 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevelopment and Evaluation of a Learning-based Model for Real-time Haptic Texture Rendering
Dec 27, 2022Current Virtual Reality (VR) environments lack the rich haptic signals that humans experience during real-life interactions, such as the sensation of texture during lateral movement on a surface. Adding realistic haptic textures to VR environments requires a model that generalizes to variations of a user's interaction and to the wide variety of existing textures in the world. Current methodologies for haptic texture rendering exist, but they usually develop one model per texture, resulting in low scalability. We present a deep learning-based action-conditional model for haptic texture rendering and evaluate its perceptual performance in rendering realistic texture vibrations through a multi part human user study. This model is unified over all materials and uses data from a vision-based tactile sensor (GelSight) to render the appropriate surface conditioned on the user's action in real time. For rendering texture, we use a high-bandwidth vibrotactile transducer attached to a 3D Systems Touch device. The result of our user study shows that our learning-based method creates high-frequency texture renderings with comparable or better quality than state-of-the-art methods without the need for learning a separate model per texture. Furthermore, we show that the method is capable of rendering previously unseen textures using a single GelSight image of their surface.
Active Task Randomization: Learning Visuomotor Skills for Sequential Manipulation by Proposing Feasible and Novel Tasks
Nov 11, 2022



Solving real-world sequential manipulation tasks requires robots to have a repertoire of skills applicable to a wide range of circumstances. To acquire such skills using data-driven approaches, we need massive and diverse training data which is often labor-intensive and non-trivial to collect and curate. In this work, we introduce Active Task Randomization (ATR), an approach that learns visuomotor skills for sequential manipulation by automatically creating feasible and novel tasks in simulation. During training, our approach procedurally generates tasks using a graph-based task parameterization. To adaptively estimate the feasibility and novelty of sampled tasks, we develop a relational neural network that maps each task parameter into a compact embedding. We demonstrate that our approach can automatically create suitable tasks for efficiently training the skill policies to handle diverse scenarios with a variety of objects. We evaluate our method on simulated and real-world sequential manipulation tasks by composing the learned skills using a task planner. Compared to baseline methods, the skills learned using our approach consistently achieve better success rates.
ShaSTA: Modeling Shape and Spatio-Temporal Affinities for 3D Multi-Object Tracking
Nov 08, 2022



Multi-object tracking is a cornerstone capability of any robotic system. Most approaches follow a tracking-by-detection paradigm. However, within this framework, detectors function in a low precision-high recall regime, ensuring a low number of false-negatives while producing a high rate of false-positives. This can negatively affect the tracking component by making data association and track lifecycle management more challenging. Additionally, false-negative detections due to difficult scenarios like occlusions can negatively affect tracking performance. Thus, we propose a method that learns shape and spatio-temporal affinities between consecutive frames to better distinguish between true-positive and false-positive detections and tracks, while compensating for false-negative detections. Our method provides a probabilistic matching of detections that leads to robust data association and track lifecycle management. We quantitatively evaluate our method through ablative experiments and on the nuScenes tracking benchmark where we achieve state-of-the-art results. Our method not only estimates accurate, high-quality tracks but also decreases the overall number of false-positive and false-negative tracks. Please see our project website for source code and demo videos: sites.google.com/view/shasta-3d-mot/home.
Learning Tool Morphology for Contact-Rich Manipulation Tasks with Differentiable Simulation
Nov 04, 2022When humans perform contact-rich manipulation tasks, customized tools are often necessary and play an important role in simplifying the task. For instance, in our daily life, we use various utensils for handling food, such as knives, forks and spoons. Similarly, customized tools for robots may enable them to more easily perform a variety of tasks. Here, we present an end-to-end framework to automatically learn tool morphology for contact-rich manipulation tasks by leveraging differentiable physics simulators. Previous work approached this problem by introducing manually constructed priors that required detailed specification of object 3D model, grasp pose and task description to facilitate the search or optimization. In our approach, we instead only need to define the objective with respect to the task performance and enable learning a robust morphology by randomizing the task variations. The optimization is made tractable by casting this as a continual learning problem. We demonstrate the effectiveness of our method for designing new tools in several scenarios such as winding ropes, flipping a box and pushing peas onto a scoop in simulation. We also validate that the shapes discovered by our method help real robots succeed in these scenarios.
