 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRIVE: Structured Representation Integrating VLM Reasoning for Efficient Object Navigation
May 10, 2025



Vision-Language Models (VLMs) have been increasingly integrated into object navigation tasks for their rich prior knowledge and strong reasoning abilities. However, applying VLMs to navigation poses two key challenges: effectively representing complex environment information and determining \textit{when and how} to query VLMs. Insufficient environment understanding and over-reliance on VLMs (e.g. querying at every step) can lead to unnecessary backtracking and reduced navigation efficiency, especially in continuous environments. To address these challenges, we propose a novel framework that constructs a multi-layer representation of the environment during navigation. This representation consists of viewpoint, object nodes, and room nodes. Viewpoints and object nodes facilitate intra-room exploration and accurate target localization, while room nodes support efficient inter-room planning. Building on this representation, we propose a novel two-stage navigation policy, integrating high-level planning guided by VLM reasoning with low-level VLM-assisted exploration to efficiently locate a goal object. We evaluated our approach on three simulated benchmarks (HM3D, RoboTHOR, and MP3D), and achieved state-of-the-art performance on both the success rate ($\mathord{\uparrow}\, 7.1\%$) and navigation efficiency ($\mathord{\uparrow}\, 12.5\%$). We further validate our method on a real robot platform, demonstrating strong robustness across 15 object navigation tasks in 10 different indoor environments. Project page is available at https://zwandering.github.io/STRIVE.github.io/ .
SORT3D: Spatial Object-centric Reasoning Toolbox for Zero-Shot 3D Grounding Using Large Language Models
Apr 25, 2025Interpreting object-referential language and grounding objects in 3D with spatial relations and attributes is essential for robots operating alongside humans. However, this task is often challenging due to the diversity of scenes, large number of fine-grained objects, and complex free-form nature of language references. Furthermore, in the 3D domain, obtaining large amounts of natural language training data is difficult. Thus, it is important for methods to learn from little data and zero-shot generalize to new environments. To address these challenges, we propose SORT3D, an approach that utilizes rich object attributes from 2D data and merges a heuristics-based spatial reasoning toolbox with the ability of large language models (LLMs) to perform sequential reasoning. Importantly, our method does not require text-to-3D data for training and can be applied zero-shot to unseen environments. We show that SORT3D achieves state-of-the-art performance on complex view-dependent grounding tasks on two benchmarks. We also implement the pipeline to run real-time on an autonomous vehicle and demonstrate that our approach can be used for object-goal navigation on previously unseen real-world environments. All source code for the system pipeline is publicly released at https://github.com/nzantout/SORT3D .
Towards Stepwise Domain Knowledge-Driven Reasoning Optimization and Reflection Improvement
Apr 12, 2025
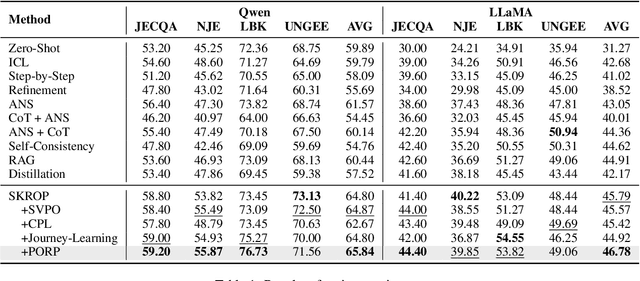
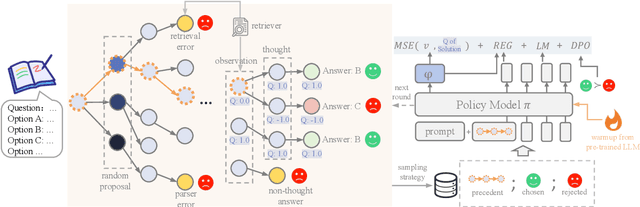
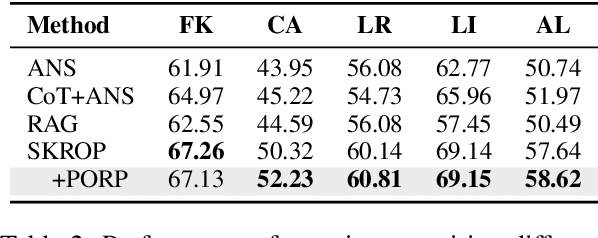
Recently, stepwise supervision on Chain of Thoughts (CoTs) presents an enhancement on the logical reasoning tasks such as coding and math, with the help of Monte Carlo Tree Search (MCTS). However, its contribution to tasks requiring domain-specific expertise and knowledge remains unexplored. Motivated by the interest, we identify several potential challenges of vanilla MCTS within this context, and propose the framework of Stepwise Domain Knowledge-Driven Reasoning Optimization, employing the MCTS algorithm to develop step-level supervision for problems that require essential comprehension, reasoning, and specialized knowledge. Additionally, we also introduce the Preference Optimization towards Reflection Paths, which iteratively learns self-reflection on the reasoning thoughts from better perspectives. We have conducted extensive experiments to evaluate the advantage of the methodologies. Empirical results demonstrate the effectiveness on various legal-domain problems. We also report a diverse set of valuable findings, hoping to encourage the enthusiasm to the research of domain-specific LLMs and MCTS.
AdaMMS: Model Merging for Heterogeneous Multimodal Large Language Models with Unsupervised Coefficient Optimization
Mar 31, 2025Recently, model merging methods have demonstrated powerful strengths in combining abilities on various tasks from multiple Large Language Models (LLMs). While previous model merging methods mainly focus on merging homogeneous models with identical architecture, they meet challenges when dealing with Multimodal Large Language Models (MLLMs) with inherent heterogeneous property, including differences in model architecture and the asymmetry in the parameter space. In this work, we propose AdaMMS, a novel model merging method tailored for heterogeneous MLLMs. Our method tackles the challenges in three steps: mapping, merging and searching. Specifically, we first design mapping function between models to apply model merging on MLLMs with different architecture. Then we apply linear interpolation on model weights to actively adapt the asymmetry in the heterogeneous MLLMs. Finally in the hyper-parameter searching step, we propose an unsupervised hyper-parameter selection method for model merging. As the first model merging method capable of merging heterogeneous MLLMs without labeled data, extensive experiments on various model combinations demonstrated that AdaMMS outperforms previous model merging methods on various vision-language benchmarks.
MOSAIC: Generating Consistent, Privacy-Preserving Scenes from Multiple Depth Views in Multi-Room Environments
Mar 18, 2025We introduce a novel diffusion-based approach for generating privacy-preserving digital twins of multi-room indoor environments from depth images only. Central to our approach is a novel Multi-view Overlapped Scene Alignment with Implicit Consistency (MOSAIC) model that explicitly considers cross-view dependencies within the same scene in the probabilistic sense. MOSAIC operates through a novel inference-time optimization that avoids error accumulation common in sequential or single-room constraint in panorama-based approaches. MOSAIC scales to complex scenes with zero extra training and provably reduces the variance during denoising processes when more overlapping views are added, leading to improved generation quality. Experiments show that MOSAIC outperforms state-of-the-art baselines on image fidelity metrics in reconstructing complex multi-room environments. Project page is available at: https://mosaic-cmubig.github.io
Out-of-Distribution Generalization in Time Series: A Survey
Mar 18, 2025



