 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShare More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
May 26, 2026Test-Time Scaling (TTS) enhances the reasoning capabilities of large language models by allocating additional inference compute to explore the solution space. However, existing parallel TTS methods typically keep branches isolated during search: intermediate discoveries remain branch-private and cannot guide other branches in time. This information isolation causes substantial redundant exploration, as branches repeatedly rediscover information already found elsewhere and require more search steps to collect complete decision information needed to reach correct answers. To bridge this gap, we propose \textbf{Collaborative Parallel Thinking (CPT)}, a training-free inference framework that enables search-time information sharing across parallel branches. CPT extracts compact intermediate information from ongoing branches, maintains a deduplicated query-level information pool, and broadcasts pool entries through the input context, allowing each branch in subsequent search steps to reuse discoveries made by other branches rather than rediscover the same information. Empirically, experiments on HMMT and AIME benchmarks show that CPT establishes a stronger accuracy--latency Pareto frontier than strong baselines across rollout budgets and model scales, highlighting search-time collaboration as an effective direction for efficient parallel TTS.
On Time, Within Budget: Constraint-Driven Online Resource Allocation for Agentic Workflows
May 07, 2026Agentic systems increasingly solve complex user requests by executing orchestrated workflows, where subtasks are assigned to specialized models or tools and coordinated according to their dependencies. While recent work improves agent efficiency by optimizing the performance--cost--latency frontier, real deployments often impose concrete requirements: a workflow must be completed within a specified budget and before a specified deadline. This shifts the goal from average efficiency optimization to maximizing the probability that the entire workflow completes successfully under explicit budget and deadline constraints. We study \emph{constraint-driven online resource allocation for agentic workflows}. Given a dependency-structured workflow and estimates of success rates and generation lengths for each subtask--model pair, the executor allocates models and parallel samples across simultaneously executable subtasks while managing the remaining budget and time. We formulate this setting as a finite-horizon stochastic online allocation problem and propose \emph{Monte Carlo Portfolio Planning} (MCPP), a lightweight closed-loop planner that directly estimates constrained completion probability through simulated workflow executions and replans after observed outcomes. Experiments on CodeFlow and ProofFlow demonstrate that MCPP consistently improves constrained completion probability over strong baselines across a wide range of budget--deadline constraints.
Learning More from Less: Unlocking Internal Representations for Benchmark Compression
Feb 03, 2026The prohibitive cost of evaluating Large Language Models (LLMs) necessitates efficient alternatives to full-scale benchmarking. Prevalent approaches address this by identifying a small coreset of items to approximate full-benchmark performance. However, existing methods must estimate a reliable item profile from response patterns across many source models, which becomes statistically unstable when the source pool is small. This dependency is particularly limiting for newly released benchmarks with minimal historical evaluation data. We argue that discrete correctness labels are a lossy view of the model's decision process and fail to capture information encoded in hidden states. To address this, we introduce REPCORE, which aligns heterogeneous hidden states into a unified latent space to construct representative coresets. Using these subsets for performance extrapolation, REPCORE achieves precise estimation accuracy with as few as ten source models. Experiments on five benchmarks and over 200 models show consistent gains over output-based baselines in ranking correlation and estimation accuracy. Spectral analysis further indicates that the aligned representations contain separable components reflecting broad response tendencies and task-specific reasoning patterns.
