 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAD-GS: Object-Aware B-Spline Gaussian Splatting for Self-Supervised Autonomous Driving
Jul 16, 2025Modeling and rendering dynamic urban driving scenes is crucial for self-driving simulation. Current high-quality methods typically rely on costly manual object tracklet annotations, while self-supervised approaches fail to capture dynamic object motions accurately and decompose scenes properly, resulting in rendering artifacts. We introduce AD-GS, a novel self-supervised framework for high-quality free-viewpoint rendering of driving scenes from a single log. At its core is a novel learnable motion model that integrates locality-aware B-spline curves with global-aware trigonometric functions, enabling flexible yet precise dynamic object modeling. Rather than requiring comprehensive semantic labeling, AD-GS automatically segments scenes into objects and background with the simplified pseudo 2D segmentation, representing objects using dynamic Gaussians and bidirectional temporal visibility masks. Further, our model incorporates visibility reasoning and physically rigid regularization to enhance robustness. Extensive evaluations demonstrate that our annotation-free model significantly outperforms current state-of-the-art annotation-free methods and is competitive with annotation-dependent approaches.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
Representation Entanglement for Generation:Training Diffusion Transformers Is Much Easier Than You Think
Jul 02, 2025
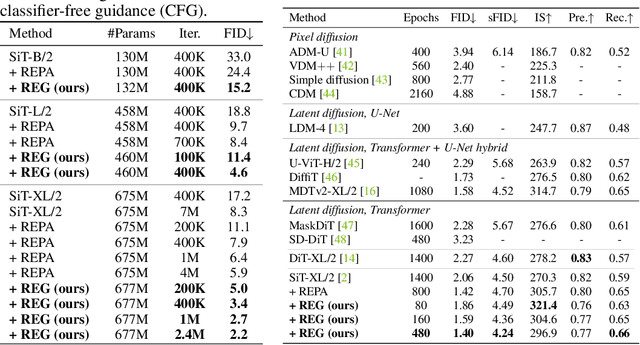
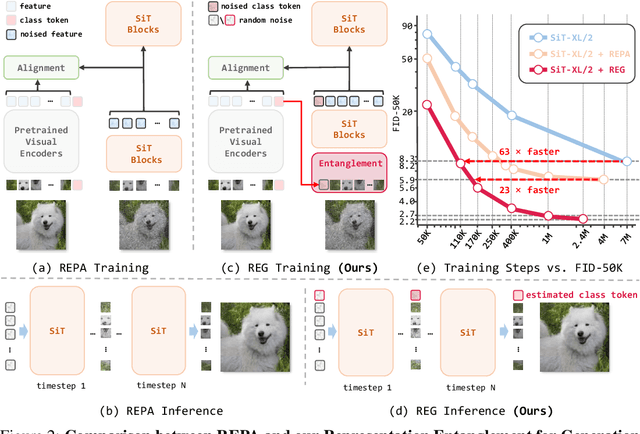
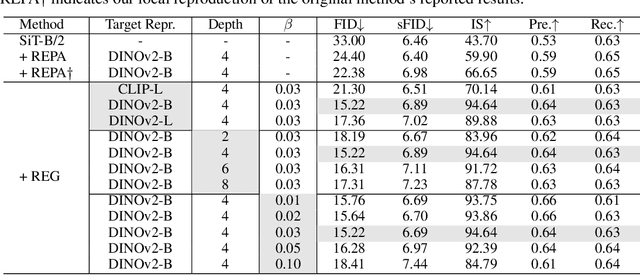
REPA and its variants effectively mitigate training challenges in diffusion models by incorporating external visual representations from pretrained models, through alignment between the noisy hidden projections of denoising networks and foundational clean image representations. We argue that the external alignment, which is absent during the entire denoising inference process, falls short of fully harnessing the potential of discriminative representations. In this work, we propose a straightforward method called Representation Entanglement for Generation (REG), which entangles low-level image latents with a single high-level class token from pretrained foundation models for denoising. REG acquires the capability to produce coherent image-class pairs directly from pure noise, substantially improving both generation quality and training efficiency. This is accomplished with negligible additional inference overhead, requiring only one single additional token for denoising (<0.5\% increase in FLOPs and latency). The inference process concurrently reconstructs both image latents and their corresponding global semantics, where the acquired semantic knowledge actively guides and enhances the image generation process. On ImageNet 256$\times$256, SiT-XL/2 + REG demonstrates remarkable convergence acceleration, achieving $\textbf{63}\times$ and $\textbf{23}\times$ faster training than SiT-XL/2 and SiT-XL/2 + REPA, respectively. More impressively, SiT-L/2 + REG trained for merely 400K iterations outperforms SiT-XL/2 + REPA trained for 4M iterations ($\textbf{10}\times$ longer). Code is available at: https://github.com/Martinser/REG.
