 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucinations in Diffusion Models through Adaptive Attention Modulation
Feb 24, 2025



Diffusion models, while increasingly adept at generating realistic images, are notably hindered by hallucinations -- unrealistic or incorrect features inconsistent with the trained data distribution. In this work, we propose Adaptive Attention Modulation (AAM), a novel approach to mitigate hallucinations by analyzing and modulating the self-attention mechanism in diffusion models. We hypothesize that self-attention during early denoising steps may inadvertently amplify or suppress features, contributing to hallucinations. To counter this, AAM introduces a temperature scaling mechanism within the softmax operation of the self-attention layers, dynamically modulating the attention distribution during inference. Additionally, AAM employs a masked perturbation technique to disrupt early-stage noise that may otherwise propagate into later stages as hallucinations. Extensive experiments demonstrate that AAM effectively reduces hallucinatory artifacts, enhancing both the fidelity and reliability of generated images. For instance, the proposed approach improves the FID score by 20.8% and reduces the percentage of hallucinated images by 12.9% (in absolute terms) on the Hands dataset.
Eagle: Exploring The Design Space for Multimodal LLMs with Mixture of Encoders
Aug 28, 2024



The ability to accurately interpret complex visual information is a crucial topic of multimodal large language models (MLLMs). Recent work indicates that enhanced visual perception significantly reduces hallucinations and improves performance on resolution-sensitive tasks, such as optical character recognition and document analysis. A number of recent MLLMs achieve this goal using a mixture of vision encoders. Despite their success, there is a lack of systematic comparisons and detailed ablation studies addressing critical aspects, such as expert selection and the integration of multiple vision experts. This study provides an extensive exploration of the design space for MLLMs using a mixture of vision encoders and resolutions. Our findings reveal several underlying principles common to various existing strategies, leading to a streamlined yet effective design approach. We discover that simply concatenating visual tokens from a set of complementary vision encoders is as effective as more complex mixing architectures or strategies. We additionally introduce Pre-Alignment to bridge the gap between vision-focused encoders and language tokens, enhancing model coherence. The resulting family of MLLMs, Eagle, surpasses other leading open-source models on major MLLM benchmarks. Models and code: https://github.com/NVlabs/Eagle
AVFF: Audio-Visual Feature Fusion for Video Deepfake Detection
Jun 05, 2024



With the rapid growth in deepfake video content, we require improved and generalizable methods to detect them. Most existing detection methods either use uni-modal cues or rely on supervised training to capture the dissonance between the audio and visual modalities. While the former disregards the audio-visual correspondences entirely, the latter predominantly focuses on discerning audio-visual cues within the training corpus, thereby potentially overlooking correspondences that can help detect unseen deepfakes. We present Audio-Visual Feature Fusion (AVFF), a two-stage cross-modal learning method that explicitly captures the correspondence between the audio and visual modalities for improved deepfake detection. The first stage pursues representation learning via self-supervision on real videos to capture the intrinsic audio-visual correspondences. To extract rich cross-modal representations, we use contrastive learning and autoencoding objectives, and introduce a novel audio-visual complementary masking and feature fusion strategy. The learned representations are tuned in the second stage, where deepfake classification is pursued via supervised learning on both real and fake videos. Extensive experiments and analysis suggest that our novel representation learning paradigm is highly discriminative in nature. We report 98.6% accuracy and 99.1% AUC on the FakeAVCeleb dataset, outperforming the current audio-visual state-of-the-art by 14.9% and 9.9%, respectively.
MMC: Advancing Multimodal Chart Understanding with Large-scale Instruction Tuning
Nov 15, 2023



