 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXnODR and XnIDR: Two Accurate and Fast Fully Connected Layers For Convolutional Neural Networks
Nov 21, 2021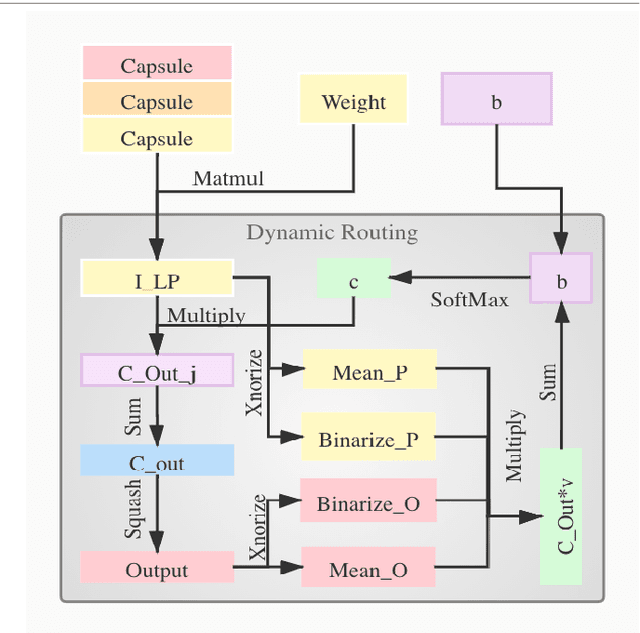
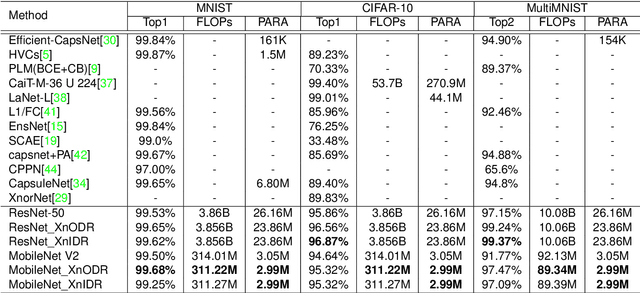
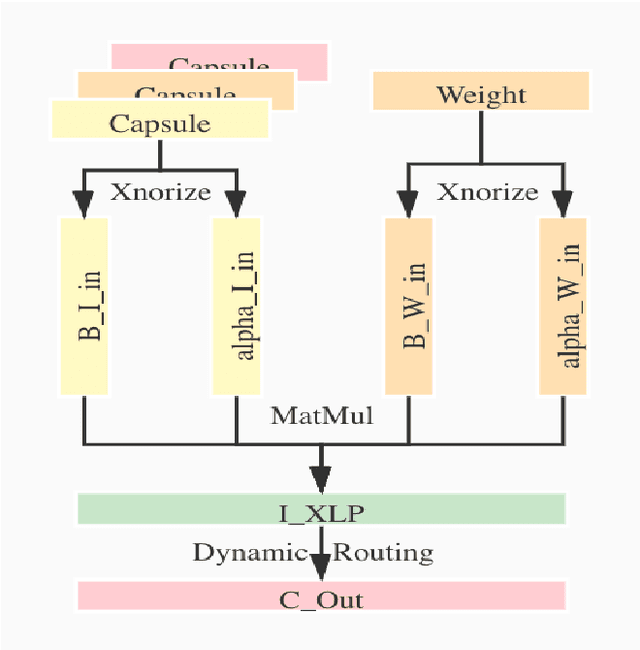
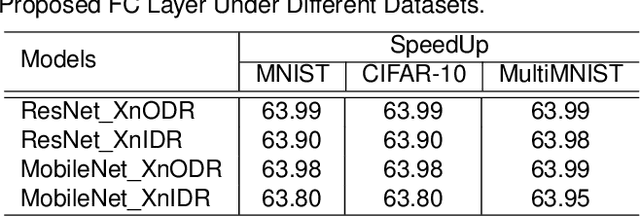
Although Capsule Networks show great abilities in defining the position relationship between features in deep neural networks for visual recognition tasks, they are computationally expensive and not suitable for running on mobile devices. The bottleneck is in the computational complexity of the Dynamic Routing mechanism used between capsules. On the other hand, neural networks such as XNOR-Net are fast and computationally efficient but have relatively low accuracy because of their information loss in the binarization process. This paper proposes a new class of Fully Connected (FC) Layers by xnorizing the linear projector outside or inside the Dynamic Routing within the CapsFC layer. Specifically, our proposed FC layers have two versions, XnODR (Xnorizing Linear Projector Outside Dynamic Routing) and XnIDR (Xnorizing Linear Projector Inside Dynamic Routing). To test their generalization, we insert them into MobileNet V2 and ResNet-50 separately. Experiments on three datasets, MNIST, CIFAR-10, MultiMNIST validate their effectiveness. Our experimental results demonstrate that both XnODR and XnIDR help networks to have high accuracy with lower FLOPs and fewer parameters (e.g., 95.32\% accuracy with 2.99M parameters and 311.22M FLOPs on CIFAR-10).
