 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoGigaGAN: Towards Detail-rich Video Super-Resolution
Apr 18, 2024



Video super-resolution (VSR) approaches have shown impressive temporal consistency in upsampled videos. However, these approaches tend to generate blurrier results than their image counterparts as they are limited in their generative capability. This raises a fundamental question: can we extend the success of a generative image upsampler to the VSR task while preserving the temporal consistency? We introduce VideoGigaGAN, a new generative VSR model that can produce videos with high-frequency details and temporal consistency. VideoGigaGAN builds upon a large-scale image upsampler -- GigaGAN. Simply inflating GigaGAN to a video model by adding temporal modules produces severe temporal flickering. We identify several key issues and propose techniques that significantly improve the temporal consistency of upsampled videos. Our experiments show that, unlike previous VSR methods, VideoGigaGAN generates temporally consistent videos with more fine-grained appearance details. We validate the effectiveness of VideoGigaGAN by comparing it with state-of-the-art VSR models on public datasets and showcasing video results with $8\times$ super-resolution.
Taming Latent Diffusion Model for Neural Radiance Field Inpainting
Apr 15, 2024Neural Radiance Field (NeRF) is a representation for 3D reconstruction from multi-view images. Despite some recent work showing preliminary success in editing a reconstructed NeRF with diffusion prior, they remain struggling to synthesize reasonable geometry in completely uncovered regions. One major reason is the high diversity of synthetic contents from the diffusion model, which hinders the radiance field from converging to a crisp and deterministic geometry. Moreover, applying latent diffusion models on real data often yields a textural shift incoherent to the image condition due to auto-encoding errors. These two problems are further reinforced with the use of pixel-distance losses. To address these issues, we propose tempering the diffusion model's stochasticity with per-scene customization and mitigating the textural shift with masked adversarial training. During the analyses, we also found the commonly used pixel and perceptual losses are harmful in the NeRF inpainting task. Through rigorous experiments, our framework yields state-of-the-art NeRF inpainting results on various real-world scenes. Project page: https://hubert0527.github.io/MALD-NeRF
Recent Trends in 3D Reconstruction of General Non-Rigid Scenes
Mar 22, 2024Reconstructing models of the real world, including 3D geometry, appearance, and motion of real scenes, is essential for computer graphics and computer vision. It enables the synthesizing of photorealistic novel views, useful for the movie industry and AR/VR applications. It also facilitates the content creation necessary in computer games and AR/VR by avoiding laborious manual design processes. Further, such models are fundamental for intelligent computing systems that need to interpret real-world scenes and actions to act and interact safely with the human world. Notably, the world surrounding us is dynamic, and reconstructing models of dynamic, non-rigidly moving scenes is a severely underconstrained and challenging problem. This state-of-the-art report (STAR) offers the reader a comprehensive summary of state-of-the-art techniques with monocular and multi-view inputs such as data from RGB and RGB-D sensors, among others, conveying an understanding of different approaches, their potential applications, and promising further research directions. The report covers 3D reconstruction of general non-rigid scenes and further addresses the techniques for scene decomposition, editing and controlling, and generalizable and generative modeling. More specifically, we first review the common and fundamental concepts necessary to understand and navigate the field and then discuss the state-of-the-art techniques by reviewing recent approaches that use traditional and machine-learning-based neural representations, including a discussion on the newly enabled applications. The STAR is concluded with a discussion of the remaining limitations and open challenges.
Magic Fixup: Streamlining Photo Editing by Watching Dynamic Videos
Mar 19, 2024



