 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Hallucination in Financial Retrieval-Augmented Generation via Fine-Grained Knowledge Verification
Feb 05, 2026In financial Retrieval-Augmented Generation (RAG) systems, models frequently rely on retrieved documents to generate accurate responses due to the time-sensitive nature of the financial domain. While retrieved documents help address knowledge gaps, model-generated responses still suffer from hallucinations that contradict the retrieved information. To mitigate this inconsistency, we propose a Reinforcement Learning framework enhanced with Fine-grained Knowledge Verification (RLFKV). Our method decomposes financial responses into atomic knowledge units and assesses the correctness of each unit to compute the fine-grained faithful reward. This reward offers more precise optimization signals, thereby improving alignment with the retrieved documents. Additionally, to prevent reward hacking (e.g., overly concise replies), we incorporate an informativeness reward that encourages the policy model to retain at least as many knowledge units as the base model. Experiments conducted on the public Financial Data Description (FDD) task and our newly proposed FDD-ANT dataset demonstrate consistent improvements, confirming the effectiveness of our approach.
VGGT-Long: Chunk it, Loop it, Align it -- Pushing VGGT's Limits on Kilometer-scale Long RGB Sequences
Jul 22, 2025Foundation models for 3D vision have recently demonstrated remarkable capabilities in 3D perception. However, extending these models to large-scale RGB stream 3D reconstruction remains challenging due to memory limitations. In this work, we propose VGGT-Long, a simple yet effective system that pushes the limits of monocular 3D reconstruction to kilometer-scale, unbounded outdoor environments. Our approach addresses the scalability bottlenecks of existing models through a chunk-based processing strategy combined with overlapping alignment and lightweight loop closure optimization. Without requiring camera calibration, depth supervision or model retraining, VGGT-Long achieves trajectory and reconstruction performance comparable to traditional methods. We evaluate our method on KITTI, Waymo, and Virtual KITTI datasets. VGGT-Long not only runs successfully on long RGB sequences where foundation models typically fail, but also produces accurate and consistent geometry across various conditions. Our results highlight the potential of leveraging foundation models for scalable monocular 3D scene in real-world settings, especially for autonomous driving scenarios. Code is available at https://github.com/DengKaiCQ/VGGT-Long.
AD-GS: Object-Aware B-Spline Gaussian Splatting for Self-Supervised Autonomous Driving
Jul 16, 2025Modeling and rendering dynamic urban driving scenes is crucial for self-driving simulation. Current high-quality methods typically rely on costly manual object tracklet annotations, while self-supervised approaches fail to capture dynamic object motions accurately and decompose scenes properly, resulting in rendering artifacts. We introduce AD-GS, a novel self-supervised framework for high-quality free-viewpoint rendering of driving scenes from a single log. At its core is a novel learnable motion model that integrates locality-aware B-spline curves with global-aware trigonometric functions, enabling flexible yet precise dynamic object modeling. Rather than requiring comprehensive semantic labeling, AD-GS automatically segments scenes into objects and background with the simplified pseudo 2D segmentation, representing objects using dynamic Gaussians and bidirectional temporal visibility masks. Further, our model incorporates visibility reasoning and physically rigid regularization to enhance robustness. Extensive evaluations demonstrate that our annotation-free model significantly outperforms current state-of-the-art annotation-free methods and is competitive with annotation-dependent approaches.
GigaSLAM: Large-Scale Monocular SLAM with Hierachical Gaussian Splats
Mar 11, 2025Tracking and mapping in large-scale, unbounded outdoor environments using only monocular RGB input presents substantial challenges for existing SLAM systems. Traditional Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) SLAM methods are typically limited to small, bounded indoor settings. To overcome these challenges, we introduce GigaSLAM, the first NeRF/3DGS-based SLAM framework for kilometer-scale outdoor environments, as demonstrated on the KITTI and KITTI 360 datasets. Our approach employs a hierarchical sparse voxel map representation, where Gaussians are decoded by neural networks at multiple levels of detail. This design enables efficient, scalable mapping and high-fidelity viewpoint rendering across expansive, unbounded scenes. For front-end tracking, GigaSLAM utilizes a metric depth model combined with epipolar geometry and PnP algorithms to accurately estimate poses, while incorporating a Bag-of-Words-based loop closure mechanism to maintain robust alignment over long trajectories. Consequently, GigaSLAM delivers high-precision tracking and visually faithful rendering on urban outdoor benchmarks, establishing a robust SLAM solution for large-scale, long-term scenarios, and significantly extending the applicability of Gaussian Splatting SLAM systems to unbounded outdoor environments.
