 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Critique and Refinement for Faithful Natural Language Explanations
May 28, 2025



With the rapid development of large language models (LLMs), natural language explanations (NLEs) have become increasingly important for understanding model predictions. However, these explanations often fail to faithfully represent the model's actual reasoning process. While existing work has demonstrated that LLMs can self-critique and refine their initial outputs for various tasks, this capability remains unexplored for improving explanation faithfulness. To address this gap, we introduce Self-critique and Refinement for Natural Language Explanations (SR-NLE), a framework that enables models to improve the faithfulness of their own explanations -- specifically, post-hoc NLEs -- through an iterative critique and refinement process without external supervision. Our framework leverages different feedback mechanisms to guide the refinement process, including natural language self-feedback and, notably, a novel feedback approach based on feature attribution that highlights important input words. Our experiments across three datasets and four state-of-the-art LLMs demonstrate that SR-NLE significantly reduces unfaithfulness rates, with our best method achieving an average unfaithfulness rate of 36.02%, compared to 54.81% for baseline -- an absolute reduction of 18.79%. These findings reveal that the investigated LLMs can indeed refine their explanations to better reflect their actual reasoning process, requiring only appropriate guidance through feedback without additional training or fine-tuning.
Step1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
Anchor DETR: Query Design for Transformer-Based Detector
Sep 15, 2021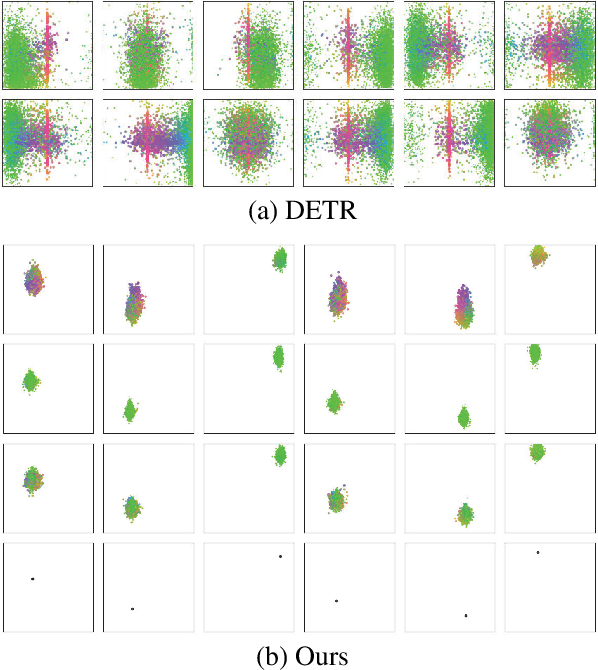

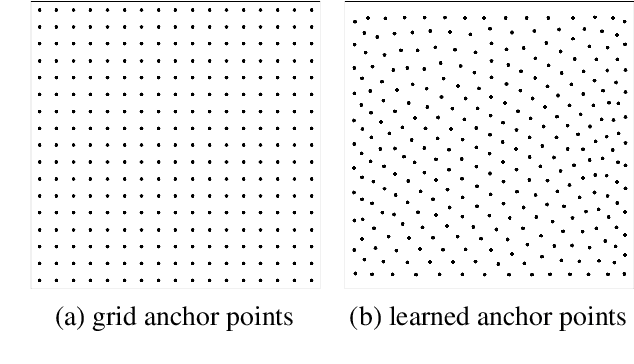
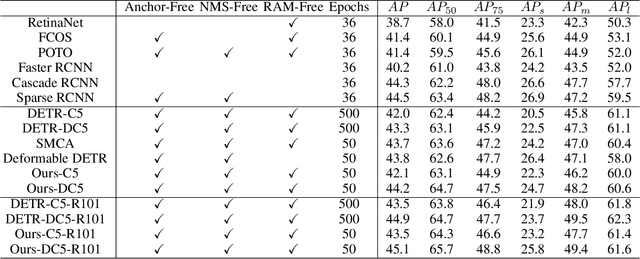
In this paper, we propose a novel query design for the transformer-based detectors. In previous transformer-based detectors, the object queries are a set of learned embeddings. However, each learned embedding does not have an explicit physical meaning and we can not explain where it will focus on. It is difficult to optimize as the prediction slot of each object query does not have a specific mode. In other words, each object query will not focus on a specific region. To solved these problems, in our query design, object queries are based on anchor points, which are widely used in CNN-based detectors. So each object query focus on the objects near the anchor point. Moreover, our query design can predict multiple objects at one position to solve the difficulty: "one region, multiple objects". In addition, we design an attention variant, which can reduce the memory cost while achieving similar or better performance than the standard attention in DETR. Thanks to the query design and the attention variant, the proposed detector that we called Anchor DETR, can achieve better performance and run faster than the DETR with 10$\times$ fewer training epochs. For example, it achieves 44.2 AP with 16 FPS on the MSCOCO dataset when using the ResNet50-DC5 feature for training 50 epochs. Extensive experiments on the MSCOCO benchmark prove the effectiveness of the proposed methods. Code is available at https://github.com/megvii-model/AnchorDETR.
You Only Look One-level Feature
Mar 17, 2021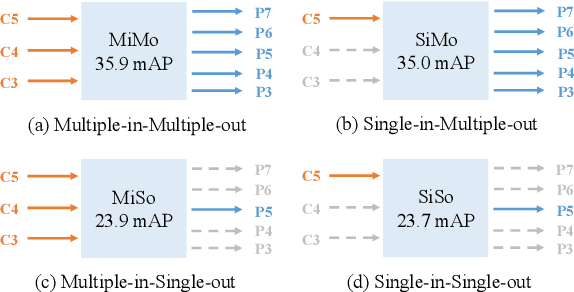
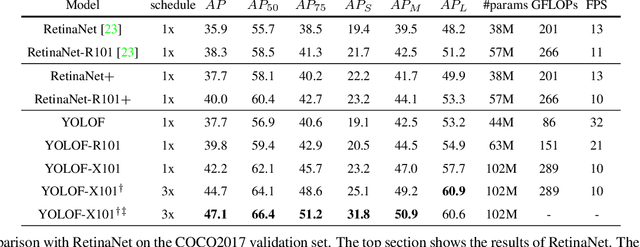

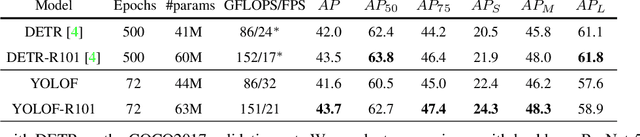
This paper revisits feature pyramids networks (FPN) for one-stage detectors and points out that the success of FPN is due to its divide-and-conquer solution to the optimization problem in object detection rather than multi-scale feature fusion. From the perspective of optimization, we introduce an alternative way to address the problem instead of adopting the complex feature pyramids - {\em utilizing only one-level feature for detection}. Based on the simple and efficient solution, we present You Only Look One-level Feature (YOLOF). In our method, two key components, Dilated Encoder and Uniform Matching, are proposed and bring considerable improvements. Extensive experiments on the COCO benchmark prove the effectiveness of the proposed model. Our YOLOF achieves comparable results with its feature pyramids counterpart RetinaNet while being $2.5\times$ faster. Without transformer layers, YOLOF can match the performance of DETR in a single-level feature manner with $7\times$ less training epochs. With an image size of $608\times608$, YOLOF achieves 44.3 mAP running at 60 fps on 2080Ti, which is $13\%$ faster than YOLOv4. Code is available at \url{https://github.com/megvii-model/YOLOF}.