SDCUP: Schema Dependency-Enhanced Curriculum Pre-Training for Table Semantic Parsing
Nov 18, 2021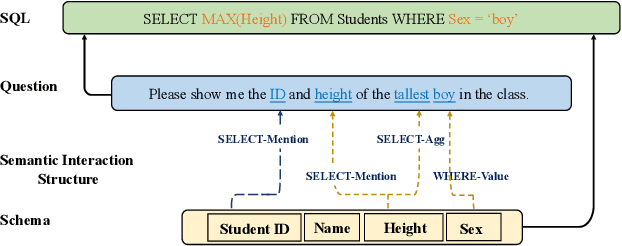
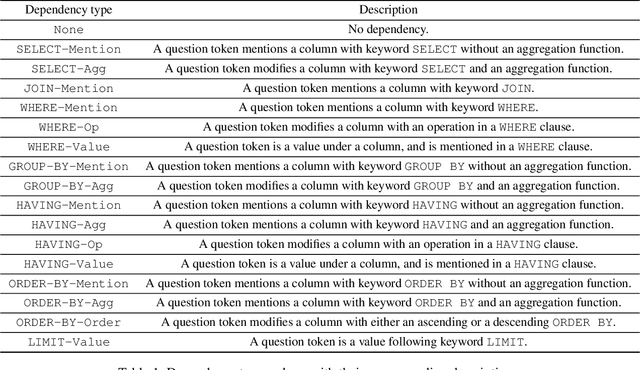
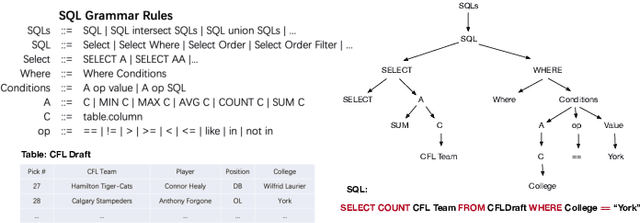

Recently pre-training models have significantly improved the performance of various NLP tasks by leveraging large-scale text corpora to improve the contextual representation ability of the neural network. The large pre-training language model has also been applied in the area of table semantic parsing. However, existing pre-training approaches have not carefully explored explicit interaction relationships between a question and the corresponding database schema, which is a key ingredient for uncovering their semantic and structural correspondence. Furthermore, the question-aware representation learning in the schema grounding context has received less attention in pre-training objective.To alleviate these issues, this paper designs two novel pre-training objectives to impose the desired inductive bias into the learned representations for table pre-training. We further propose a schema-aware curriculum learning approach to mitigate the impact of noise and learn effectively from the pre-training data in an easy-to-hard manner. We evaluate our pre-trained framework by fine-tuning it on two benchmarks, Spider and SQUALL. The results demonstrate the effectiveness of our pre-training objective and curriculum compared to a variety of baselines.
