 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021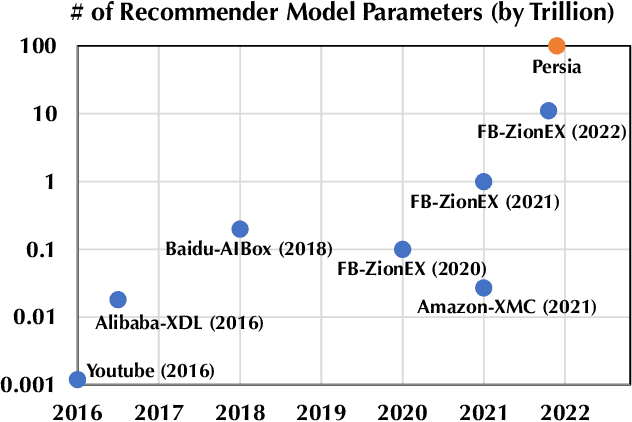
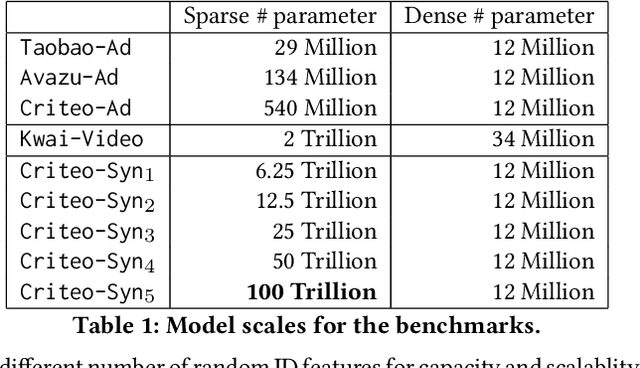
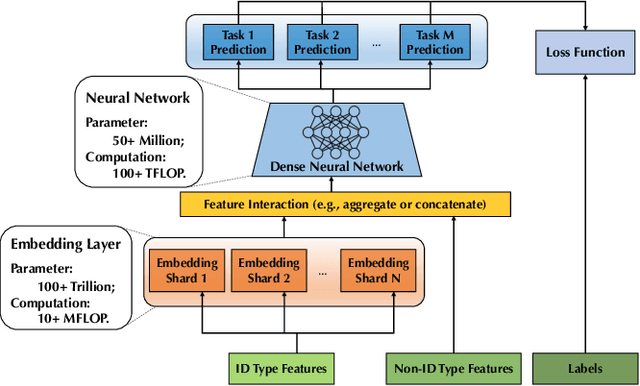
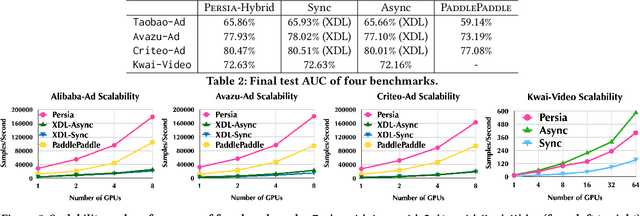
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
Decentralized Multi-Armed Bandit Can Outperform Classic Upper Confidence Bound
Nov 22, 2021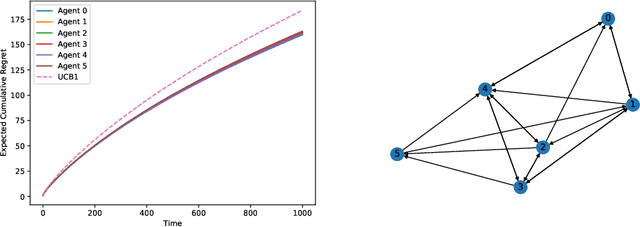
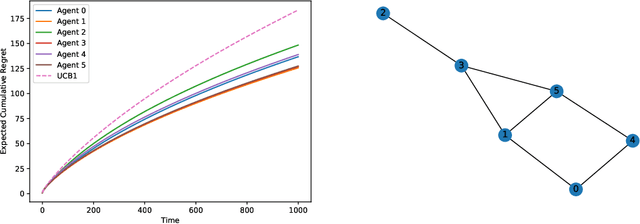
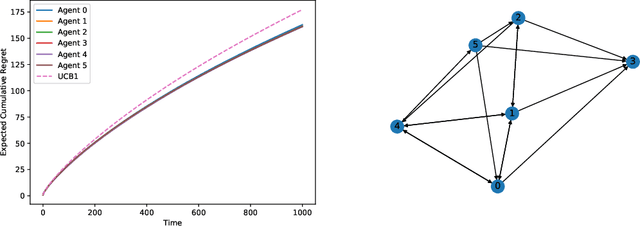
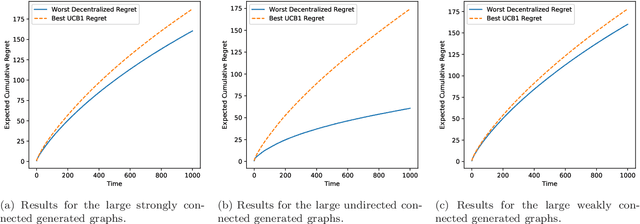
This paper studies a decentralized multi-armed bandit problem in a multi-agent network. The problem is simultaneously solved by N agents assuming they face a common set of M arms and share the same mean of each arm's reward. Each agent can receive information only from its neighbors, where the neighbor relations among the agents are described by a directed graph whose vertices represent agents and whose directed edges depict neighbor relations. A fully decentralized multi-armed bandit algorithm is proposed for each agent, which twists the classic consensus algorithm and upper confidence bound (UCB) algorithm. It is shown that the algorithm guarantees each agent to achieve a better logarithmic asymptotic regret than the classic UCB provided the neighbor graph is strongly connected. The regret can be further improved if the neighbor graph is undirected.
HeterPS: Distributed Deep Learning With Reinforcement Learning Based Scheduling in Heterogeneous Environments
Nov 20, 2021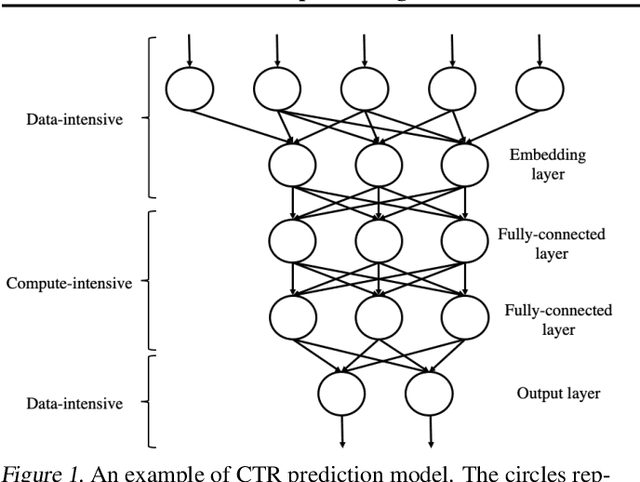

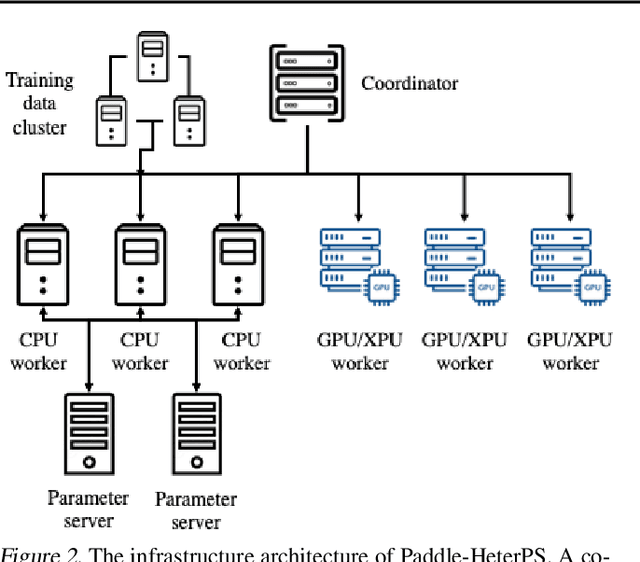
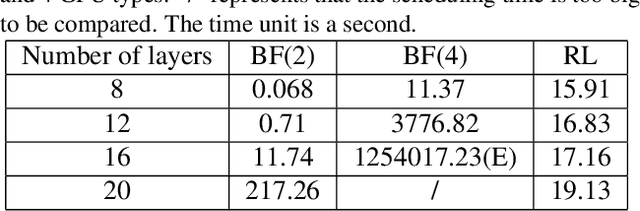