FADPNet: Frequency-Aware Dual-Path Network for Face Super-Resolution
Jun 17, 2025Face super-resolution (FSR) under limited computational costs remains an open problem. Existing approaches typically treat all facial pixels equally, resulting in suboptimal allocation of computational resources and degraded FSR performance. CNN is relatively sensitive to high-frequency facial features, such as component contours and facial outlines. Meanwhile, Mamba excels at capturing low-frequency features like facial color and fine-grained texture, and does so with lower complexity than Transformers. Motivated by these observations, we propose FADPNet, a Frequency-Aware Dual-Path Network that decomposes facial features into low- and high-frequency components and processes them via dedicated branches. For low-frequency regions, we introduce a Mamba-based Low-Frequency Enhancement Block (LFEB), which combines state-space attention with squeeze-and-excitation operations to extract low-frequency global interactions and emphasize informative channels. For high-frequency regions, we design a CNN-based Deep Position-Aware Attention (DPA) module to enhance spatially-dependent structural details, complemented by a lightweight High-Frequency Refinement (HFR) module that further refines frequency-specific representations. Through the above designs, our method achieves an excellent balance between FSR quality and model efficiency, outperforming existing approaches.
Scaling Test-time Compute for LLM Agents
Jun 15, 2025Scaling test time compute has shown remarkable success in improving the reasoning abilities of large language models (LLMs). In this work, we conduct the first systematic exploration of applying test-time scaling methods to language agents and investigate the extent to which it improves their effectiveness. Specifically, we explore different test-time scaling strategies, including: (1) parallel sampling algorithms; (2) sequential revision strategies; (3) verifiers and merging methods; (4)strategies for diversifying rollouts.We carefully analyze and ablate the impact of different design strategies on applying test-time scaling on language agents, and have follow findings: 1. Scaling test time compute could improve the performance of agents. 2. Knowing when to reflect is important for agents. 3. Among different verification and result merging approaches, the list-wise method performs best. 4. Increasing diversified rollouts exerts a positive effect on the agent's task performance.
SWE-Flow: Synthesizing Software Engineering Data in a Test-Driven Manner
Jun 11, 2025We introduce **SWE-Flow**, a novel data synthesis framework grounded in Test-Driven Development (TDD). Unlike existing software engineering data that rely on human-submitted issues, **SWE-Flow** automatically infers incremental development steps directly from unit tests, which inherently encapsulate high-level requirements. The core of **SWE-Flow** is the construction of a Runtime Dependency Graph (RDG), which precisely captures function interactions, enabling the generation of a structured, step-by-step *development schedule*. At each step, **SWE-Flow** produces a partial codebase, the corresponding unit tests, and the necessary code modifications, resulting in fully verifiable TDD tasks. With this approach, we generated 16,061 training instances and 2,020 test instances from real-world GitHub projects, creating the **SWE-Flow-Eval** benchmark. Our experiments show that fine-tuning open model on this dataset significantly improves performance in TDD-based coding. To facilitate further research, we release all code, datasets, models, and Docker images at [Github](https://github.com/Hambaobao/SWE-Flow).