Do Not Waste Your Rollouts: Recycling Search Experience for Efficient Test-Time Scaling
Jan 29, 2026Test-Time Scaling enhances the reasoning capabilities of Large Language Models by allocating additional inference compute to broaden the exploration of the solution space. However, existing search strategies typically treat rollouts as disposable samples, where valuable intermediate insights are effectively discarded after each trial. This systemic memorylessness leads to massive computational redundancy, as models repeatedly re-derive discovered conclusions and revisit known dead ends across extensive attempts. To bridge this gap, we propose \textbf{Recycling Search Experience (RSE)}, a self-guided, training-free strategy that turns test-time search from a series of isolated trials into a cumulative process. By actively distilling raw trajectories into a shared experience bank, RSE enables positive recycling of intermediate conclusions to shortcut redundant derivations and negative recycling of failure patterns to prune encountered dead ends. Theoretically, we provide an analysis that formalizes the efficiency gains of RSE, validating its advantage over independent sampling in solving complex reasoning tasks. Empirically, extensive experiments on HMMT24, HMMT25, IMO-Bench, and HLE show that RSE consistently outperforms strong baselines with comparable computational cost, achieving state-of-the-art scaling efficiency.
A Capsule-Sized Multi-Wavelength Wireless Optical System for Edge-AI-Based Classification of Gastrointestinal Bleeding Flow Rate
Jan 25, 2026Post-endoscopic gastrointestinal (GI) rebleeding frequently occurs within the first 72 hours after therapeutic hemostasis and remains a major cause of early morbidity and mortality. Existing non-invasive monitoring approaches primarily provide binary blood detection and lack quantitative assessment of bleeding severity or flow dynamic, limiting their ability to support timely clinical decision-making during this high-risk period. In this work, we developed a capsule-sized, multi-wavelength optical sensing wireless platform for order-of-magnitude-level classification of GI bleeding flow rate, leveraging transmission spectroscopy and low-power edge artificial intelligence. The system performs time-resolved, multi-spectral measurements and employs a lightweight two-dimensional convolutional neural network for on-device flow-rate classification, with physics-based validation confirming consistency with wavelength-dependent hemoglobin absorption behavior. In controlled in vitro experiments under simulated gastric conditions, the proposed approach achieved an overall classification accuracy of 98.75% across multiple bleeding flow-rate levels while robustly distinguishing diverse non-blood gastrointestinal interference. By performing embedded inference directly on the capsule electronics, the system reduced overall energy consumption by approximately 88% compared with continuous wireless transmission of raw data, making prolonged, battery-powered operation feasible. Extending capsule-based diagnostics beyond binary blood detection toward continuous, site-specific assessment of bleeding severity, this platform has the potential to support earlier identification of clinically significant rebleeding and inform timely re-intervention during post-endoscopic surveillance.
Mind the Quote: Enabling Quotation-Aware Dialogue in LLMs via Plug-and-Play Modules
May 30, 2025Human-AI conversation frequently relies on quoting earlier text-"check it with the formula I just highlighted"-yet today's large language models (LLMs) lack an explicit mechanism for locating and exploiting such spans. We formalise the challenge as span-conditioned generation, decomposing each turn into the dialogue history, a set of token-offset quotation spans, and an intent utterance. Building on this abstraction, we introduce a quotation-centric data pipeline that automatically synthesises task-specific dialogues, verifies answer correctness through multi-stage consistency checks, and yields both a heterogeneous training corpus and the first benchmark covering five representative scenarios. To meet the benchmark's zero-overhead and parameter-efficiency requirements, we propose QuAda, a lightweight training-based method that attaches two bottleneck projections to every attention head, dynamically amplifying or suppressing attention to quoted spans at inference time while leaving the prompt unchanged and updating < 2.8% of backbone weights. Experiments across models show that QuAda is suitable for all scenarios and generalises to unseen topics, offering an effective, plug-and-play solution for quotation-aware dialogue.