Deep neural networks (DNNs) exploit many layers and a large number of parameters to achieve excellent performance. The training process of DNN models generally handles large-scale input data with many sparse features, which incurs high Input/Output (IO) cost, while some layers are compute-intensive. The training process generally exploits distributed computing resources to reduce training time. In addition, heterogeneous computing resources, e.g., CPUs, GPUs of multiple types, are available for the distributed training process. Thus, the scheduling of multiple layers to diverse computing resources is critical for the training process. To efficiently train a DNN model using the heterogeneous computing resources, we propose a distributed framework, i.e., Paddle-Heterogeneous Parameter Server (Paddle-HeterPS), composed of a distributed architecture and a Reinforcement Learning (RL)-based scheduling method. The advantages of Paddle-HeterPS are three-fold compared with existing frameworks. First, Paddle-HeterPS enables efficient training process of diverse workloads with heterogeneous computing resources. Second, Paddle-HeterPS exploits an RL-based method to efficiently schedule the workload of each layer to appropriate computing resources to minimize the cost while satisfying throughput constraints. Third, Paddle-HeterPS manages data storage and data communication among distributed computing resources. We carry out extensive experiments to show that Paddle-HeterPS significantly outperforms state-of-the-art approaches in terms of throughput (14.5 times higher) and monetary cost (312.3% smaller). The codes of the framework are publicly available at: https://github.com/PaddlePaddle/Paddle.
