 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoleyGenEx: Unified Video-to-Audio Generation with Multi-Modal Control, Temporal Alignment, and Semantic Precision
Jun 12, 2026We present FoleyGenEx, a unified video-to-audio (VTA) framework integrating multi-modal control, frame-level temporal alignment, and fine-grained semantics, enabling synchronized, versatile audio synthesis for diverse tasks. Existing VTA methods either have multi-modal control but weak temporal alignment or strong alignment but lack reference audio conditioning and semantic precision. FoleyGenEx fills this gap via three core innovations: a conditional injection mechanism for audio-controlled VTA and Foley extension, a multi-modal dynamic masking strategy preserving training synchronization, and an adverb-based data augmentation algorithm leveraging signal processing and large language models to enhance textual supervision with nuanced semantics. Experiments on AudioCaps, VGGSound, and Greatest Hits demonstrate its competitive controllable VTA performance against existing methods. Demo samples are available at https://foleygenex.github.io/FoleyGenEx.
* Accepted by INTERSPEECH 2026
Audio Imitator: Controlling Timbre and Tempo in Video2Audio Synthesis with Audio Reference
Jun 05, 2026Video-to-audio generation has made significant progress in achieving semantic consistency and temporal alignment from silent videos. However, audio contains rich stylistic attributes such as timbre and tempo that are difficult to infer from visual and textual inputs alone. While reference audio can serve as additional conditioning, it is typically treated as a holistic signal, limiting fine-grained style control. We propose AudioIM, an attribute-aware framework that explicitly models timbre and tempo as separate control factors rather than relying on holistic prompt conditioning. Dual encoders extract complementary timbre-related and tempo-related representations, which are injected through global conditioning. A masking-based training strategy enables effective latent prompt conditioning at inference. Experiments on VGGSound show improved style similarity while preserving semantic alignment and synchronization. Audio samples are available at: https://anonymousdemo757.github.io/.
AudioGen-Omni: A Unified Multimodal Diffusion Transformer for Video-Synchronized Audio, Speech, and Song Generation
Aug 01, 2025



We present AudioGen-Omni - a unified approach based on multimodal diffusion transformers (MMDit), capable of generating high-fidelity audio, speech, and songs coherently synchronized with the input video. AudioGen-Omni introduces a novel joint training paradigm that seamlessly integrates large-scale video-text-audio corpora, enabling a model capable of generating semantically rich, acoustically diverse audio conditioned on multimodal inputs and adaptable to a wide range of audio generation tasks. AudioGen-Omni employs a unified lyrics-transcription encoder that encodes graphemes and phonemes from both sung and spoken inputs into dense frame-level representations. Dense frame-level representations are fused using an AdaLN-based joint attention mechanism enhanced with phase-aligned anisotropic positional infusion (PAAPI), wherein RoPE is selectively applied to temporally structured modalities to ensure precise and robust cross-modal alignment. By unfreezing all modalities and masking missing inputs, AudioGen-Omni mitigates the semantic constraints of text-frozen paradigms, enabling effective cross-modal conditioning. This joint training approach enhances audio quality, semantic alignment, and lip-sync accuracy, while also achieving state-of-the-art results on Text-to-Audio/Speech/Song tasks. With an inference time of 1.91 seconds for 8 seconds of audio, it offers substantial improvements in both efficiency and generality.