We propose a generative model that, given a coarsely edited image, synthesizes a photorealistic output that follows the prescribed layout. Our method transfers fine details from the original image and preserves the identity of its parts. Yet, it adapts it to the lighting and context defined by the new layout. Our key insight is that videos are a powerful source of supervision for this task: objects and camera motions provide many observations of how the world changes with viewpoint, lighting, and physical interactions. We construct an image dataset in which each sample is a pair of source and target frames extracted from the same video at randomly chosen time intervals. We warp the source frame toward the target using two motion models that mimic the expected test-time user edits. We supervise our model to translate the warped image into the ground truth, starting from a pretrained diffusion model. Our model design explicitly enables fine detail transfer from the source frame to the generated image, while closely following the user-specified layout. We show that by using simple segmentations and coarse 2D manipulations, we can synthesize a photorealistic edit faithful to the user's input while addressing second-order effects like harmonizing the lighting and physical interactions between edited objects.
CTGAN: Semantic-guided Conditional Texture Generator for 3D Shapes
Feb 08, 2024The entertainment industry relies on 3D visual content to create immersive experiences, but traditional methods for creating textured 3D models can be time-consuming and subjective. Generative networks such as StyleGAN have advanced image synthesis, but generating 3D objects with high-fidelity textures is still not well explored, and existing methods have limitations. We propose the Semantic-guided Conditional Texture Generator (CTGAN), producing high-quality textures for 3D shapes that are consistent with the viewing angle while respecting shape semantics. CTGAN utilizes the disentangled nature of StyleGAN to finely manipulate the input latent codes, enabling explicit control over both the style and structure of the generated textures. A coarse-to-fine encoder architecture is introduced to enhance control over the structure of the resulting textures via input segmentation. Experimental results show that CTGAN outperforms existing methods on multiple quality metrics and achieves state-of-the-art performance on texture generation in both conditional and unconditional settings.
IRIS: Inverse Rendering of Indoor Scenes from Low Dynamic Range Images
Jan 23, 2024While numerous 3D reconstruction and novel-view synthesis methods allow for photorealistic rendering of a scene from multi-view images easily captured with consumer cameras, they bake illumination in their representations and fall short of supporting advanced applications like material editing, relighting, and virtual object insertion. The reconstruction of physically based material properties and lighting via inverse rendering promises to enable such applications. However, most inverse rendering techniques require high dynamic range (HDR) images as input, a setting that is inaccessible to most users. We present a method that recovers the physically based material properties and spatially-varying HDR lighting of a scene from multi-view, low-dynamic-range (LDR) images. We model the LDR image formation process in our inverse rendering pipeline and propose a novel optimization strategy for material, lighting, and a camera response model. We evaluate our approach with synthetic and real scenes compared to the state-of-the-art inverse rendering methods that take either LDR or HDR input. Our method outperforms existing methods taking LDR images as input, and allows for highly realistic relighting and object insertion.
TextureDreamer: Image-guided Texture Synthesis through Geometry-aware Diffusion
Jan 17, 2024



We present TextureDreamer, a novel image-guided texture synthesis method to transfer relightable textures from a small number of input images (3 to 5) to target 3D shapes across arbitrary categories. Texture creation is a pivotal challenge in vision and graphics. Industrial companies hire experienced artists to manually craft textures for 3D assets. Classical methods require densely sampled views and accurately aligned geometry, while learning-based methods are confined to category-specific shapes within the dataset. In contrast, TextureDreamer can transfer highly detailed, intricate textures from real-world environments to arbitrary objects with only a few casually captured images, potentially significantly democratizing texture creation. Our core idea, personalized geometry-aware score distillation (PGSD), draws inspiration from recent advancements in diffuse models, including personalized modeling for texture information extraction, variational score distillation for detailed appearance synthesis, and explicit geometry guidance with ControlNet. Our integration and several essential modifications substantially improve the texture quality. Experiments on real images spanning different categories show that TextureDreamer can successfully transfer highly realistic, semantic meaningful texture to arbitrary objects, surpassing the visual quality of previous state-of-the-art.
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis
Dec 29, 2023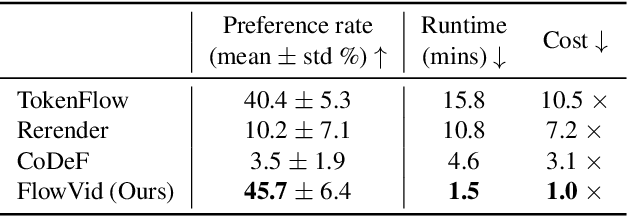

