 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrence without Recurrence: Stable Video Landmark Detection with Deep Equilibrium Models
Apr 02, 2023Cascaded computation, whereby predictions are recurrently refined over several stages, has been a persistent theme throughout the development of landmark detection models. In this work, we show that the recently proposed Deep Equilibrium Model (DEQ) can be naturally adapted to this form of computation. Our Landmark DEQ (LDEQ) achieves state-of-the-art performance on the challenging WFLW facial landmark dataset, reaching $3.92$ NME with fewer parameters and a training memory cost of $\mathcal{O}(1)$ in the number of recurrent modules. Furthermore, we show that DEQs are particularly suited for landmark detection in videos. In this setting, it is typical to train on still images due to the lack of labelled videos. This can lead to a ``flickering'' effect at inference time on video, whereby a model can rapidly oscillate between different plausible solutions across consecutive frames. By rephrasing DEQs as a constrained optimization, we emulate recurrence at inference time, despite not having access to temporal data at training time. This Recurrence without Recurrence (RwR) paradigm helps in reducing landmark flicker, which we demonstrate by introducing a new metric, normalized mean flicker (NMF), and contributing a new facial landmark video dataset (WFLW-V) targeting landmark uncertainty. On the WFLW-V hard subset made up of $500$ videos, our LDEQ with RwR improves the NME and NMF by $10$ and $13\%$ respectively, compared to the strongest previously published model using a hand-tuned conventional filter.
BundleSDF: Neural 6-DoF Tracking and 3D Reconstruction of Unknown Objects
Mar 24, 2023We present a near real-time method for 6-DoF tracking of an unknown object from a monocular RGBD video sequence, while simultaneously performing neural 3D reconstruction of the object. Our method works for arbitrary rigid objects, even when visual texture is largely absent. The object is assumed to be segmented in the first frame only. No additional information is required, and no assumption is made about the interaction agent. Key to our method is a Neural Object Field that is learned concurrently with a pose graph optimization process in order to robustly accumulate information into a consistent 3D representation capturing both geometry and appearance. A dynamic pool of posed memory frames is automatically maintained to facilitate communication between these threads. Our approach handles challenging sequences with large pose changes, partial and full occlusion, untextured surfaces, and specular highlights. We show results on HO3D, YCBInEOAT, and BEHAVE datasets, demonstrating that our method significantly outperforms existing approaches. Project page: https://bundlesdf.github.io
Score-based Diffusion Models in Function Space
Feb 14, 2023



Diffusion models have recently emerged as a powerful framework for generative modeling. They consist of a forward process that perturbs input data with Gaussian white noise and a reverse process that learns a score function to generate samples by denoising. Despite their tremendous success, they are mostly formulated on finite-dimensional spaces, e.g. Euclidean, limiting their applications to many domains where the data has a functional form such as in scientific computing and 3D geometric data analysis. In this work, we introduce a mathematically rigorous framework called Denoising Diffusion Operators (DDOs) for training diffusion models in function space. In DDOs, the forward process perturbs input functions gradually using a Gaussian process. The generative process is formulated by integrating a function-valued Langevin dynamic. Our approach requires an appropriate notion of the score for the perturbed data distribution, which we obtain by generalizing denoising score matching to function spaces that can be infinite-dimensional. We show that the corresponding discretized algorithm generates accurate samples at a fixed cost that is independent of the data resolution. We theoretically and numerically verify the applicability of our approach on a set of problems, including generating solutions to the Navier-Stokes equation viewed as the push-forward distribution of forcings from a Gaussian Random Field (GRF).
PhysDiff: Physics-Guided Human Motion Diffusion Model
Dec 09, 2022Denoising diffusion models hold great promise for generating diverse and realistic human motions. However, existing motion diffusion models largely disregard the laws of physics in the diffusion process and often generate physically-implausible motions with pronounced artifacts such as floating, foot sliding, and ground penetration. This seriously impacts the quality of generated motions and limits their real-world application. To address this issue, we present a novel physics-guided motion diffusion model (PhysDiff), which incorporates physical constraints into the diffusion process. Specifically, we propose a physics-based motion projection module that uses motion imitation in a physics simulator to project the denoised motion of a diffusion step to a physically-plausible motion. The projected motion is further used in the next diffusion step to guide the denoising diffusion process. Intuitively, the use of physics in our model iteratively pulls the motion toward a physically-plausible space. Experiments on large-scale human motion datasets show that our approach achieves state-of-the-art motion quality and improves physical plausibility drastically (>78% for all datasets).