Kling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025
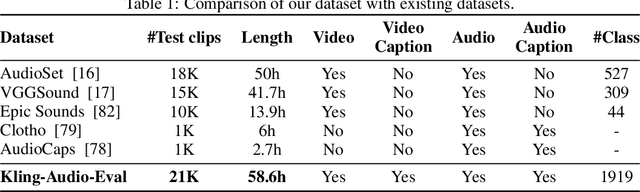
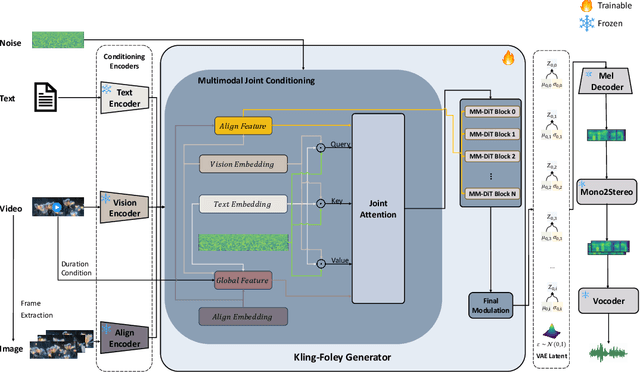
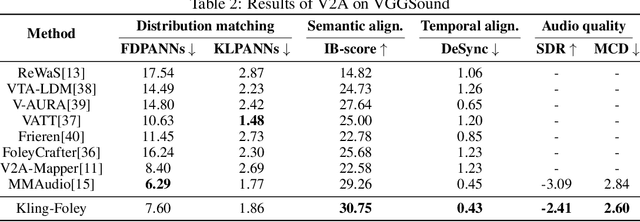
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
LAFMA: A Latent Flow Matching Model for Text-to-Audio Generation
Jun 12, 2024



Recently, the application of diffusion models has facilitated the significant development of speech and audio generation. Nevertheless, the quality of samples generated by diffusion models still needs improvement. And the effectiveness of the method is accompanied by the extensive number of sampling steps, leading to an extended synthesis time necessary for generating high-quality audio. Previous Text-to-Audio (TTA) methods mostly used diffusion models in the latent space for audio generation. In this paper, we explore the integration of the Flow Matching (FM) model into the audio latent space for audio generation. The FM is an alternative simulation-free method that trains continuous normalization flows (CNF) based on regressing vector fields. We demonstrate that our model significantly enhances the quality of generated audio samples, achieving better performance than prior models. Moreover, it reduces the number of inference steps to ten steps almost without sacrificing performance.
SpeechNAS: Towards Better Trade-off between Latency and Accuracy for Large-Scale Speaker Verification
Sep 18, 2021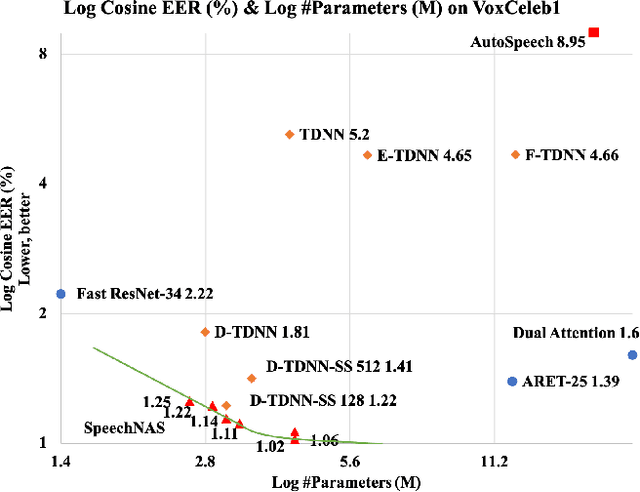
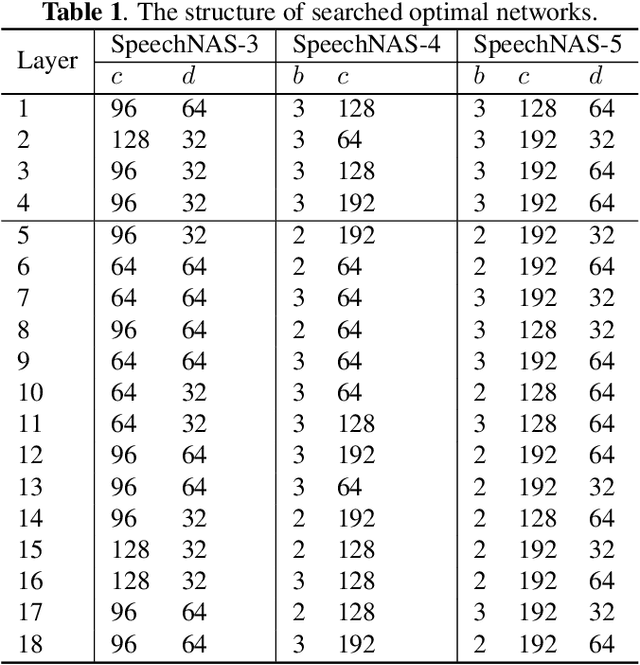
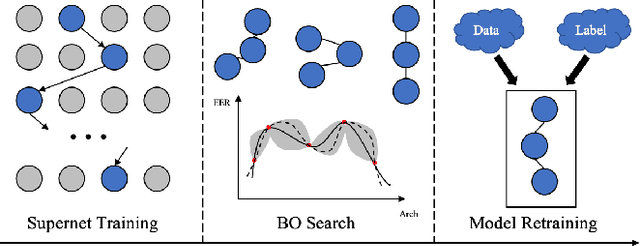
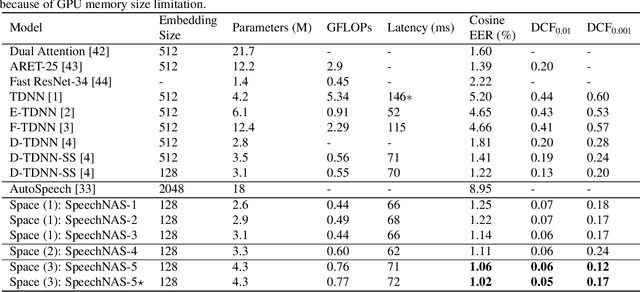
Recently, x-vector has been a successful and popular approach for speaker verification, which employs a time delay neural network (TDNN) and statistics pooling to extract speaker characterizing embedding from variable-length utterances. Improvement upon the x-vector has been an active research area, and enormous neural networks have been elaborately designed based on the x-vector, eg, extended TDNN (E-TDNN), factorized TDNN (F-TDNN), and densely connected TDNN (D-TDNN). In this work, we try to identify the optimal architectures from