Silencer: From Discovery to Mitigation of Self-Bias in LLM-as-Benchmark-Generator
May 27, 2025


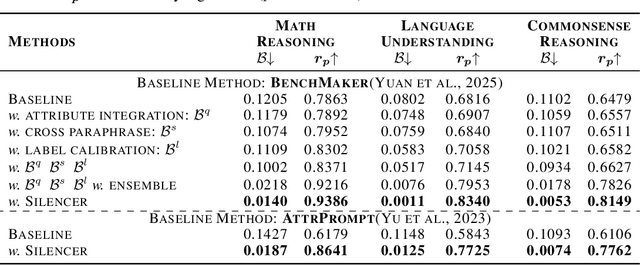
LLM-as-Benchmark-Generator methods have been widely studied as a supplement to human annotators for scalable evaluation, while the potential biases within this paradigm remain underexplored. In this work, we systematically define and validate the phenomenon of inflated performance in models evaluated on their self-generated benchmarks, referred to as self-bias, and attribute it to sub-biases arising from question domain, language style, and wrong labels. On this basis, we propose Silencer, a general framework that leverages the heterogeneity between multiple generators at both the sample and benchmark levels to neutralize bias and generate high-quality, self-bias-silenced benchmark. Experimental results across various settings demonstrate that Silencer can suppress self-bias to near zero, significantly improve evaluation effectiveness of the generated benchmark (with an average improvement from 0.655 to 0.833 in Pearson correlation with high-quality human-annotated benchmark), while also exhibiting strong generalizability.
Speculative Decoding for Multi-Sample Inference
Mar 07, 2025



We propose a novel speculative decoding method tailored for multi-sample reasoning scenarios, such as self-consistency and Best-of-N sampling. Our method exploits the intrinsic consensus of parallel generation paths to synthesize high-quality draft tokens without requiring auxiliary models or external databases. By dynamically analyzing structural patterns across parallel reasoning paths through a probabilistic aggregation mechanism, it identifies consensus token sequences that align with the decoding distribution. Evaluations on mathematical reasoning benchmarks demonstrate a substantial improvement in draft acceptance rates over baselines, while reducing the latency in draft token construction. This work establishes a paradigm shift for efficient multi-sample inference, enabling seamless integration of speculative decoding with sampling-based reasoning techniques.
Revisiting Self-Consistency from Dynamic Distributional Alignment Perspective on Answer Aggregation
Feb 27, 2025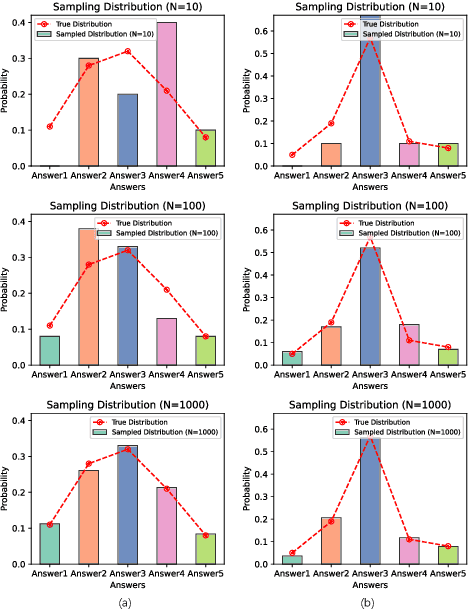
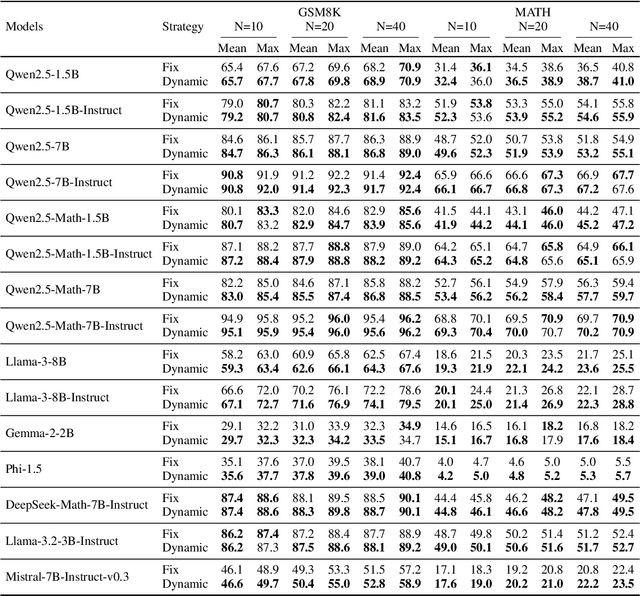