With the rapid development of large language models (LLMs) and their integration into large multimodal models (LMMs), there has been impressive progress in zero-shot completion of user-oriented vision-language tasks. However, a gap remains in the domain of chart image understanding due to the distinct abstract components in charts. To address this, we introduce a large-scale MultiModal Chart Instruction (MMC-Instruction) dataset comprising 600k instances supporting diverse tasks and chart types. Leveraging this data, we develop MultiModal Chart Assistant (MMCA), an LMM that achieves state-of-the-art performance on existing chart QA benchmarks. Recognizing the need for a comprehensive evaluation of LMM chart understanding, we also propose a MultiModal Chart Benchmark (MMC-Benchmark), a comprehensive human-annotated benchmark with 9 distinct tasks evaluating reasoning capabilities over charts. Extensive experiments on MMC-Benchmark reveal the limitations of existing LMMs on correctly interpreting charts, even for the most recent GPT-4V model. Our work provides an instruction-tuning methodology and benchmark to advance multimodal understanding of charts.
HallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V, LLaVA-1.5, and Other Multi-modality Models
Oct 23, 2023



Large language models (LLMs), after being aligned with vision models and integrated into vision-language models (VLMs), can bring impressive improvement in image reasoning tasks. This was shown by the recently released GPT-4V(ison), LLaVA-1.5, etc. However, the strong language prior in these SOTA LVLMs can be a double-edged sword: they may ignore the image context and solely rely on the (even contradictory) language prior for reasoning. In contrast, the vision modules in VLMs are weaker than LLMs and may result in misleading visual representations, which are then translated to confident mistakes by LLMs. To study these two types of VLM mistakes, i.e., language hallucination and visual illusion, we curated HallusionBench, an image-context reasoning benchmark that is still challenging to even GPT-4V and LLaVA-1.5. We provide a detailed analysis of examples in HallusionBench, which sheds novel insights on the illusion or hallucination of VLMs and how to improve them in the future. The benchmark and codebase will be released at https://github.com/tianyi-lab/HallusionBench.
Aligning Large Multi-Modal Model with Robust Instruction Tuning
Jun 26, 2023Despite the promising progress in multi-modal tasks, current large multi-modal models (LMM) are prone to hallucinating inconsistent descriptions with respect to the associated image and human instructions. This paper addresses this issue by introducing the first large and diverse visual instruction tuning dataset, named Large-scale Robust Visual (LRV)-Instruction. Our dataset consists of 120k visual instructions generated by GPT4, covering 16 vision-and-language tasks with open-ended instructions and answers. Unlike existing studies that primarily focus on positive instruction samples, we design LRV-Instruction to include both positive and negative instructions for more robust visual instruction tuning. Our negative instructions are designed at two semantic levels: (i) Nonexistent Element Manipulation and (ii) Existent Element Manipulation. To efficiently measure the hallucination generated by LMMs, we propose GPT4-Assisted Visual Instruction Evaluation (GAVIE), a novel approach to evaluate visual instruction tuning without the need for human-annotated groundtruth answers and can adapt to diverse instruction formats. We conduct comprehensive experiments to investigate the hallucination of LMMs. Our results demonstrate that existing LMMs exhibit significant hallucination when presented with our negative instructions, particularly with Existent Element Manipulation instructions. Moreover, by finetuning MiniGPT4 on LRV-Instruction, we successfully mitigate hallucination while improving performance on public datasets using less training data compared to state-of-the-art methods. Additionally, we observed that a balanced ratio of positive and negative instances in the training data leads to a more robust model. Our project link is available at https://fuxiaoliu.github.io/LRV/.
COVID-VTS: Fact Extraction and Verification on Short Video Platforms
Feb 15, 2023



We introduce a new benchmark, COVID-VTS, for fact-checking multi-modal information involving short-duration videos with COVID19- focused information from both the real world and machine generation. We propose, TwtrDetective, an effective model incorporating cross-media consistency checking to detect token-level malicious tampering in different modalities, and generate explanations. Due to the scarcity of training data, we also develop an efficient and scalable approach to automatically generate misleading video posts by event manipulation or adversarial matching. We investigate several state-of-the-art models and demonstrate the superiority of TwtrDetective.
One-Shot Face Video Re-enactment using Hybrid Latent Spaces of StyleGAN2
Feb 15, 2023