Distributed stochastic proximal algorithm with random reshuffling for non-smooth finite-sum optimization
Nov 06, 2021
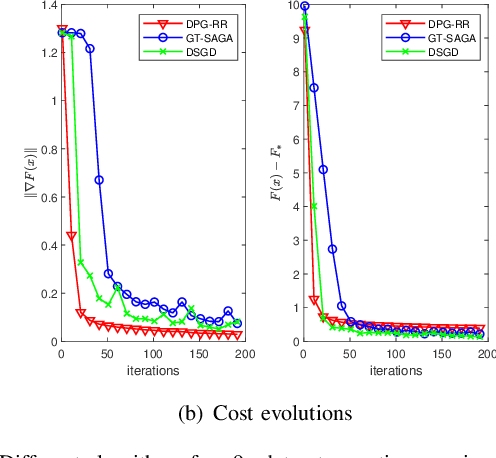
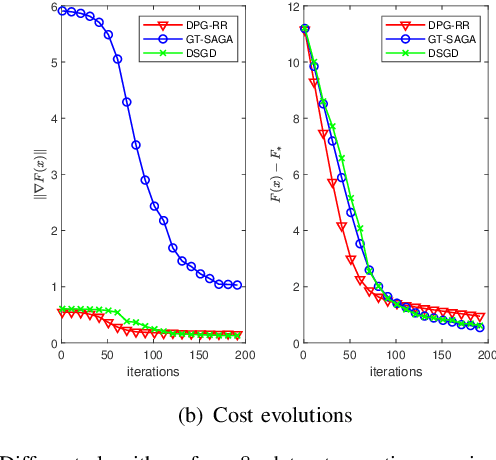
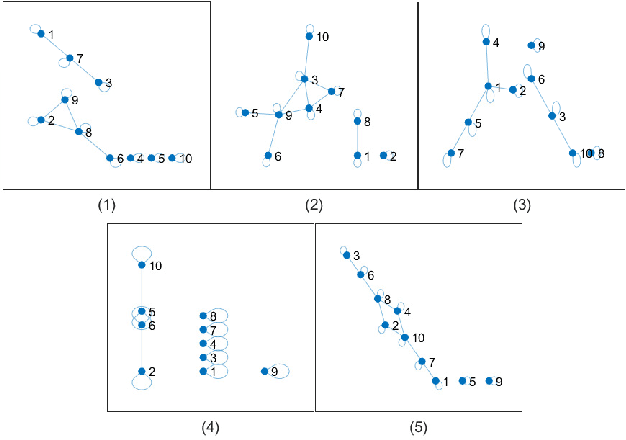
The non-smooth finite-sum minimization is a fundamental problem in machine learning. This paper develops a distributed stochastic proximal-gradient algorithm with random reshuffling to solve the finite-sum minimization over time-varying multi-agent networks. The objective function is a sum of differentiable convex functions and non-smooth regularization. Each agent in the network updates local variables with a constant step-size by local information and cooperates to seek an optimal solution. We prove that local variable estimates generated by the proposed algorithm achieve consensus and are attracted to a neighborhood of the optimal solution in expectation with an $\mathcal{O}(\frac{1}{T}+\frac{1}{\sqrt{T}})$ convergence rate. In addition, this paper shows that the steady-state error of the objective function can be arbitrarily small by choosing small enough step-sizes. Finally, some comparative simulations are provided to verify the convergence performance of the proposed algorithm.
Path-Enhanced Multi-Relational Question Answering with Knowledge Graph Embeddings
Oct 29, 2021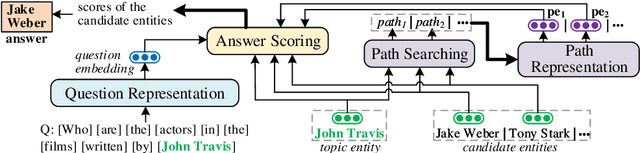
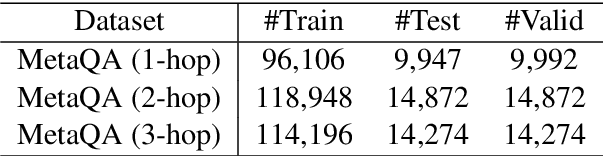

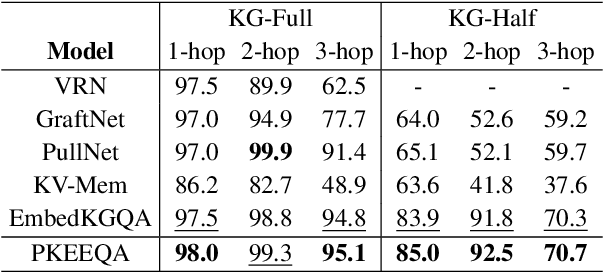
The multi-relational Knowledge Base Question Answering (KBQA) system performs multi-hop reasoning over the knowledge graph (KG) to achieve the answer. Recent approaches attempt to introduce the knowledge graph embedding (KGE) technique to handle the KG incompleteness but only consider the triple facts and neglect the significant semantic correlation between paths and multi-relational questions. In this paper, we propose a Path and Knowledge Embedding-Enhanced multi-relational Question Answering model (PKEEQA), which leverages multi-hop paths between entities in the KG to evaluate the ambipolar correlation between a path embedding and a multi-relational question embedding via a customizable path representation mechanism, benefiting for achieving more accurate answers from the perspective of both the triple facts and the extra paths. Experimental results illustrate that PKEEQA improves KBQA models' performance for multi-relational question answering with explainability to some extent derived from paths.
