimodal scenarios through joint finetuning. Code, demo, video, and visualization are available at https://multimodal-react.github.io/
Learning 3D Photography Videos via Self-supervised Diffusion on Single Images
Feb 21, 2023



3D photography renders a static image into a video with appealing 3D visual effects. Existing approaches typically first conduct monocular depth estimation, then render the input frame to subsequent frames with various viewpoints, and finally use an inpainting model to fill those missing/occluded regions. The inpainting model plays a crucial role in rendering quality, but it is normally trained on out-of-domain data. To reduce the training and inference gap, we propose a novel self-supervised diffusion model as the inpainting module. Given a single input image, we automatically construct a training pair of the masked occluded image and the ground-truth image with random cycle-rendering. The constructed training samples are closely aligned to the testing instances, without the need of data annotation. To make full use of the masked images, we design a Masked Enhanced Block (MEB), which can be easily plugged into the UNet and enhance the semantic conditions. Towards real-world animation, we present a novel task: out-animation, which extends the space and time of input objects. Extensive experiments on real datasets show that our method achieves competitive results with existing SOTA methods.
NP-Match: Towards a New Probabilistic Model for Semi-Supervised Learning
Jan 31, 2023Semi-supervised learning (SSL) has been widely explored in recent years, and it is an effective way of leveraging unlabeled data to reduce the reliance on labeled data. In this work, we adjust neural processes (NPs) to the semi-supervised image classification task, resulting in a new method named NP-Match. NP-Match is suited to this task for two reasons. Firstly, NP-Match implicitly compares data points when making predictions, and as a result, the prediction of each unlabeled data point is affected by the labeled data points that are similar to it, which improves the quality of pseudo-labels. Secondly, NP-Match is able to estimate uncertainty that can be used as a tool for selecting unlabeled samples with reliable pseudo-labels. Compared with uncertainty-based SSL methods implemented with Monte-Carlo (MC) dropout, NP-Match estimates uncertainty with much less computational overhead, which can save time at both the training and the testing phases. We conducted extensive experiments on five public datasets under three semi-supervised image classification settings, namely, the standard semi-supervised image classification, the imbalanced semi-supervised image classification, and the multi-label semi-supervised image classification, and NP-Match outperforms state-of-the-art (SOTA) approaches or achieves competitive results on them, which shows the effectiveness of NP-Match and its potential for SSL. The codes are at https://github.com/Jianf-Wang/NP-Match
Generalized Decoding for Pixel, Image, and Language
Dec 21, 2022



We present X-Decoder, a generalized decoding model that can predict pixel-level segmentation and language tokens seamlessly. X-Decodert takes as input two types of queries: (i) generic non-semantic queries and (ii) semantic queries induced from text inputs, to decode different pixel-level and token-level outputs in the same semantic space. With such a novel design, X-Decoder is the first work that provides a unified way to support all types of image segmentation and a variety of vision-language (VL) tasks. Further, our design enables seamless interactions across tasks at different granularities and brings mutual benefits by learning a common and rich pixel-level visual-semantic understanding space, without any pseudo-labeling. After pretraining on a mixed set of a limited amount of segmentation data and millions of image-text pairs, X-Decoder exhibits strong transferability to a wide range of downstream tasks in both zero-shot and finetuning settings. Notably, it achieves (1) state-of-the-art results on open-vocabulary segmentation and referring segmentation on eight datasets; (2) better or competitive finetuned performance to other generalist and specialist models on segmentation and VL tasks; and (3) flexibility for efficient finetuning and novel task composition (e.g., referring captioning and image editing). Code, demo, video, and visualization are available at https://x-decoder-vl.github.io.
Exploring Discrete Diffusion Models for Image Captioning
Dec 09, 2022



The image captioning task is typically realized by an auto-regressive method that decodes the text tokens one by one. We present a diffusion-based captioning model, dubbed the name DDCap, to allow more decoding flexibility. Unlike image generation, where the output is continuous and redundant with a fixed length, texts in image captions are categorical and short with varied lengths. Therefore, naively applying the discrete diffusion model to text decoding does not work well, as shown in our experiments. To address the performance gap, we propose several key techniques including best-first inference, concentrated attention mask, text length prediction, and image-free training. On COCO without additional caption pre-training, it achieves a CIDEr score of 117.8, which is +5.0 higher than the auto-regressive baseline with the same architecture in the controlled setting. It also performs +26.8 higher CIDEr score than the auto-regressive baseline (230.3 v.s.203.5) on a caption infilling task. With 4M vision-language pre-training images and the base-sized model, we reach a CIDEr score of 125.1 on COCO, which is competitive to the best well-developed auto-regressive frameworks. The code is available at https://github.com/buxiangzhiren/DDCap.