Resilient Consensus-based Multi-agent Reinforcement Learning with Function Approximation
Nov 18, 2021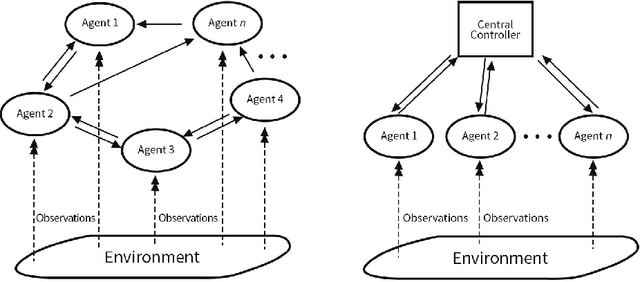
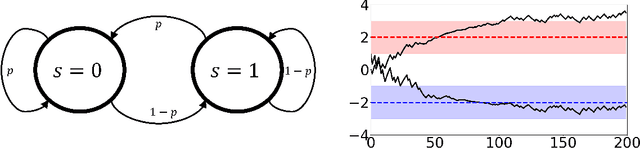
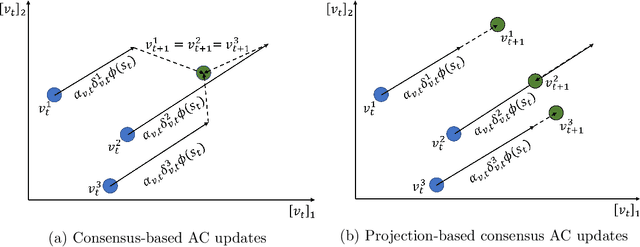
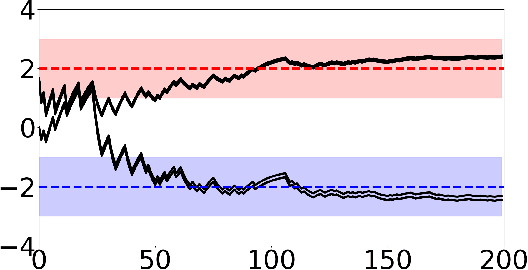
Adversarial attacks during training can strongly influence the performance of multi-agent reinforcement learning algorithms. It is, thus, highly desirable to augment existing algorithms such that the impact of adversarial attacks on cooperative networks is eliminated, or at least bounded. In this work, we consider a fully decentralized network, where each agent receives a local reward and observes the global state and action. We propose a resilient consensus-based actor-critic algorithm, whereby each agent estimates the team-average reward and value function, and communicates the associated parameter vectors to its immediate neighbors. We show that in the presence of Byzantine agents, whose estimation and communication strategies are completely arbitrary, the estimates of the cooperative agents converge to a bounded consensus value with probability one, provided that there are at most $H$ Byzantine agents in the neighborhood of each cooperative agent and the network is $(2H+1)$-robust. Furthermore, we prove that the policy of the cooperative agents converges with probability one to a bounded neighborhood around a local maximizer of their team-average objective function under the assumption that the policies of the adversarial agents asymptotically become stationary.
