 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynonymix: Unified Group Personas for Generative Simulations
Mar 30, 2026Generative agent simulations operate at two scales: individual personas for character interaction, and population models for collective behavior analysis and intervention testing. We propose a third scale: meso-level simulation - interaction with group-level representations that retain grounding in rich individual experience. To enable this, we present Synonymix, a pipeline that constructs a "unigraph" from multiple life story personas via graph-based abstraction and merging, producing a queryable collective representation that can be explored for sensemaking or sampled for synthetic persona generation. Evaluating synthetic agents on General Social Survey items, we demonstrate behavioral signal preservation beyond demographic baselines (p<0.001, r=0.59) with demonstrable privacy guarantee (max source contribution <13%). We invite discussion on interaction modalities enabled by meso-level simulations, and whether "high-fidelity" personas can ever capture the texture of lived experience.
MultiSum: A Dataset for Multimodal Summarization and Thumbnail Generation of Videos
Jun 07, 2023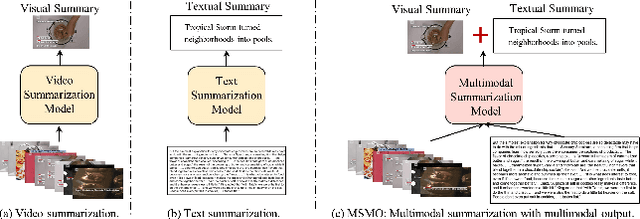
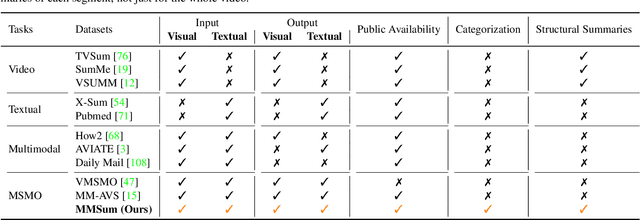
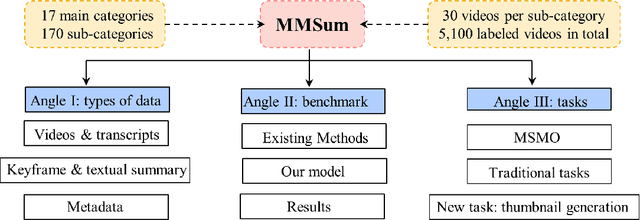
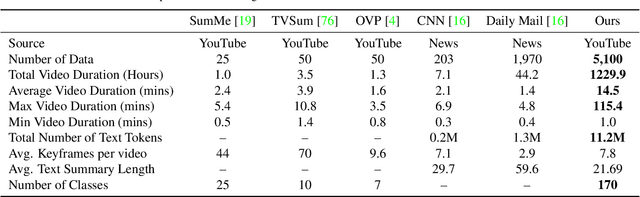
Multimodal summarization with multimodal output (MSMO) has emerged as a promising research direction. Nonetheless, numerous limitations exist within existing public MSMO datasets, including insufficient upkeep, data inaccessibility, limited size, and the absence of proper categorization, which pose significant challenges to effective research. To address these challenges and provide a comprehensive dataset for this new direction, we have meticulously curated the MultiSum dataset. Our new dataset features (1) Human-validated summaries for both video and textual content, providing superior human instruction and labels for multimodal learning. (2) Comprehensively and meticulously arranged categorization, spanning 17 principal categories and 170 subcategories to encapsulate a diverse array of real-world scenarios. (3) Benchmark tests performed on the proposed dataset to assess varied tasks and methods, including video temporal segmentation, video summarization, text summarization, and multimodal summarization. To champion accessibility and collaboration, we release the MultiSum dataset and the data collection tool as fully open-source resources, fostering transparency and accelerating future developments. Our project website can be found at https://multisum-dataset.github.io/.