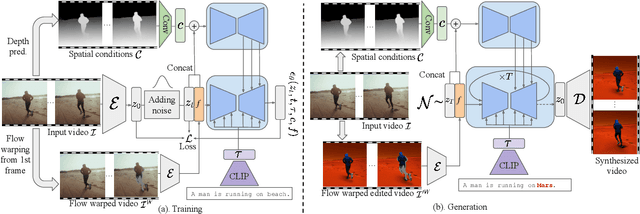

Diffusion models have transformed the image-to-image (I2I) synthesis and are now permeating into videos. However, the advancement of video-to-video (V2V) synthesis has been hampered by the challenge of maintaining temporal consistency across video frames. This paper proposes a consistent V2V synthesis framework by jointly leveraging spatial conditions and temporal optical flow clues within the source video. Contrary to prior methods that strictly adhere to optical flow, our approach harnesses its benefits while handling the imperfection in flow estimation. We encode the optical flow via warping from the first frame and serve it as a supplementary reference in the diffusion model. This enables our model for video synthesis by editing the first frame with any prevalent I2I models and then propagating edits to successive frames. Our V2V model, FlowVid, demonstrates remarkable properties: (1) Flexibility: FlowVid works seamlessly with existing I2I models, facilitating various modifications, including stylization, object swaps, and local edits. (2) Efficiency: Generation of a 4-second video with 30 FPS and 512x512 resolution takes only 1.5 minutes, which is 3.1x, 7.2x, and 10.5x faster than CoDeF, Rerender, and TokenFlow, respectively. (3) High-quality: In user studies, our FlowVid is preferred 45.7% of the time, outperforming CoDeF (3.5%), Rerender (10.2%), and TokenFlow (40.4%).
Fast View Synthesis of Casual Videos
Dec 04, 2023Novel view synthesis from an in-the-wild video is difficult due to challenges like scene dynamics and lack of parallax. While existing methods have shown promising results with implicit neural radiance fields, they are slow to train and render. This paper revisits explicit video representations to synthesize high-quality novel views from a monocular video efficiently. We treat static and dynamic video content separately. Specifically, we build a global static scene model using an extended plane-based scene representation to synthesize temporally coherent novel video. Our plane-based scene representation is augmented with spherical harmonics and displacement maps to capture view-dependent effects and model non-planar complex surface geometry. We opt to represent the dynamic content as per-frame point clouds for efficiency. While such representations are inconsistency-prone, minor temporal inconsistencies are perceptually masked due to motion. We develop a method to quickly estimate such a hybrid video representation and render novel views in real time. Our experiments show that our method can render high-quality novel views from an in-the-wild video with comparable quality to state-of-the-art methods while being 100x faster in training and enabling real-time rendering.
Single-Image 3D Human Digitization with Shape-Guided Diffusion
Nov 15, 2023We present an approach to generate a 360-degree view of a person with a consistent, high-resolution appearance from a single input image. NeRF and its variants typically require videos or images from different viewpoints. Most existing approaches taking monocular input either rely on ground-truth 3D scans for supervision or lack 3D consistency. While recent 3D generative models show promise of 3D consistent human digitization, these approaches do not generalize well to diverse clothing appearances, and the results lack photorealism. Unlike existing work, we utilize high-capacity 2D diffusion models pretrained for general image synthesis tasks as an appearance prior of clothed humans. To achieve better 3D consistency while retaining the input identity, we progressively synthesize multiple views of the human in the input image by inpainting missing regions with shape-guided diffusion conditioned on silhouette and surface normal. We then fuse these synthesized multi-view images via inverse rendering to obtain a fully textured high-resolution 3D mesh of the given person. Experiments show that our approach outperforms prior methods and achieves photorealistic 360-degree synthesis of a wide range of clothed humans with complex textures from a single image.