Joint Channel and Weight Pruning for Model Acceleration on Moblie Devices
Nov 09, 2021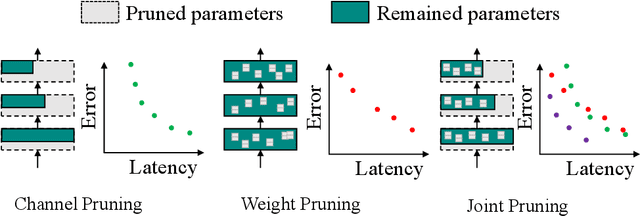
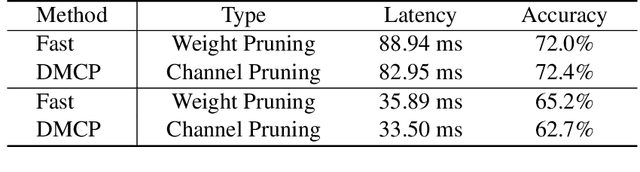
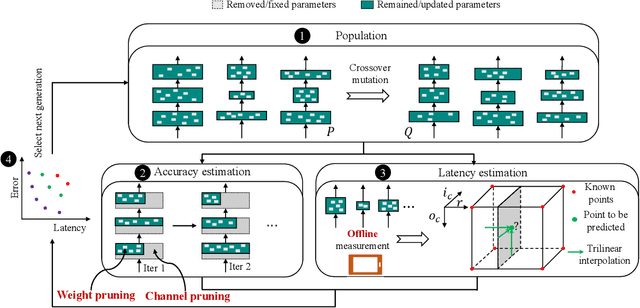
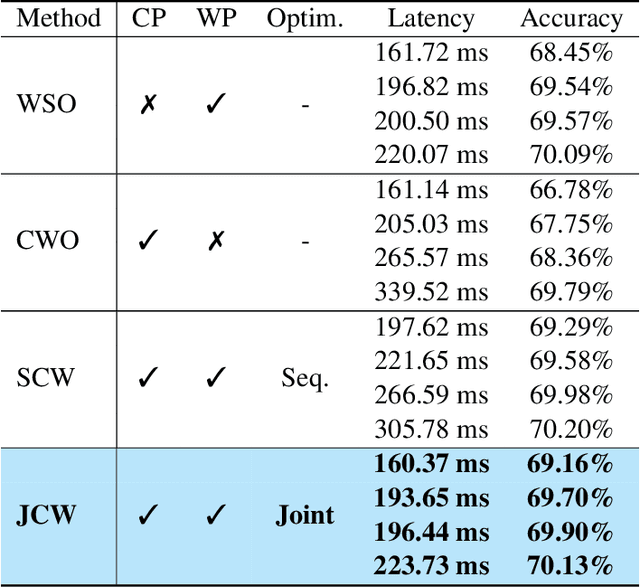
For practical deep neural network design on mobile devices, it is essential to consider the constraints incurred by the computational resources and the inference latency in various applications. Among deep network acceleration related approaches, pruning is a widely adopted practice to balance the computational resource consumption and the accuracy, where unimportant connections can be removed either channel-wisely or randomly with a minimal impact on model accuracy. The channel pruning instantly results in a significant latency reduction, while the random weight pruning is more flexible to balance the latency and accuracy. In this paper, we present a unified framework with Joint Channel pruning and Weight pruning (JCW), and achieves a better Pareto-frontier between the latency and accuracy than previous model compression approaches. To fully optimize the trade-off between the latency and accuracy, we develop a tailored multi-objective evolutionary algorithm in the JCW framework, which enables one single search to obtain the optimal candidate architectures for various deployment requirements. Extensive experiments demonstrate that the JCW achieves a better trade-off between the latency and accuracy against various state-of-the-art pruning methods on the ImageNet classification dataset. Our codes are available at https://github.com/jcw-anonymous/JCW.