TaskCraft: Automated Generation of Agentic Tasks
Jun 11, 2025Agentic tasks, which require multi-step problem solving with autonomy, tool use, and adaptive reasoning, are becoming increasingly central to the advancement of NLP and AI. However, existing instruction data lacks tool interaction, and current agentic benchmarks rely on costly human annotation, limiting their scalability. We introduce \textsc{TaskCraft}, an automated workflow for generating difficulty-scalable, multi-tool, and verifiable agentic tasks with execution trajectories. TaskCraft expands atomic tasks using depth-based and width-based extensions to create structurally and hierarchically complex challenges. Empirical results show that these tasks improve prompt optimization in the generation workflow and enhance supervised fine-tuning of agentic foundation models. We present a large-scale synthetic dataset of approximately 36,000 tasks with varying difficulty to support future research on agent tuning and evaluation.
VoxelSplat: Dynamic Gaussian Splatting as an Effective Loss for Occupancy and Flow Prediction
Jun 05, 2025Recent advancements in camera-based occupancy prediction have focused on the simultaneous prediction of 3D semantics and scene flow, a task that presents significant challenges due to specific difficulties, e.g., occlusions and unbalanced dynamic environments. In this paper, we analyze these challenges and their underlying causes. To address them, we propose a novel regularization framework called VoxelSplat. This framework leverages recent developments in 3D Gaussian Splatting to enhance model performance in two key ways: (i) Enhanced Semantics Supervision through 2D Projection: During training, our method decodes sparse semantic 3D Gaussians from 3D representations and projects them onto the 2D camera view. This provides additional supervision signals in the camera-visible space, allowing 2D labels to improve the learning of 3D semantics. (ii) Scene Flow Learning: Our framework uses the predicted scene flow to model the motion of Gaussians, and is thus able to learn the scene flow of moving objects in a self-supervised manner using the labels of adjacent frames. Our method can be seamlessly integrated into various existing occupancy models, enhancing performance without increasing inference time. Extensive experiments on benchmark datasets demonstrate the effectiveness of VoxelSplat in improving the accuracy of both semantic occupancy and scene flow estimation. The project page and codes are available at https://zzy816.github.io/VoxelSplat-Demo/.
AliTok: Towards Sequence Modeling Alignment between Tokenizer and Autoregressive Model
Jun 05, 2025Autoregressive image generation aims to predict the next token based on previous ones. However, existing image tokenizers encode tokens with bidirectional dependencies during the compression process, which hinders the effective modeling by autoregressive models. In this paper, we propose a novel Aligned Tokenizer (AliTok), which utilizes a causal decoder to establish unidirectional dependencies among encoded tokens, thereby aligning the token modeling approach between the tokenizer and autoregressive model. Furthermore, by incorporating prefix tokens and employing two-stage tokenizer training to enhance reconstruction consistency, AliTok achieves great reconstruction performance while being generation-friendly. On ImageNet-256 benchmark, using a standard decoder-only autoregressive model as the generator with only 177M parameters, AliTok achieves a gFID score of 1.50 and an IS of 305.9. When the parameter count is increased to 662M, AliTok achieves a gFID score of 1.35, surpassing the state-of-the-art diffusion method with 10x faster sampling speed. The code and weights are available at https://github.com/ali-vilab/alitok.
One-Way Ticket:Time-Independent Unified Encoder for Distilling Text-to-Image Diffusion Models
May 28, 2025Text-to-Image (T2I) diffusion models have made remarkable advancements in generative modeling; however, they face a trade-off between inference speed and image quality, posing challenges for efficient deployment. Existing distilled T2I models can generate high-fidelity images with fewer sampling steps, but often struggle with diversity and quality, especially in one-step models. From our analysis, we observe redundant computations in the UNet encoders. Our findings suggest that, for T2I diffusion models, decoders are more adept at capturing richer and more explicit semantic information, while encoders can be effectively shared across decoders from diverse time steps. Based on these observations, we introduce the first Time-independent Unified Encoder TiUE for the student model UNet architecture, which is a loop-free image generation approach for distilling T2I diffusion models. Using a one-pass scheme, TiUE shares encoder features across multiple decoder time steps, enabling parallel sampling and significantly reducing inference time complexity. In addition, we incorporate a KL divergence term to regularize noise prediction, which enhances the perceptual realism and diversity of the generated images. Experimental results demonstrate that TiUE outperforms state-of-the-art methods, including LCM, SD-Turbo, and SwiftBrushv2, producing more diverse and realistic results while maintaining the computational efficiency.