a TDNN based search space employing neural architecture search (NAS), named SpeechNAS. Leveraging the recent advances in the speaker recognition, such as high-order statistics pooling, multi-branch mechanism, D-TDNN and angular additive margin softmax (AAM) loss with a minimum hyper-spherical energy (MHE), SpeechNAS automatically discovers five network architectures, from SpeechNAS-1 to SpeechNAS-5, of various numbers of parameters and GFLOPs on the large-scale text-independent speaker recognition dataset VoxCeleb1. Our derived best neural network achieves an equal error rate (EER) of 1.02% on the standard test set of VoxCeleb1, which surpasses previous TDNN based state-of-the-art approaches by a large margin. Code and trained weights are in https://github.com/wentaozhu/speechnas.git
Multi-Task Audio Source Separation
Jul 14, 2021
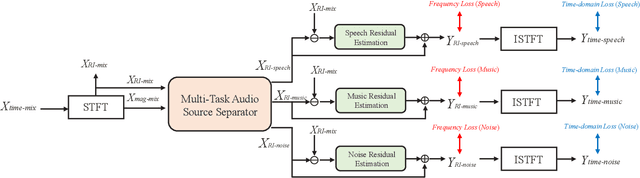

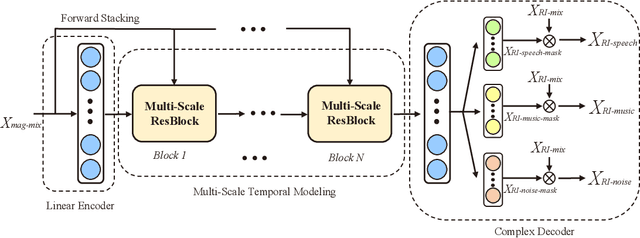
The audio source separation tasks, such as speech enhancement, speech separation, and music source separation, have achieved impressive performance in recent studies. The powerful modeling capabilities of deep neural networks give us hope for more challenging tasks. This paper launches a new multi-task audio source separation (MTASS) challenge to separate the speech, music, and noise signals from the monaural mixture. First, we introduce the details of this task and generate a dataset of mixtures containing speech, music, and background noises. Then, we propose an MTASS model in the complex domain to fully utilize the differences in spectral characteristics of the three audio signals. In detail, the proposed model follows a two-stage pipeline, which separates the three types of audio signals and then performs signal compensation separately. After comparing different training targets, the complex ratio mask is selected as a more suitable target for the MTASS. The experimental results also indicate that the residual signal compensation module helps to recover the signals further. The proposed model shows significant advantages in separation performance over several well-known separation models.