Deep Keyphrase Completion
Oct 29, 2021
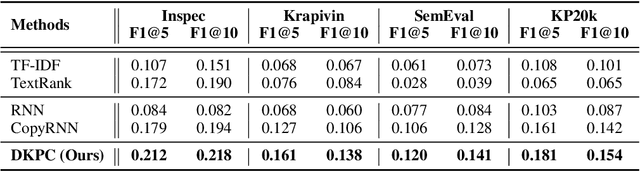
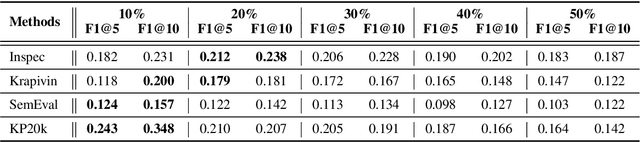

Keyphrase provides accurate information of document content that is highly compact, concise, full of meanings, and widely used for discourse comprehension, organization, and text retrieval. Though previous studies have made substantial efforts for automated keyphrase extraction and generation, surprisingly, few studies have been made for \textit{keyphrase completion} (KPC). KPC aims to generate more keyphrases for document (e.g. scientific publication) taking advantage of document content along with a very limited number of known keyphrases, which can be applied to improve text indexing system, etc. In this paper, we propose a novel KPC method with an encoder-decoder framework. We name it \textit{deep keyphrase completion} (DKPC) since it attempts to capture the deep semantic meaning of the document content together with known keyphrases via a deep learning framework. Specifically, the encoder and the decoder in DKPC play different roles to make full use of the known keyphrases. The former considers the keyphrase-guiding factors, which aggregates information of known keyphrases into context. On the contrary, the latter considers the keyphrase-inhibited factor to inhibit semantically repeated keyphrase generation. Extensive experiments on benchmark datasets demonstrate the efficacy of our proposed model.
ProxyBO: Accelerating Neural Architecture Search via Bayesian Optimization with Zero-cost Proxies
Oct 26, 2021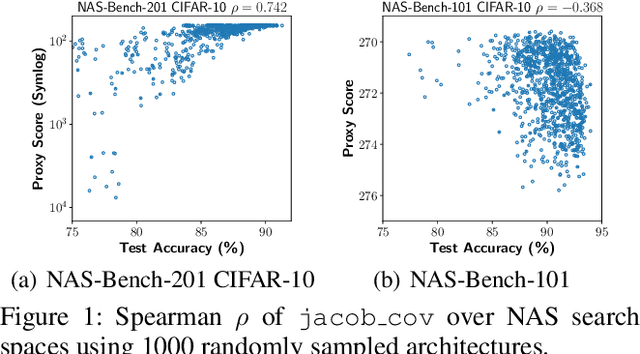
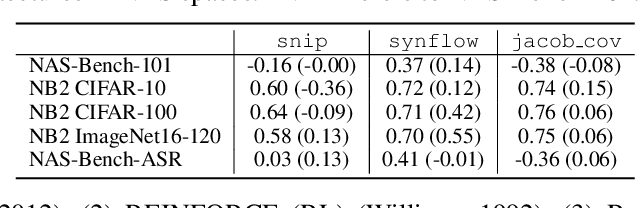
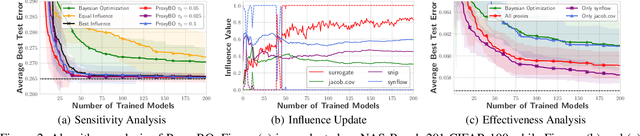
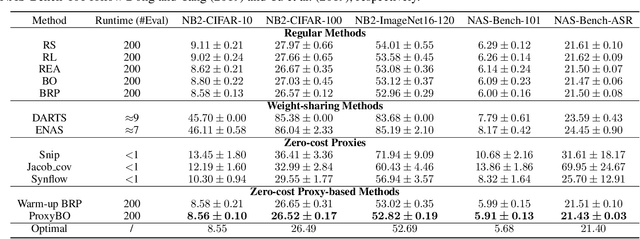
Designing neural architectures requires immense manual efforts. This has promoted the development of neural architecture search (NAS) to automate this design. While previous NAS methods achieve promising results but run slowly and zero-cost proxies run extremely fast but are less promising, recent work considers utilizing zero-cost proxies via a simple warm-up. The existing method has two limitations, which are unforeseeable reliability and one-shot usage. To address the limitations, we present ProxyBO, an efficient Bayesian optimization framework that utilizes the zero-cost proxies to accelerate neural architecture search. We propose the generalization ability measurement to estimate the fitness of proxies on the task during each iteration and then combine BO with zero-cost proxies via dynamic influence combination. Extensive empirical studies show that ProxyBO consistently outperforms competitive baselines on five tasks from three public benchmarks. Concretely, ProxyBO achieves up to 5.41x and 3.83x speedups over the state-of-the-art approach REA and BRP-NAS, respectively.