RANA: Relightable Articulated Neural Avatars
Dec 06, 2022



We propose RANA, a relightable and articulated neural avatar for the photorealistic synthesis of humans under arbitrary viewpoints, body poses, and lighting. We only require a short video clip of the person to create the avatar and assume no knowledge about the lighting environment. We present a novel framework to model humans while disentangling their geometry, texture, and also lighting environment from monocular RGB videos. To simplify this otherwise ill-posed task we first estimate the coarse geometry and texture of the person via SMPL+D model fitting and then learn an articulated neural representation for photorealistic image generation. RANA first generates the normal and albedo maps of the person in any given target body pose and then uses spherical harmonics lighting to generate the shaded image in the target lighting environment. We also propose to pretrain RANA using synthetic images and demonstrate that it leads to better disentanglement between geometry and texture while also improving robustness to novel body poses. Finally, we also present a new photorealistic synthetic dataset, Relighting Humans, to quantitatively evaluate the performance of the proposed approach.
Learning to Relight Portrait Images via a Virtual Light Stage and Synthetic-to-Real Adaptation
Sep 21, 2022



Given a portrait image of a person and an environment map of the target lighting, portrait relighting aims to re-illuminate the person in the image as if the person appeared in an environment with the target lighting. To achieve high-quality results, recent methods rely on deep learning. An effective approach is to supervise the training of deep neural networks with a high-fidelity dataset of desired input-output pairs, captured with a light stage. However, acquiring such data requires an expensive special capture rig and time-consuming efforts, limiting access to only a few resourceful laboratories. To address the limitation, we propose a new approach that can perform on par with the state-of-the-art (SOTA) relighting methods without requiring a light stage. Our approach is based on the realization that a successful relighting of a portrait image depends on two conditions. First, the method needs to mimic the behaviors of physically-based relighting. Second, the output has to be photorealistic. To meet the first condition, we propose to train the relighting network with training data generated by a virtual light stage that performs physically-based rendering on various 3D synthetic humans under different environment maps. To meet the second condition, we develop a novel synthetic-to-real approach to bring photorealism to the relighting network output. In addition to achieving SOTA results, our approach offers several advantages over the prior methods, including controllable glares on glasses and more temporally-consistent results for relighting videos.
* To appear in ACM Transactions on Graphics (SIGGRAPH Asia 2022). 21 pages, 25 figures, 7 tables. Project page: https://deepimagination.cc/Lumos/
Neural Light Field Estimation for Street Scenes with Differentiable Virtual Object Insertion
Aug 19, 2022
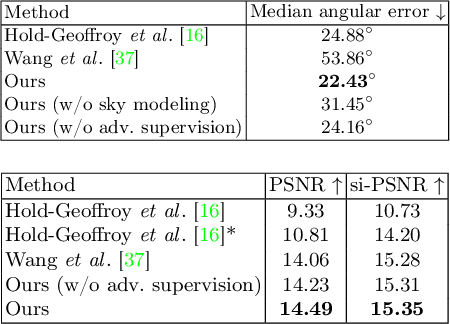


We consider the challenging problem of outdoor lighting estimation for the goal of photorealistic virtual object insertion into photographs. Existing works on outdoor lighting estimation typically simplify the scene lighting into an environment map which cannot capture the spatially-varying lighting effects in outdoor scenes. In this work, we propose a neural approach that estimates the 5D HDR light field from a single image, and a differentiable object insertion formulation that enables end-to-end training with image-based losses that encourage realism. Specifically, we design a hybrid lighting representation tailored to outdoor scenes, which contains an HDR sky dome that handles the extreme intensity of the sun, and a volumetric lighting representation that models the spatially-varying appearance of the surrounding scene. With the estimated lighting, our shadow-aware object insertion is fully differentiable, which enables adversarial training over the composited image to provide additional supervisory signal to the lighting prediction. We experimentally demonstrate that our hybrid lighting representation is more performant than existing outdoor lighting estimation methods. We further show the benefits of our AR object insertion in an autonomous driving application, where we obtain performance gains for a 3D object detector when trained on our augmented data.
