 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Keyphrase Completion
Oct 29, 2021
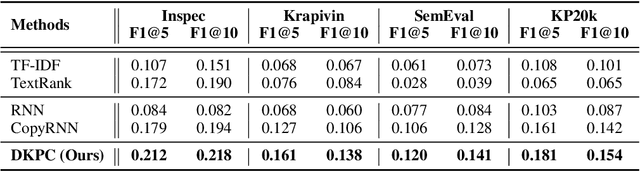
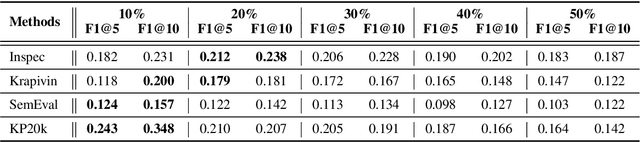

Keyphrase provides accurate information of document content that is highly compact, concise, full of meanings, and widely used for discourse comprehension, organization, and text retrieval. Though previous studies have made substantial efforts for automated keyphrase extraction and generation, surprisingly, few studies have been made for \textit{keyphrase completion} (KPC). KPC aims to generate more keyphrases for document (e.g. scientific publication) taking advantage of document content along with a very limited number of known keyphrases, which can be applied to improve text indexing system, etc. In this paper, we propose a novel KPC method with an encoder-decoder framework. We name it \textit{deep keyphrase completion} (DKPC) since it attempts to capture the deep semantic meaning of the document content together with known keyphrases via a deep learning framework. Specifically, the encoder and the decoder in DKPC play different roles to make full use of the known keyphrases. The former considers the keyphrase-guiding factors, which aggregates information of known keyphrases into context. On the contrary, the latter considers the keyphrase-inhibited factor to inhibit semantically repeated keyphrase generation. Extensive experiments on benchmark datasets demonstrate the efficacy of our proposed model.