While recent research has progressively overcome the low-resolution constraint of one-shot face video re-enactment with the help of StyleGAN's high-fidelity portrait generation, these approaches rely on at least one of the following: explicit 2D/3D priors, optical flow based warping as motion descriptors, off-the-shelf encoders, etc., which constrain their performance (e.g., inconsistent predictions, inability to capture fine facial details and accessories, poor generalization, artifacts). We propose an end-to-end framework for simultaneously supporting face attribute edits, facial motions and deformations, and facial identity control for video generation. It employs a hybrid latent-space that encodes a given frame into a pair of latents: Identity latent, $\mathcal{W}_{ID}$, and Facial deformation latent, $\mathcal{S}_F$, that respectively reside in the $W+$ and $SS$ spaces of StyleGAN2. Thereby, incorporating the impressive editability-distortion trade-off of $W+$ and the high disentanglement properties of $SS$. These hybrid latents employ the StyleGAN2 generator to achieve high-fidelity face video re-enactment at $1024^2$. Furthermore, the model supports the generation of realistic re-enactment videos with other latent-based semantic edits (e.g., beard, age, make-up, etc.). Qualitative and quantitative analyses performed against state-of-the-art methods demonstrate the superiority of the proposed approach.
Encode-in-Style: Latent-based Video Encoding using StyleGAN2
Mar 28, 2022We propose an end-to-end facial video encoding approach that facilitates data-efficient high-quality video re-synthesis by optimizing low-dimensional edits of a single Identity-latent. The approach builds on StyleGAN2 image inversion and multi-stage non-linear latent-space editing to generate videos that are nearly comparable to input videos. It economically captures face identity, head-pose, and complex facial motions at fine levels, and thereby bypasses training and person modeling which tend to hamper many re-synthesis approaches. The approach is designed with maximum data efficiency, where a single W+ latent and 35 parameters per frame enable high-fidelity video rendering. This pipeline can also be used for puppeteering (i.e., motion transfer).
Label Denoising Adversarial Network (LDAN) for Inverse Lighting of Face Images
Sep 06, 2017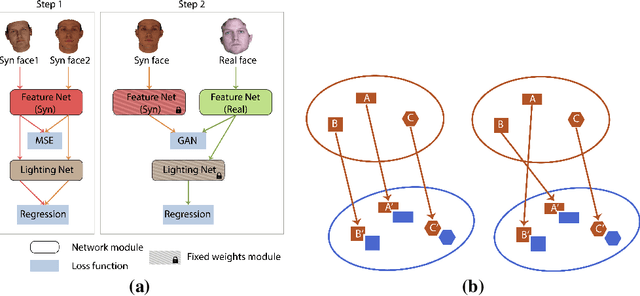

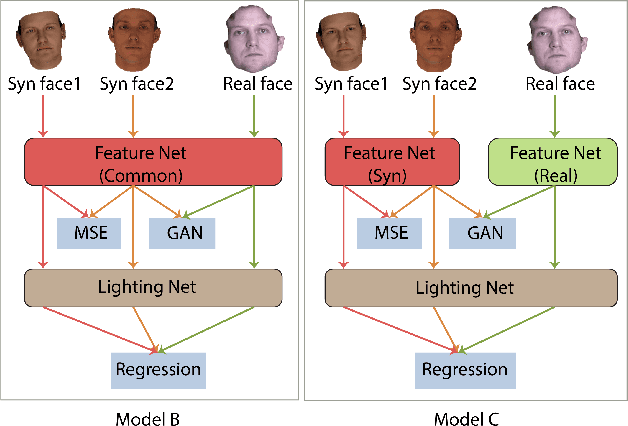

Lighting estimation from face images is an important task and has applications in many areas such as image editing, intrinsic image decomposition, and image forgery detection. We propose to train a deep Convolutional Neural Network (CNN) to regress lighting parameters from a single face image. Lacking massive ground truth lighting labels for face images in the wild, we use an existing method to estimate lighting parameters, which are treated as ground truth with unknown noises. To alleviate the effect of such noises, we utilize the idea of Generative Adversarial Networks (GAN) and propose a Label Denoising Adversarial Network (LDAN) to make use of synthetic data with accurate ground truth to help train a deep CNN for lighting regression on real face images. Experiments show that our network outperforms existing methods in producing consistent lighting parameters of different faces under similar lighting conditions. Moreover, our method is 100,000 times faster in execution time than prior optimization-based lighting estimation approaches.