AgFlow: Fast Model Selection of Penalized PCA via Implicit Regularization Effects of Gradient Flow
Oct 07, 2021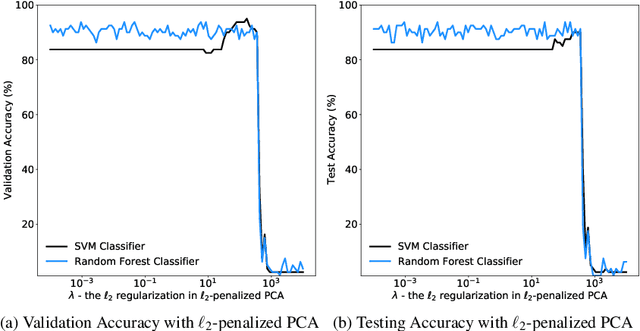
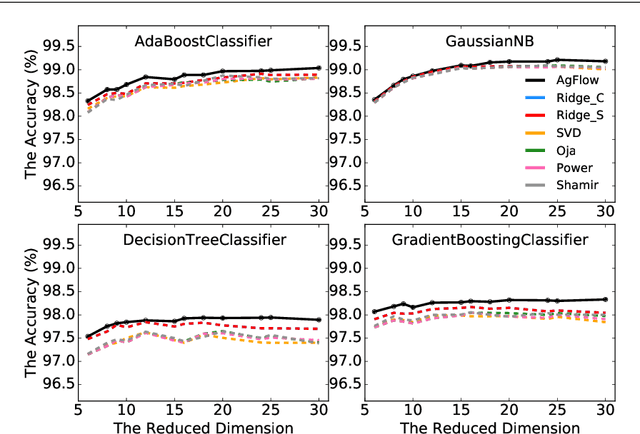
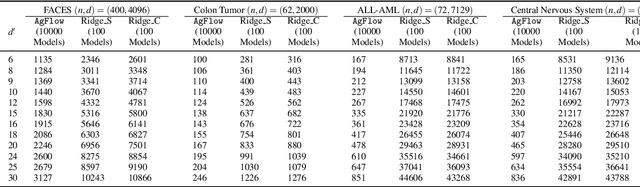
Principal component analysis (PCA) has been widely used as an effective technique for feature extraction and dimension reduction. In the High Dimension Low Sample Size (HDLSS) setting, one may prefer modified principal components, with penalized loadings, and automated penalty selection by implementing model selection among these different models with varying penalties. The earlier work [1, 2] has proposed penalized PCA, indicating the feasibility of model selection in $L_2$- penalized PCA through the solution path of Ridge regression, however, it is extremely time-consuming because of the intensive calculation of matrix inverse. In this paper, we propose a fast model selection method for penalized PCA, named Approximated Gradient Flow (AgFlow), which lowers the computation complexity through incorporating the implicit regularization effect introduced by (stochastic) gradient flow [3, 4] and obtains the complete solution path of $L_2$-penalized PCA under varying $L_2$-regularization. We perform extensive experiments on real-world datasets. AgFlow outperforms existing methods (Oja [5], Power [6], and Shamir [7] and the vanilla Ridge estimators) in terms of computation costs.