Task-Driven In-Hand Manipulation of Unknown Objects with Tactile Sensing
Oct 28, 2022



Manipulation of objects in-hand without an object model is a foundational skill for many tasks in unstructured environments. In many cases, vision-only approaches may not be feasible; for example, due to occlusion in cluttered spaces. In this paper, we introduce a method to reorient unknown objects by incrementally building a probabilistic estimate of the object shape and pose during task-driven manipulation. Our method leverages Bayesian optimization to strategically trade-off exploration of the global object shape with efficient task completion. We demonstrate our approach on a Tactile-Enabled Roller Grasper, a gripper that rolls objects in hand while continuously collecting tactile data. We evaluate our method in simulation on a set of randomly generated objects and find that our method reliably reorients objects while significantly reducing the exploration time needed to do so. On the Roller Grasper hardware, we show successful qualitative reconstruction of the object model. In summary, this work (1) presents a system capable of simultaneously learning unknown 3D object shape and pose using tactile sensing; and (2) demonstrates that task-driven exploration results in more efficient object manipulation than the common paradigm of complete object exploration before task-completion.
Minkowski Tracker: A Sparse Spatio-Temporal R-CNN for Joint Object Detection and Tracking
Aug 26, 2022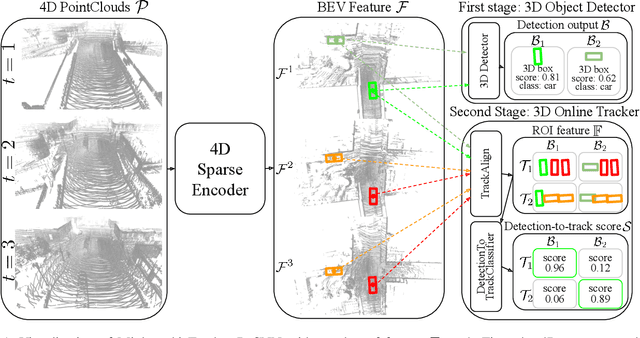
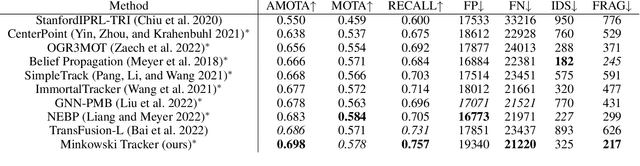
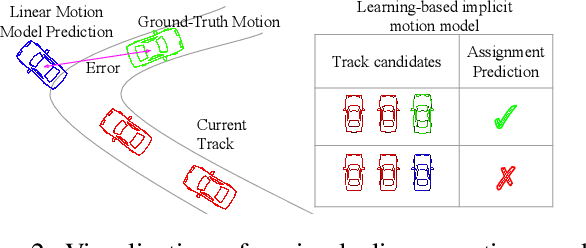
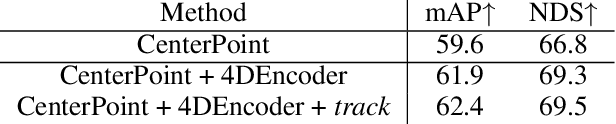
Recent research in multi-task learning reveals the benefit of solving related problems in a single neural network. 3D object detection and multi-object tracking (MOT) are two heavily intertwined problems predicting and associating an object instance location across time. However, most previous works in 3D MOT treat the detector as a preceding separated pipeline, disjointly taking the output of the detector as an input to the tracker. In this work, we present Minkowski Tracker, a sparse spatio-temporal R-CNN that jointly solves object detection and tracking. Inspired by region-based CNN (R-CNN), we propose to solve tracking as a second stage of the object detector R-CNN that predicts assignment probability to tracks. First, Minkowski Tracker takes 4D point clouds as input to generate a spatio-temporal Bird's-eye-view (BEV) feature map through a 4D sparse convolutional encoder network. Then, our proposed TrackAlign aggregates the track region-of-interest (ROI) features from the BEV features. Finally, Minkowski Tracker updates the track and its confidence score based on the detection-to-track match probability predicted from the ROI features. We show in large-scale experiments that the overall performance gain of our method is due to four factors: 1. The temporal reasoning of the 4D encoder improves the detection performance 2. The multi-task learning of object detection and MOT jointly enhances each other 3. The detection-to-track match score learns implicit motion model to enhance track assignment 4. The detection-to-track match score improves the quality of the track confidence score. As a result, Minkowski Tracker achieved the state-of-the-art performance on Nuscenes dataset tracking task without hand-designed motion models.