Instance-Conditional Knowledge Distillation for Object Detection
Oct 25, 2021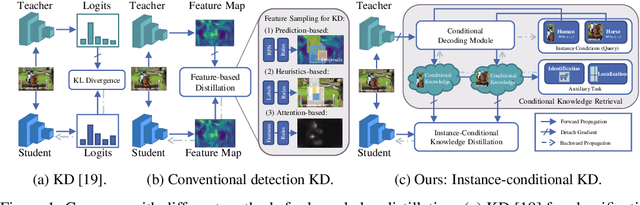
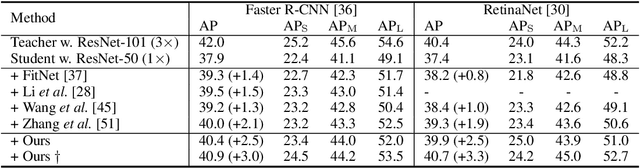
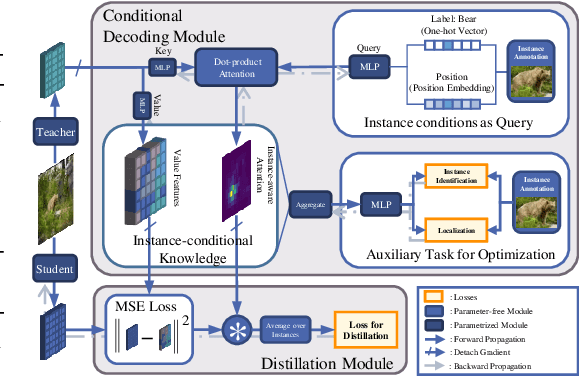
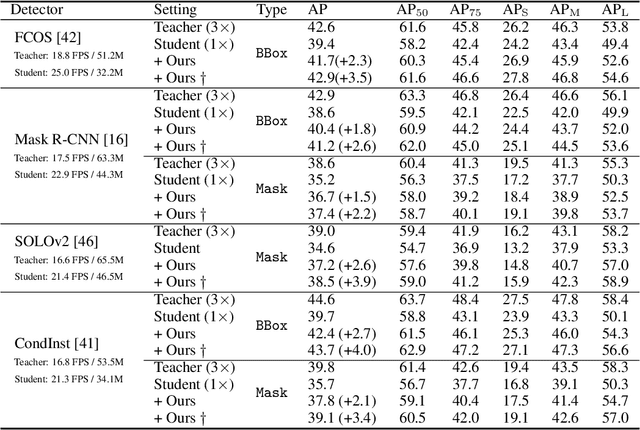
Despite the success of Knowledge Distillation (KD) on image classification, it is still challenging to apply KD on object detection due to the difficulty in locating knowledge. In this paper, we propose an instance-conditional distillation framework to find desired knowledge. To locate knowledge of each instance, we use observed instances as condition information and formulate the retrieval process as an instance-conditional decoding process. Specifically, information of each instance that specifies a condition is encoded as query, and teacher's information is presented as key, we use the attention between query and key to measure the correlation, formulated by the transformer decoder. To guide this module, we further introduce an auxiliary task that directs to instance localization and identification, which are fundamental for detection. Extensive experiments demonstrate the efficacy of our method: we observe impressive improvements under various settings. Notably, we boost RetinaNet with ResNet-50 backbone from 37.4 to 40.7 mAP (+3.3) under 1x schedule, that even surpasses the teacher (40.4 mAP) with ResNet-101 backbone under 3x schedule. Code will be released soon.