* Webpage: https://nv-tlabs.github.io/outdoor-ar/
Global Context Vision Transformers
Jun 20, 2022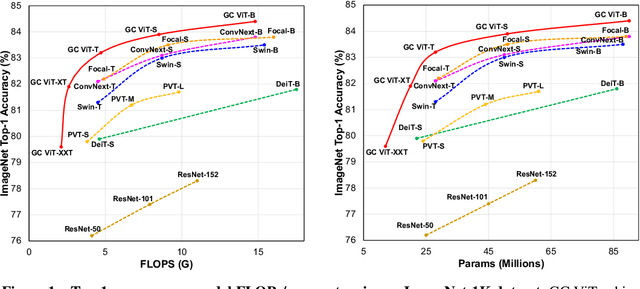
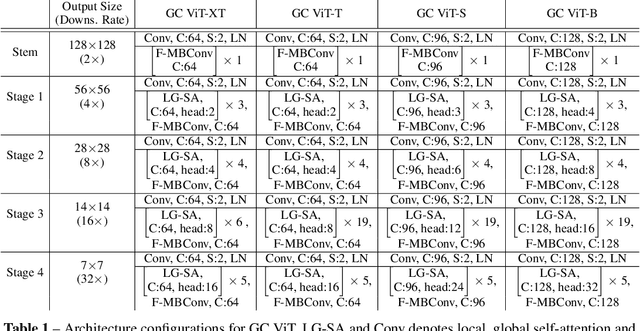
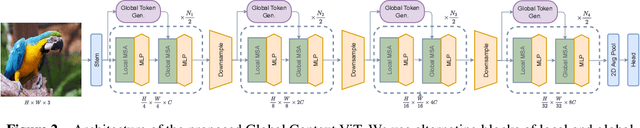
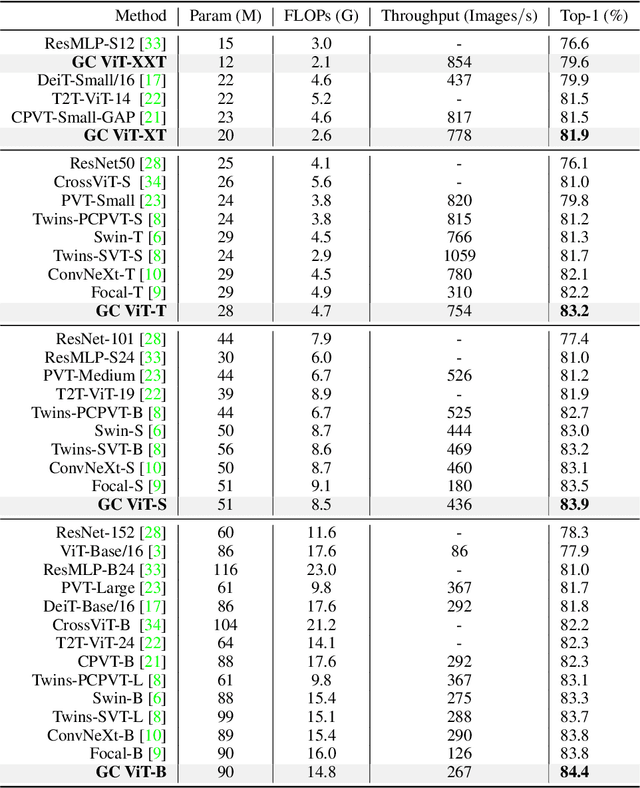
We propose global context vision transformer (GC ViT), a novel architecture that enhances parameter and compute utilization. Our method leverages global context self-attention modules, joint with local self-attention, to effectively yet efficiently model both long and short-range spatial interactions, without the need for expensive operations such as computing attention masks or shifting local windows. In addition, we address the issue of lack of the inductive bias in ViTs via proposing to use a modified fused inverted residual blocks in our architecture. Our proposed GC ViT achieves state-of-the-art results across image classification, object detection and semantic segmentation tasks. On ImageNet-1K dataset for classification, the base, small and tiny variants of GC ViT with $28$M, $51$M and $90$M parameters achieve $\textbf{83.2\%}$, $\textbf{83.9\%}$ and $\textbf{84.4\%}$ Top-1 accuracy, respectively, surpassing comparably-sized prior art such as CNN-based ConvNeXt and ViT-based Swin Transformer by a large margin. Pre-trained GC ViT backbones in downstream tasks of object detection, instance segmentation, and semantic segmentation using MS COCO and ADE20K datasets outperform prior work consistently, sometimes by large margins. Code available at https://github.com/NVlabs/GCViT.