Deep Learning Approaches to Grasp Synthesis: A Review
Jul 06, 2022


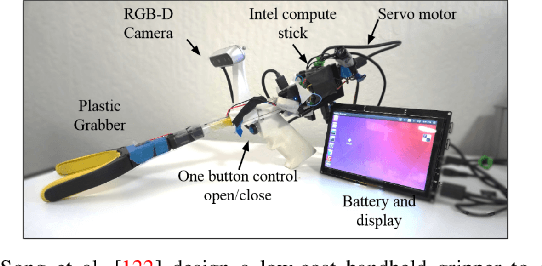
Grasping is the process of picking an object by applying forces and torques at a set of contacts. Recent advances in deep-learning methods have allowed rapid progress in robotic object grasping. We systematically surveyed the publications over the last decade, with a particular interest in grasping an object using all 6 degrees of freedom of the end-effector pose. Our review found four common methodologies for robotic grasping: sampling-based approaches, direct regression, reinforcement learning, and exemplar approaches. Furthermore, we found two 'supporting methods' around grasping that use deep-learning to support the grasping process, shape approximation, and affordances. We have distilled the publications found in this systematic review (85 papers) into ten key takeaways we consider crucial for future robotic grasping and manipulation research. An online version of the survey is available at https://rhys-newbury.github.io/projects/6dof/
Rethinking Optimization with Differentiable Simulation from a Global Perspective
Jun 28, 2022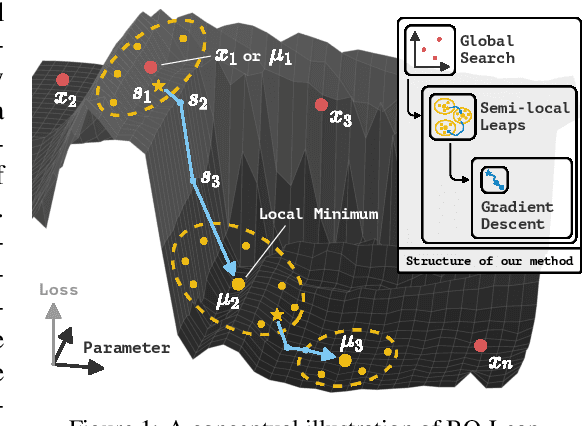

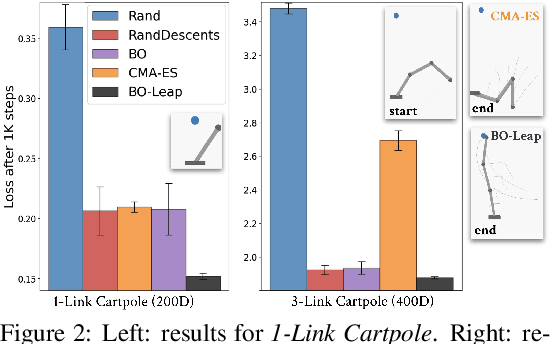
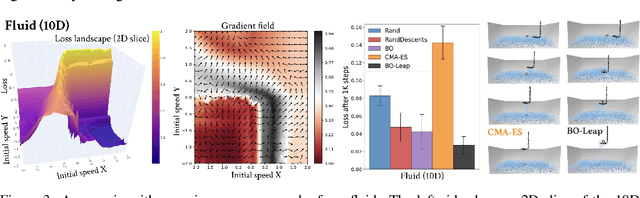
Differentiable simulation is a promising toolkit for fast gradient-based policy optimization and system identification. However, existing approaches to differentiable simulation have largely tackled scenarios where obtaining smooth gradients has been relatively easy, such as systems with mostly smooth dynamics. In this work, we study the challenges that differentiable simulation presents when it is not feasible to expect that a single descent reaches a global optimum, which is often a problem in contact-rich scenarios. We analyze the optimization landscapes of diverse scenarios that contain both rigid bodies and deformable objects. In dynamic environments with highly deformable objects and fluids, differentiable simulators produce rugged landscapes with nonetheless useful gradients in some parts of the space. We propose a method that combines Bayesian optimization with semi-local 'leaps' to obtain a global search method that can use gradients effectively, while