SpeechNAS: Towards Better Trade-off between Latency and Accuracy for Large-Scale Speaker Verification
Sep 18, 2021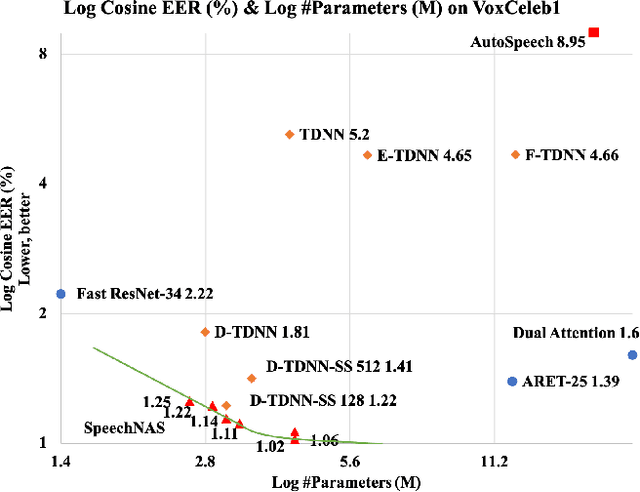
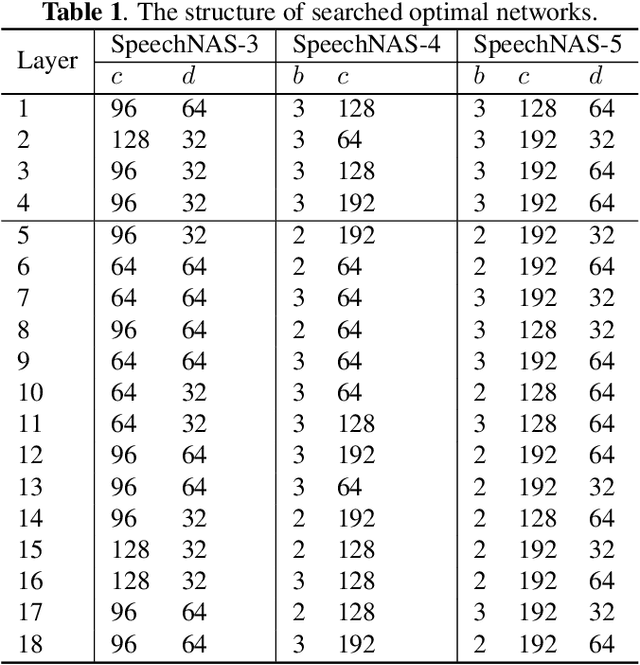
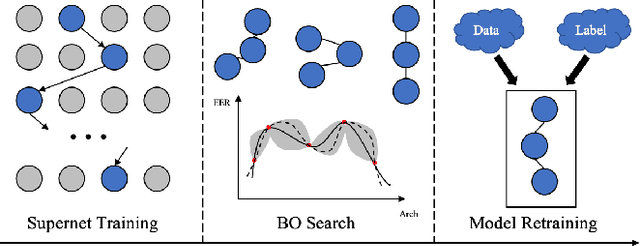
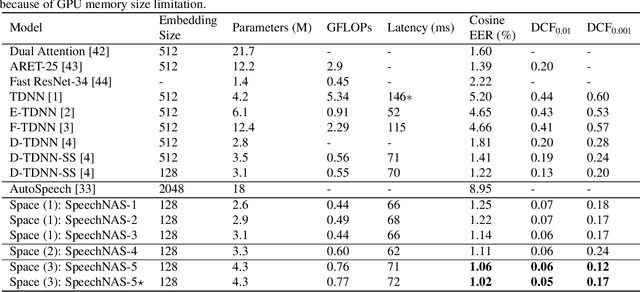
Recently, x-vector has been a successful and popular approach for speaker verification, which employs a time delay neural network (TDNN) and statistics pooling to extract speaker characterizing embedding from variable-length utterances. Improvement upon the x-vector has been an active research area, and enormous neural networks have been elaborately designed based on the x-vector, eg, extended TDNN (E-TDNN), factorized TDNN (F-TDNN), and densely connected TDNN (D-TDNN). In this work, we try to identify the optimal architectures from a TDNN based search space employing neural architecture search (NAS), named SpeechNAS. Leveraging the recent advances in the speaker recognition, such as high-order statistics pooling, multi-branch mechanism, D-TDNN and angular additive margin softmax (AAM) loss with a minimum hyper-spherical energy (MHE), SpeechNAS automatically discovers five network architectures, from SpeechNAS-1 to SpeechNAS-5, of various numbers of parameters and GFLOPs on the large-scale text-independent speaker recognition dataset VoxCeleb1. Our derived best neural network achieves an equal error rate (EER) of 1.02% on the standard test set of VoxCeleb1, which surpasses previous TDNN based state-of-the-art approaches by a large margin. Code and trained weights are in https://github.com/wentaozhu/speechnas.git
GDP: Stabilized Neural Network Pruning via Gates with Differentiable Polarization
Sep 08, 2021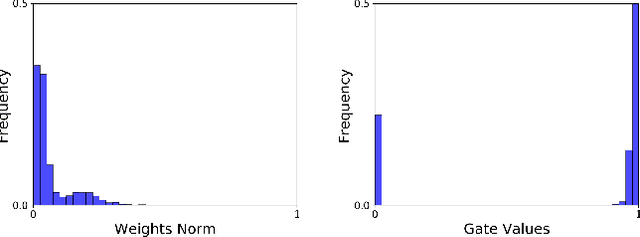

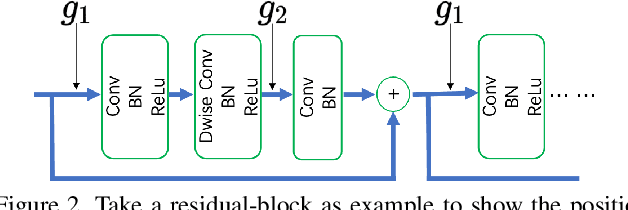