Time series frequently manifest distribution shifts, diverse latent features, and non-stationary learning dynamics, particularly in open and evolving environments. These characteristics pose significant challenges for out-of-distribution (OOD) generalization. While substantial progress has been made, a systematic synthesis of advancements remains lacking. To address this gap, we present the first comprehensive review of OOD generalization methodologies for time series, organized to delineate the field's evolutionary trajectory and contemporary research landscape. We organize our analysis across three foundational dimensions: data distribution, representation learning, and OOD evaluation. For each dimension, we present several popular algorithms in detail. Furthermore, we highlight key application scenarios, emphasizing their real-world impact. Finally, we identify persistent challenges and propose future research directions. A detailed summary of the methods reviewed for the generalization of OOD in time series can be accessed at https://tsood-generalization.com.
WritingBench: A Comprehensive Benchmark for Generative Writing
Mar 07, 2025Recent advancements in large language models (LLMs) have significantly enhanced text generation capabilities, yet evaluating their performance in generative writing remains a challenge. Existing benchmarks primarily focus on generic text generation or limited in writing tasks, failing to capture the diverse requirements of high-quality written contents across various domains. To bridge this gap, we present WritingBench, a comprehensive benchmark designed to evaluate LLMs across 6 core writing domains and 100 subdomains, encompassing creative, persuasive, informative, and technical writing. We further propose a query-dependent evaluation framework that empowers LLMs to dynamically generate instance-specific assessment criteria. This framework is complemented by a fine-tuned critic model for criteria-aware scoring, enabling evaluations in style, format and length. The framework's validity is further demonstrated by its data curation capability, which enables 7B-parameter models to approach state-of-the-art (SOTA) performance. We open-source the benchmark, along with evaluation tools and modular framework components, to advance the development of LLMs in writing.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Speculative Decoding for Multi-Sample Inference
Mar 07, 2025



We propose a novel speculative decoding method tailored for multi-sample reasoning scenarios, such as self-consistency and Best-of-N sampling. Our method exploits the intrinsic consensus of parallel generation paths to synthesize high-quality draft tokens without requiring auxiliary models or external databases. By dynamically analyzing structural patterns across parallel reasoning paths through a probabilistic aggregation mechanism, it identifies consensus token sequences that align with the decoding distribution. Evaluations on mathematical reasoning benchmarks demonstrate a substantial improvement in draft acceptance rates over baselines, while reducing the latency in draft token construction. This work establishes a paradigm shift for efficient multi-sample inference, enabling seamless integration of speculative decoding with sampling-based reasoning techniques.
MM-StoryAgent: Immersive Narrated Storybook Video Generation with a Multi-Agent Paradigm across Text, Image and Audio
Mar 07, 2025



The rapid advancement of large language models (LLMs) and artificial intelligence-generated content (AIGC) has accelerated AI-native applications, such as AI-based storybooks that automate engaging story production for children. However, challenges remain in improving story attractiveness, enriching storytelling expressiveness, and developing open-source evaluation benchmarks and frameworks. Therefore, we propose and opensource MM-StoryAgent, which creates immersive narrated video storybooks with refined plots, role-consistent images, and multi-channel audio. MM-StoryAgent designs a multi-agent framework that employs LLMs and diverse expert tools (generative models and APIs) across several modalities to produce expressive storytelling videos. The framework enhances story attractiveness through a multi-stage writing pipeline. In addition, it improves the immersive storytelling experience by integrating sound effects with visual, music and narrative assets. MM-StoryAgent offers a flexible, open-source platform for further development, where generative modules can be substituted. Both objective and subjective evaluation regarding textual story quality and alignment between modalities validate the effectiveness of our proposed MM-StoryAgent system. The demo and source code are available.