also maintaining robust performance in regions with noisy gradients. We show that our approach outperforms several gradient-based and gradient-free baselines on an extensive set of experiments in simulation, and also validate the method using experiments with a real robot and deformables. Videos and supplementary materials are available at https://tinyurl.com/globdiff
Visuomotor Control in Multi-Object Scenes Using Object-Aware Representations
May 12, 2022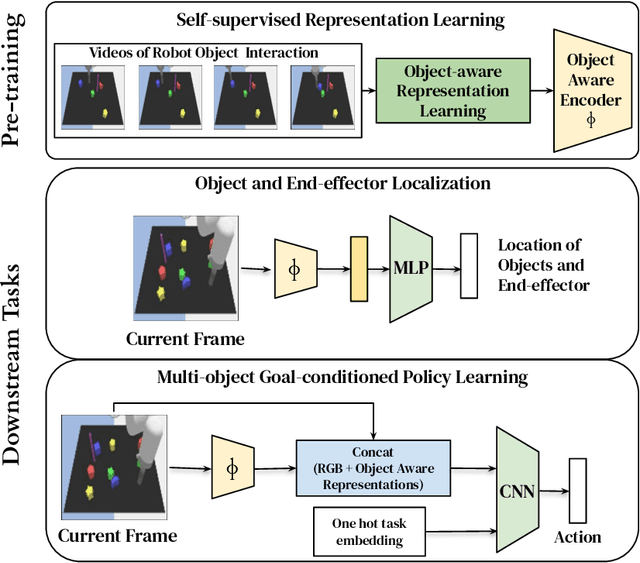
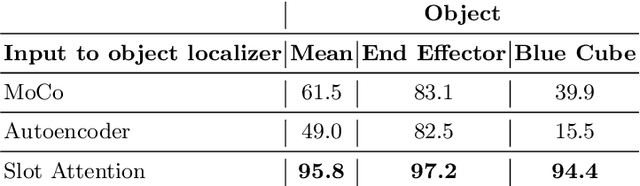

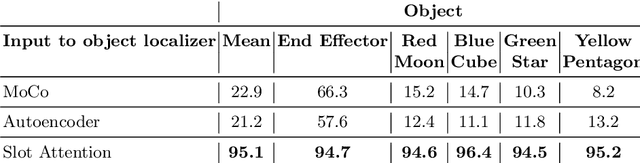
Perceptual understanding of the scene and the relationship between its different components is important for successful completion of robotic tasks. Representation learning has been shown to be a powerful technique for this, but most of the current methodologies learn task specific representations that do not necessarily transfer well to other tasks. Furthermore, representations learned by supervised methods require large labeled datasets for each task that are expensive to collect in the real world. Using self-supervised learning to obtain representations from unlabeled data can mitigate this problem. However, current self-supervised representation learning methods are mostly object agnostic, and we demonstrate that the resulting representations are insufficient for general purpose robotics tasks as they fail to capture the complexity of scenes with many components. In this paper, we explore the effectiveness of using object-aware representation learning techniques for robotic tasks. Our self-supervised representations are learned by observing the agent freely interacting with different parts of the environment and is queried in two different settings: (i) policy learning and (ii) object location prediction. We show that our model learns control policies in a sample-efficient manner and outperforms state-of-the-art object agnostic techniques as well as methods trained on raw RGB images. Our results show a 20 percent increase in performance in low data regimes (1000 trajectories) in policy training using implicit behavioral cloning (IBC). Furthermore, our method outperforms the baselines for the task of object localization in multi-object scenes.