DialogueCSE: Dialogue-based Contrastive Learning of Sentence Embeddings
Sep 26, 2021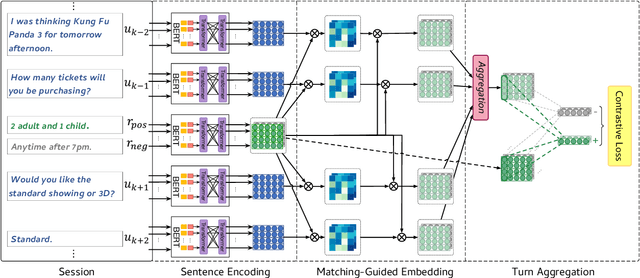
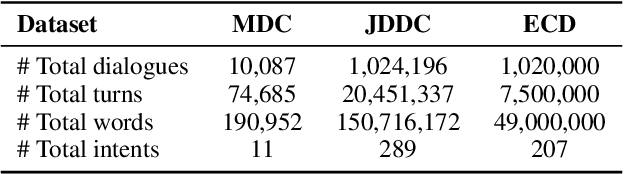
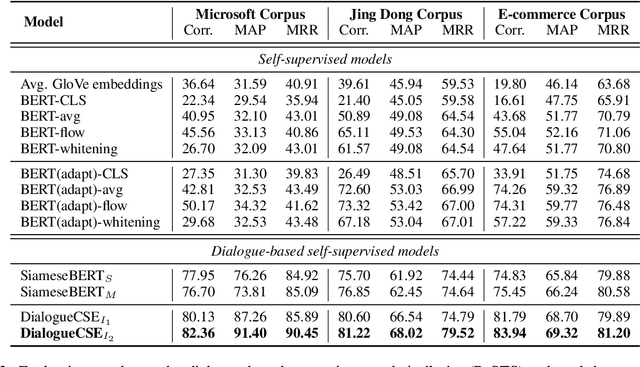
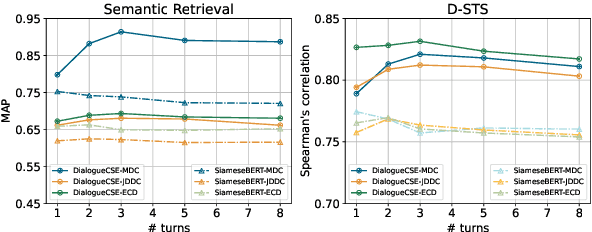
Learning sentence embeddings from dialogues has drawn increasing attention due to its low annotation cost and high domain adaptability. Conventional approaches employ the siamese-network for this task, which obtains the sentence embeddings through modeling the context-response semantic relevance by applying a feed-forward network on top of the sentence encoders. However, as the semantic textual similarity is commonly measured through the element-wise distance metrics (e.g. cosine and L2 distance), such architecture yields a large gap between training and evaluating. In this paper, we propose DialogueCSE, a dialogue-based contrastive learning approach to tackle this issue. DialogueCSE first introduces a novel matching-guided embedding (MGE) mechanism, which generates a context-aware embedding for each candidate response embedding (i.e. the context-free embedding) according to the guidance of the multi-turn context-response matching matrices. Then it pairs each context-aware embedding with its corresponding context-free embedding and finally minimizes the contrastive loss across all pairs. We evaluate our model on three multi-turn dialogue datasets: the Microsoft Dialogue Corpus, the Jing Dong Dialogue Corpus, and the E-commerce Dialogue Corpus. Evaluation results show that our approach significantly outperforms the baselines across all three datasets in terms of MAP and Spearman's correlation measures, demonstrating its effectiveness. Further quantitative experiments show that our approach achieves better performance when leveraging more dialogue context and remains robust when less training data is provided.
Partial to Whole Knowledge Distillation: Progressive Distilling Decomposed Knowledge Boosts Student Better
Sep 26, 2021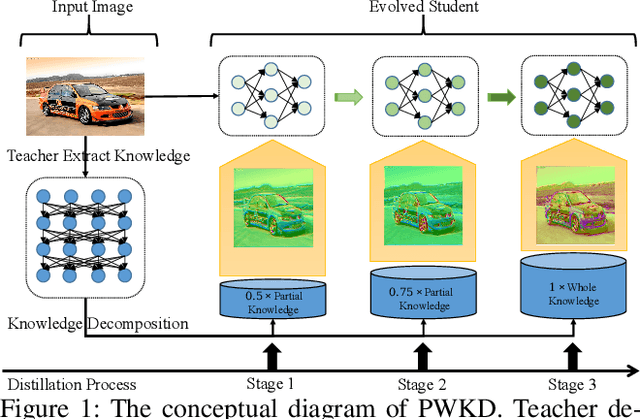
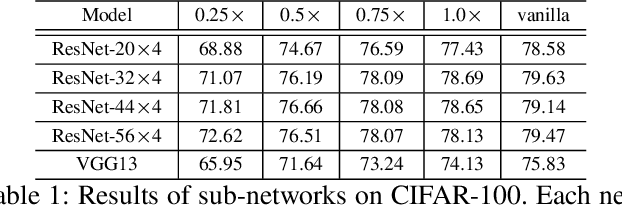
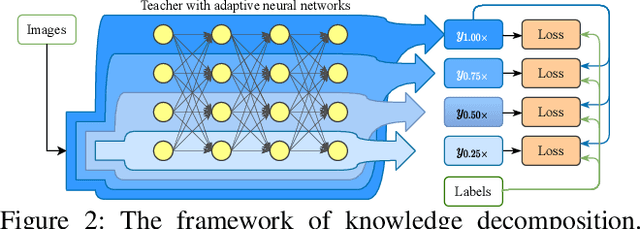
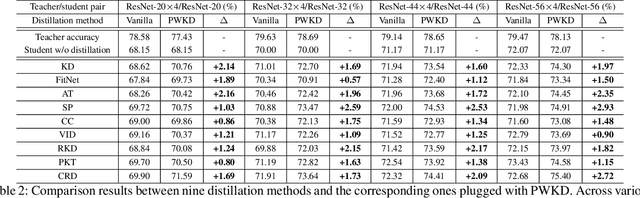