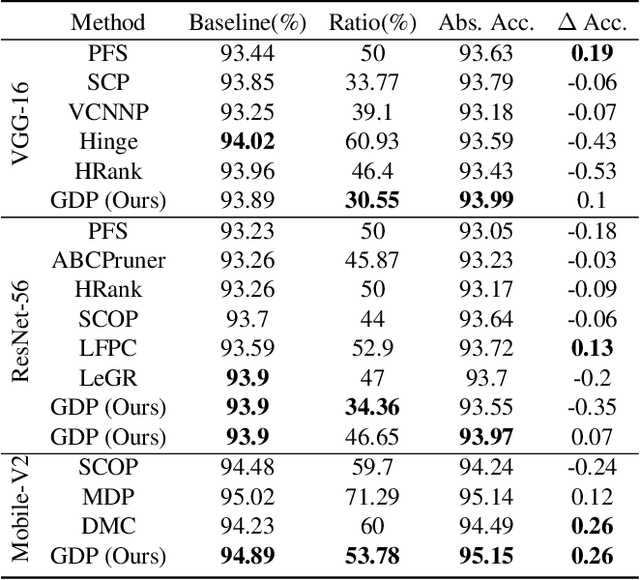
Model compression techniques are recently gaining explosive attention for obtaining efficient AI models for various real-time applications. Channel pruning is one important compression strategy and is widely used in slimming various DNNs. Previous gate-based or importance-based pruning methods aim to remove channels whose importance is smallest. However, it remains unclear what criteria the channel importance should be measured on, leading to various channel selection heuristics. Some other sampling-based pruning methods deploy sampling strategies to train sub-nets, which often causes the training instability and the compressed model's degraded performance. In view of the research gaps, we present a new module named Gates with Differentiable Polarization (GDP), inspired by principled optimization ideas. GDP can be plugged before convolutional layers without bells and whistles, to control the on-and-off of each channel or whole layer block. During the training process, the polarization effect will drive a subset of gates to smoothly decrease to exact zero, while other gates gradually stay away from zero by a large margin. When training terminates, those zero-gated channels can be painlessly removed, while other non-zero gates can be absorbed into the succeeding convolution kernel, causing completely no interruption to training nor damage to the trained model. Experiments conducted over CIFAR-10 and ImageNet datasets show that the proposed GDP algorithm achieves the state-of-the-art performance on various benchmark DNNs at a broad range of pruning ratios. We also apply GDP to DeepLabV3Plus-ResNet50 on the challenging Pascal VOC segmentation task, whose test performance sees no drop (even slightly improved) with over 60% FLOPs saving.