Category-Independent Articulated Object Tracking with Factor Graphs
May 07, 2022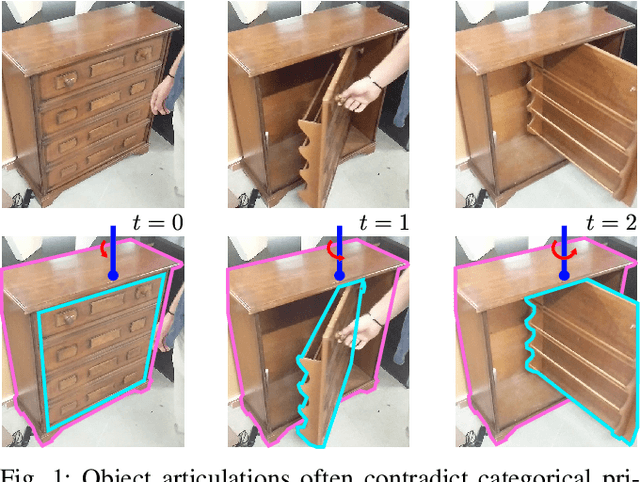
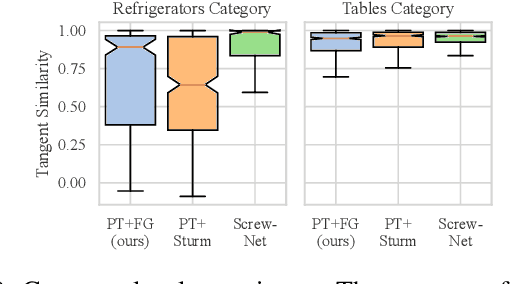
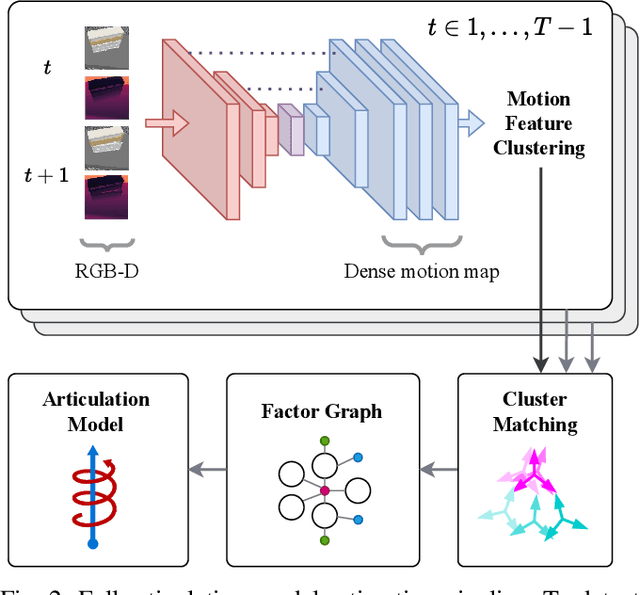
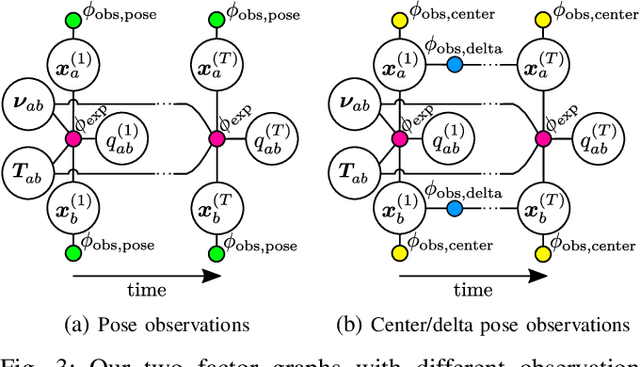
Robots deployed in human-centric environments may need to manipulate a diverse range of articulated objects, such as doors, dishwashers, and cabinets. Articulated objects often come with unexpected articulation mechanisms that are inconsistent with categorical priors: for example, a drawer might rotate about a hinge joint instead of sliding open. We propose a category-independent framework for predicting the articulation models of unknown objects from sequences of RGB-D images. The prediction is performed by a two-step process: first, a visual perception module tracks object part poses from raw images, and second, a factor graph takes these poses and infers the articulation model including the current configuration between the parts as a 6D twist. We also propose a manipulation-oriented metric to evaluate predicted joint twists in terms of how well a compliant robot controller would be able to manipulate the articulated object given the predicted twist. We demonstrate that our visual perception and factor graph modules outperform baselines on simulated data and show the applicability of our factor graph on real world data.