Knowledge distillation field delicately designs various types of knowledge to shrink the performance gap between compact student and large-scale teacher. These existing distillation approaches simply focus on the improvement of \textit{knowledge quality}, but ignore the significant influence of \textit{knowledge quantity} on the distillation procedure. Opposed to the conventional distillation approaches, which extract knowledge from a fixed teacher computation graph, this paper explores a non-negligible research direction from a novel perspective of \textit{knowledge quantity} to further improve the efficacy of knowledge distillation. We introduce a new concept of knowledge decomposition, and further put forward the \textbf{P}artial to \textbf{W}hole \textbf{K}nowledge \textbf{D}istillation~(\textbf{PWKD}) paradigm. Specifically, we reconstruct teacher into weight-sharing sub-networks with same depth but increasing channel width, and train sub-networks jointly to obtain decomposed knowledge~(sub-networks with more channels represent more knowledge). Then, student extract partial to whole knowledge from the pre-trained teacher within multiple training stages where cyclic learning rate is leveraged to accelerate convergence. Generally, \textbf{PWKD} can be regarded as a plugin to be compatible with existing offline knowledge distillation approaches. To verify the effectiveness of \textbf{PWKD}, we conduct experiments on two benchmark datasets:~CIFAR-100 and ImageNet, and comprehensive evaluation results reveal that \textbf{PWKD} consistently improve existing knowledge distillation approaches without bells and whistles.
LGD: Label-guided Self-distillation for Object Detection
Sep 23, 2021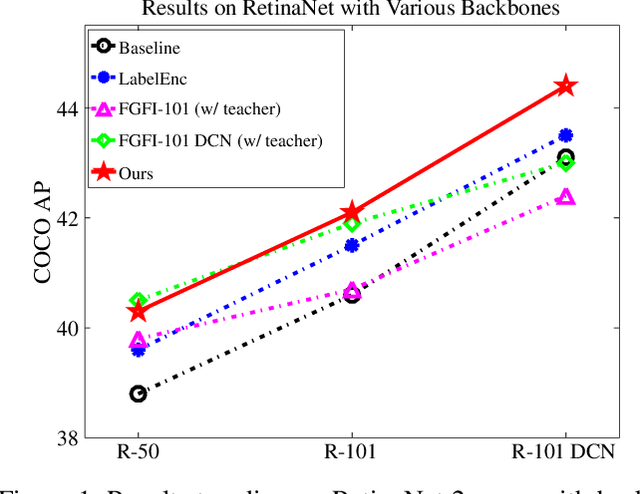
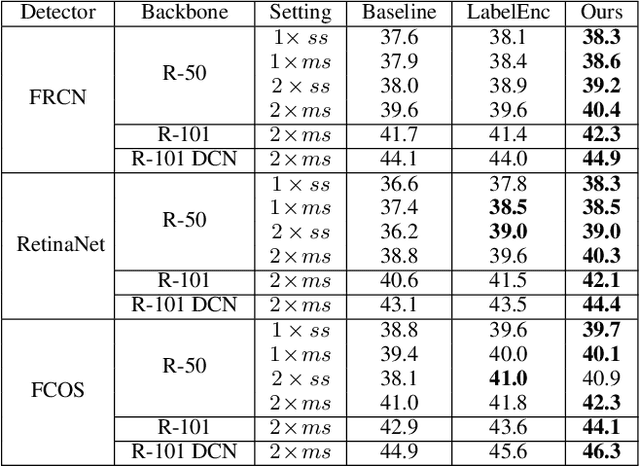
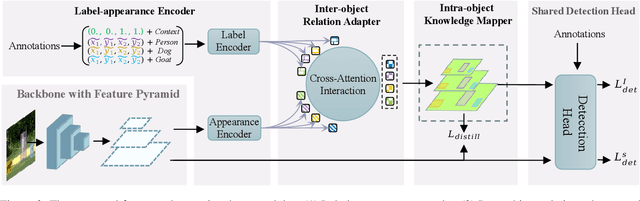
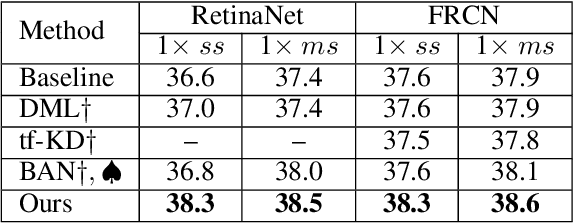
In this paper, we propose the first self-distillation framework for general object detection, termed LGD (Label-Guided self-Distillation). Previous studies rely on a strong pretrained teacher to provide instructive knowledge for distillation. However, this could be unavailable in real-world scenarios. Instead, we generate an instructive knowledge by inter-and-intra relation modeling among objects, requiring only student representations