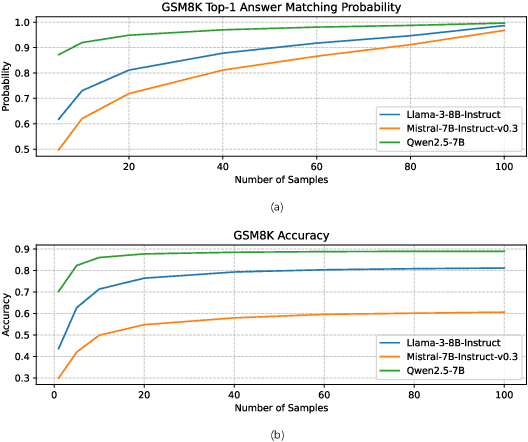
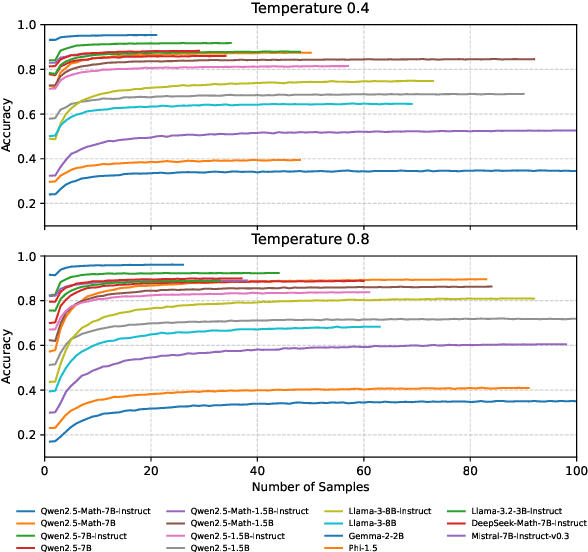
Self-consistency improves reasoning by aggregating diverse stochastic samples, yet the dynamics behind its efficacy remain underexplored. We reframe self-consistency as a dynamic distributional alignment problem, revealing that decoding temperature not only governs sampling randomness but also actively shapes the latent answer distribution. Given that high temperatures require prohibitively large sample sizes to stabilize, while low temperatures risk amplifying biases, we propose a confidence-driven mechanism that dynamically calibrates temperature: sharpening the sampling distribution under uncertainty to align with high-probability modes, and promoting exploration when confidence is high. Experiments on mathematical reasoning tasks show this approach outperforms fixed-diversity baselines under limited samples, improving both average and best-case performance across varying initial temperatures without additional data or modules. This establishes self-consistency as a synchronization challenge between sampling dynamics and evolving answer distributions.
From Sub-Ability Diagnosis to Human-Aligned Generation: Bridging the Gap for Text Length Control via MARKERGEN
Feb 19, 2025



Despite the rapid progress of large language models (LLMs), their length-controllable text generation (LCTG) ability remains below expectations, posing a major limitation for practical applications. Existing methods mainly focus on end-to-end training to reinforce adherence to length constraints. However, the lack of decomposition and targeted enhancement of LCTG sub-abilities restricts further progress.To bridge this gap, we conduct a bottom-up decomposition of LCTG sub-abilities with human patterns as reference and perform a detailed error analysis.On this basis, we propose MarkerGen, a simple-yet-effective plug-and-play approach that:(1) mitigates LLM fundamental deficiencies via external tool integration;(2) conducts explicit length modeling with dynamically inserted markers;(3) employs a three-stage generation scheme to better align length constraints while maintaining content quality.Comprehensive experiments demonstrate that MarkerGen significantly improves LCTG across various settings, exhibiting outstanding effectiveness and generalizability.