RTMV: A Ray-Traced Multi-View Synthetic Dataset for Novel View Synthesis
May 14, 2022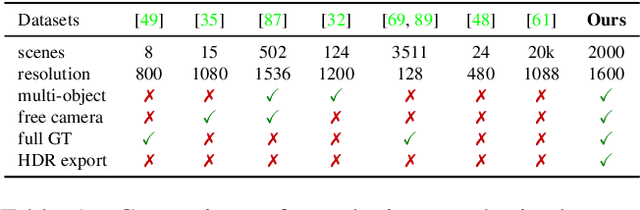


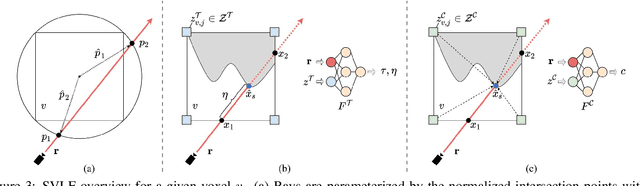
We present a large-scale synthetic dataset for novel view synthesis consisting of ~300k images rendered from nearly 2000 complex scenes using high-quality ray tracing at high resolution (1600 x 1600 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis, thus providing a large unified benchmark for both training and evaluation. Using 4 distinct sources of high-quality 3D meshes, the scenes of our dataset exhibit challenging variations in camera views, lighting, shape, materials, and textures. Because our dataset is too large for existing methods to process, we propose Sparse Voxel Light Field (SVLF), an efficient voxel-based light field approach for novel view synthesis that achieves comparable performance to NeRF on synthetic data, while being an order of magnitude faster to train and two orders of magnitude faster to render. SVLF achieves this speed by relying on a sparse voxel octree, careful voxel sampling (requiring only a handful of queries per ray), and reduced network structure; as well as ground truth depth maps at training time. Our dataset is generated by NViSII, a Python-based ray tracing renderer, which is designed to be simple for non-experts to use and share, flexible and powerful through its use of scripting, and able to create high-quality and physically-based rendered images. Experiments with a subset of our dataset allow us to compare standard methods like NeRF and mip-NeRF for single-scene modeling, and pixelNeRF for category-level modeling, pointing toward the need for future improvements in this area.
CoordGAN: Self-Supervised Dense Correspondences Emerge from GANs
Mar 30, 2022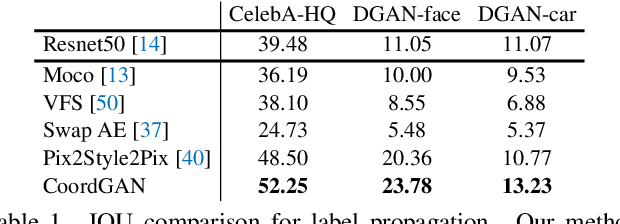
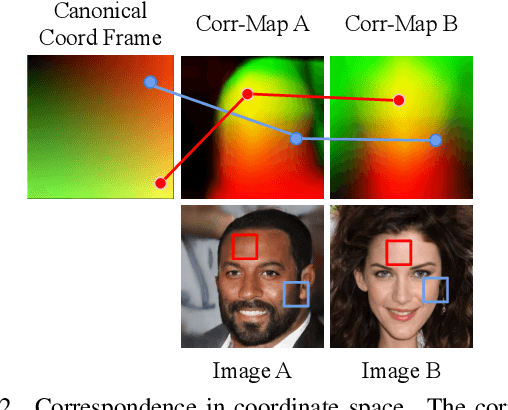
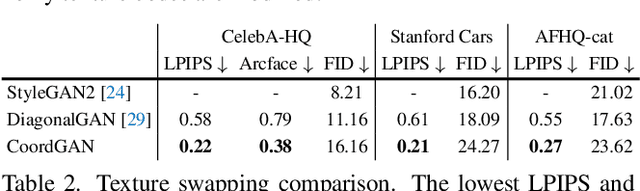
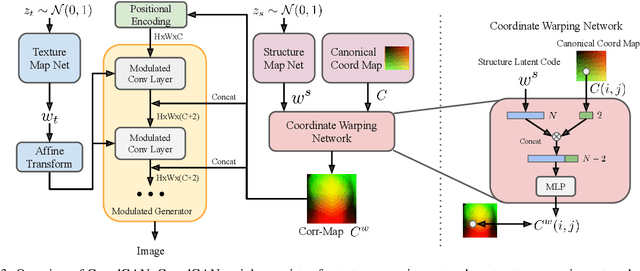
Recent advances show that Generative Adversarial Networks (GANs) can synthesize images with smooth variations along semantically meaningful latent directions, such as pose, expression, layout, etc. While this indicates that GANs implicitly learn pixel-level correspondences across images, few studies explored how to extract them explicitly. In this work, we introduce Coordinate GAN (CoordGAN), a structure-texture disentangled GAN that learns a dense correspondence map for each generated image. We represent the correspondence maps of different images as warped coordinate frames transformed from a canonical coordinate frame, i.e., the correspondence map, which describes the structure (e.g., the shape of a face), is controlled via a transformation. Hence, finding correspondences boils down to locating the same coordinate in different correspondence maps. In CoordGAN, we sample a transformation to represent the structure of a synthesized instance, while an independent texture branch is responsible for rendering appearance details orthogonal to the structure. Our approach can also extract dense correspondence maps for real images by adding an encoder on top of the generator. We quantitatively demonstrate the quality of the learned dense correspondences through segmentation mask transfer on multiple datasets. We also show that the proposed generator achieves better structure and texture disentanglement compared to existing approaches. Project page: https://jitengmu.github.io/CoordGAN/