and regular labels. In detail, our framework involves sparse label-appearance encoding, inter-object relation adaptation and intra-object knowledge mapping to obtain the instructive knowledge. Modules in LGD are trained end-to-end with student detector and are discarded in inference. Empirically, LGD obtains decent results on various detectors, datasets, and extensive task like instance segmentation. For example in MS-COCO dataset, LGD improves RetinaNet with ResNet-50 under 2x single-scale training from 36.2% to 39.0% mAP (+ 2.8%). For much stronger detectors like FCOS with ResNeXt-101 DCN v2 under 2x multi-scale training (46.1%), LGD achieves 47.9% (+ 1.8%). For pedestrian detection in CrowdHuman dataset, LGD boosts mMR by 2.3% for Faster R-CNN with ResNet-50. Compared with a classical teacher-based method FGFI, LGD not only performs better without requiring pretrained teacher but also with 51% lower training cost beyond inherent student learning.
Anchor DETR: Query Design for Transformer-Based Detector
Sep 15, 2021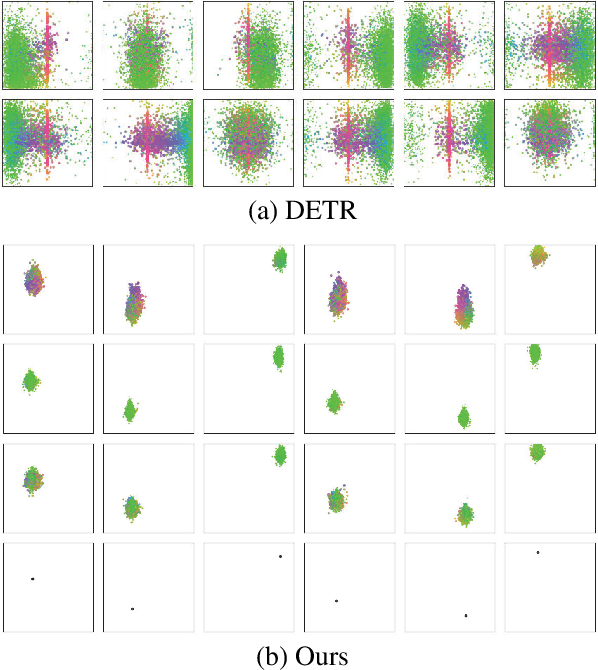

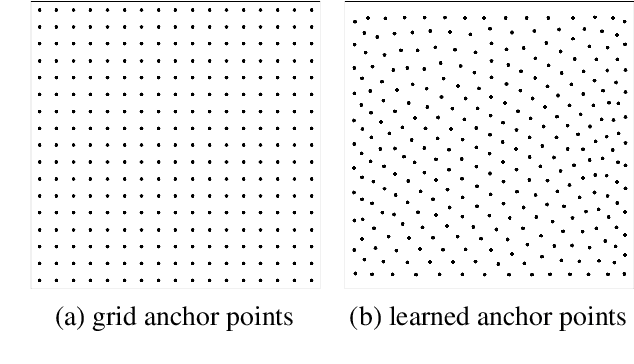
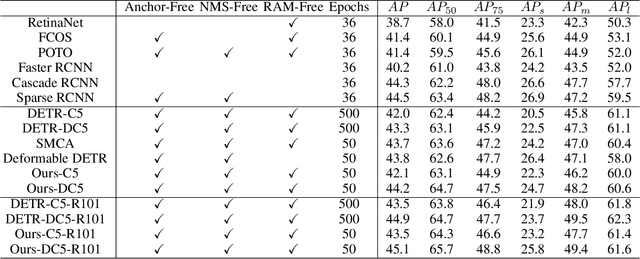
In this paper, we propose a novel query design for the transformer-based detectors. In previous transformer-based detectors, the object queries are a set of learned embeddings. However, each learned embedding does not have an explicit physical meaning and we can not explain where it will focus on. It is difficult to optimize as the prediction slot of each object query does not have a specific mode. In other words, each object query will not focus on a specific region. To solved these problems, in our query design, object queries are based on anchor points, which are widely used in CNN-based detectors. So each object query focus on the objects near the anchor point. Moreover, our query design can predict multiple objects at one position to solve the difficulty: "one region, multiple objects". In addition, we design an attention variant, which can reduce the memory cost while achieving similar or better performance than the standard attention in DETR. Thanks to the query design and the attention variant, the proposed detector that we called Anchor DETR, can achieve better