DECO: Life-Cycle Management of Enterprise-Grade Chatbots
Dec 08, 2024



Software engineers frequently grapple with the challenge of accessing disparate documentation and telemetry data, including Troubleshooting Guides (TSGs), incident reports, code repositories, and various internal tools developed by multiple stakeholders. While on-call duties are inevitable, incident resolution becomes even more daunting due to the obscurity of legacy sources and the pressures of strict time constraints. To enhance the efficiency of on-call engineers (OCEs) and streamline their daily workflows, we introduced DECO -- a comprehensive framework for developing, deploying, and managing enterprise-grade chatbots tailored to improve productivity in engineering routines. This paper details the design and implementation of the DECO framework, emphasizing its innovative NL2SearchQuery functionality and a hierarchical planner. These features support efficient and customized retrieval-augmented-generation (RAG) algorithms that not only extract relevant information from diverse sources but also select the most pertinent toolkits in response to user queries. This enables the addressing of complex technical questions and provides seamless, automated access to internal resources. Additionally, DECO incorporates a robust mechanism for converting unstructured incident logs into user-friendly, structured guides, effectively bridging the documentation gap. Feedback from users underscores DECO's pivotal role in simplifying complex engineering tasks, accelerating incident resolution, and bolstering organizational productivity. Since its launch in September 2023, DECO has demonstrated its effectiveness through extensive engagement, with tens of thousands of interactions from hundreds of active users across multiple organizations within the company.
Learning Heatmap-Style Jigsaw Puzzles Provides Good Pretraining for 2D Human Pose Estimation
Dec 13, 2020
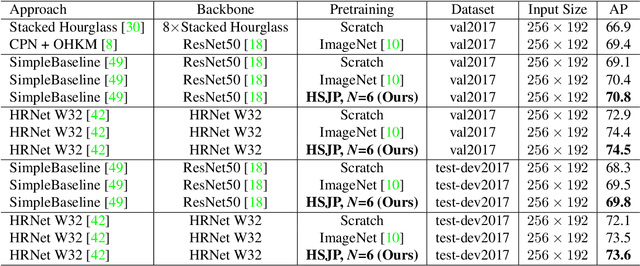

The target of 2D human pose estimation is to locate the keypoints of body parts from input 2D images. State-of-the-art methods for pose estimation usually construct pixel-wise heatmaps from keypoints as labels for learning convolution neural networks, which are usually initialized randomly or using classification models on ImageNet as their backbones. We note that 2D pose estimation task is highly dependent on the contextual relationship between image patches, thus we introduce a self-supervised method for pretraining 2D pose estimation networks. Specifically, we propose Heatmap-Style Jigsaw Puzzles (HSJP) problem as our pretext-task, whose target is to learn the location of each patch from an image composed of shuffled patches. During our pretraining process, we only use images of person instances in MS-COCO, rather than introducing extra and much larger ImageNet dataset. A heatmap-style label for patch location is designed and our learning process is in a non-contrastive way. The weights learned by HSJP pretext task are utilised as backbones of 2D human pose estimator, which are then finetuned on MS-COCO human keypoints dataset. With two popular and strong 2D human pose estimators, HRNet and SimpleBaseline, we evaluate mAP score on both MS-COCO validation and test-dev datasets. Our experiments show that downstream pose estimators with our self-supervised pretraining obtain much better performance than those trained from scratch, and are comparable to those using ImageNet classification models as their initial backbones.