performance and run faster than the DETR with 10$\times$ fewer training epochs. For example, it achieves 44.2 AP with 16 FPS on the MSCOCO dataset when using the ResNet50-DC5 feature for training 50 epochs. Extensive experiments on the MSCOCO benchmark prove the effectiveness of the proposed methods. Code is available at https://github.com/megvii-model/AnchorDETR.
Fully Convolutional Networks for Panoptic Segmentation with Point-based Supervision
Aug 18, 2021
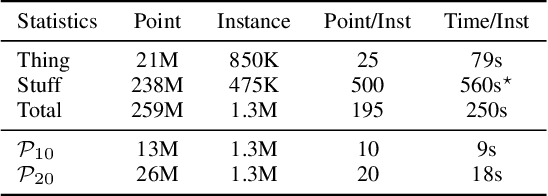
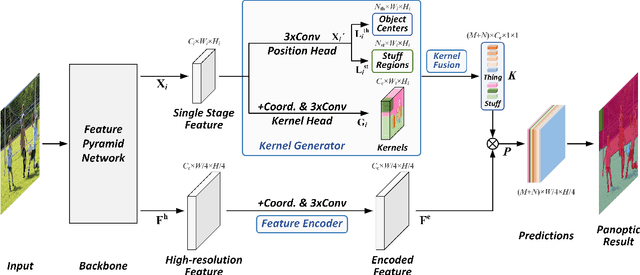
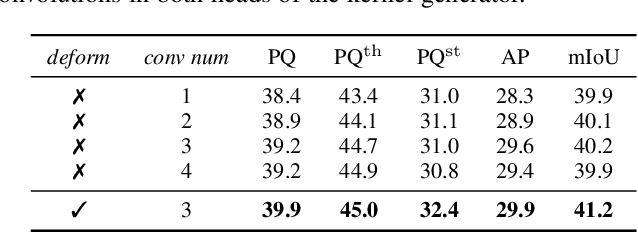
In this paper, we present a conceptually simple, strong, and efficient framework for fully- and weakly-supervised panoptic segmentation, called Panoptic FCN. Our approach aims to represent and predict foreground things and background stuff in a unified fully convolutional pipeline, which can be optimized with point-based fully or weak supervision. In particular, Panoptic FCN encodes each object instance or stuff category with the proposed kernel generator and produces the prediction by convolving the high-resolution feature directly. With this approach, instance-aware and semantically consistent properties for things and stuff can be respectively satisfied in a simple generate-kernel-then-segment workflow. Without extra boxes for localization or instance separation, the proposed approach outperforms the previous box-based and -free models with high efficiency. Furthermore, we propose a new form of point-based annotation for weakly-supervised panoptic segmentation. It only needs several random points for both things and stuff, which dramatically reduces the annotation cost of human. The proposed Panoptic FCN is also proved to have much superior performance in this weakly-supervised setting, which achieves 82% of the fully-supervised performance with only 20 randomly annotated points per instance. Extensive experiments demonstrate the effectiveness and efficiency of Panoptic FCN on COCO, VOC 2012, Cityscapes, and Mapillary Vistas datasets. And it sets up a new leading benchmark for both fully- and weakly-supervised panoptic segmentation. Our code and models are made publicly available at https://github.com/dvlab-research/PanopticFCN