 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Analysis on Transparent Algorithmic Exploration in Recommender Systems
Aug 12, 2021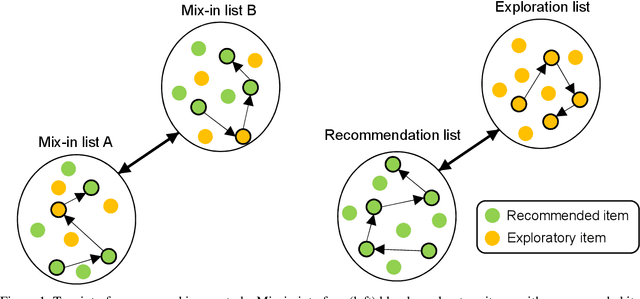

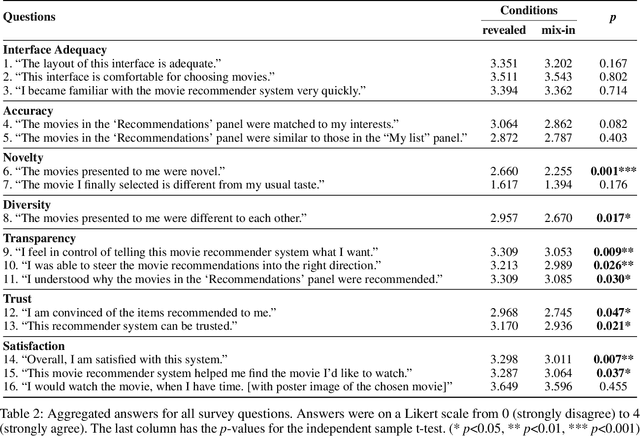
All learning algorithms for recommendations face inevitable and critical trade-off between exploiting partial knowledge of a user's preferences for short-term satisfaction and exploring additional user preferences for long-term coverage. Although exploration is indispensable for long success of a recommender system, the exploration has been considered as the risk to decrease user satisfaction. The reason for the risk is that items chosen for exploration frequently mismatch with the user's interests. To mitigate this risk, recommender systems have mixed items chosen for exploration into a recommendation list, disguising the items as recommendations to elicit feedback on the items to discover the user's additional tastes. This mix-in approach has been widely used in many recommenders, but there is rare research, evaluating the effectiveness of the mix-in approach or proposing a new approach for eliciting user feedback without deceiving users. In this work, we aim to propose a new approach for feedback elicitation without any deception and compare our approach to the conventional mix-in approach for evaluation. To this end, we designed a recommender interface that reveals which items are for exploration and conducted a within-subject study with 94 MTurk workers. Our results indicated that users left significantly more feedback on items chosen for exploration with our interface. Besides, users evaluated that our new interface is better than the conventional mix-in interface in terms of novelty, diversity, transparency, trust, and satisfaction. Finally, path analysis show that, in only our new interface, exploration caused to increase user-centric evaluation metrics. Our work paves the way for how to design an interface, which utilizes learning algorithm based on users' feedback signals, giving better user experience and gathering more feedback data.
Neural 3D Clothes Retargeting from a Single Image
Jan 29, 2021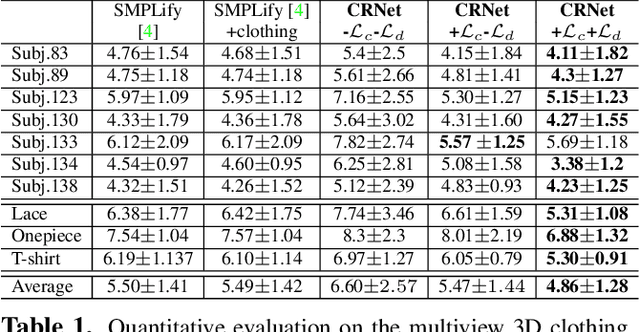

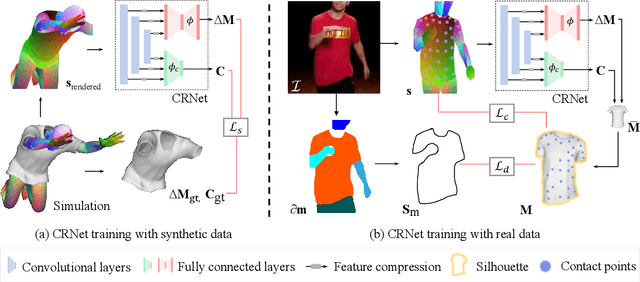
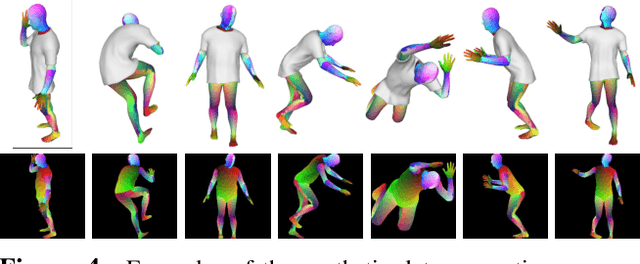
In this paper, we present a method of clothes retargeting; generating the potential poses and deformations of a given 3D clothing template model to fit onto a person in a single RGB image. The problem is fundamentally ill-posed as attaining the ground truth data is impossible, i.e., images of people wearing the different 3D clothing template model at exact same pose. We address this challenge by utilizing large-scale synthetic data generated from physical simulation, allowing us to map 2D dense body pose to 3D clothing deformation. With the simulated data, we propose a semi-supervised learning framework that validates the physical plausibility of the 3D deformation by matching with the prescribed body-to-cloth contact points and clothing silhouette to fit onto the unlabeled real images. A new neural clothes retargeting network (CRNet) is designed to integrate the semi-supervised retargeting task in an end-to-end fashion. In our evaluation, we show that our method can predict the realistic 3D pose and deformation field needed for retargeting clothes models in real-world examples.
Online Adaptation for Consistent Mesh Reconstruction in the Wild
Dec 06, 2020

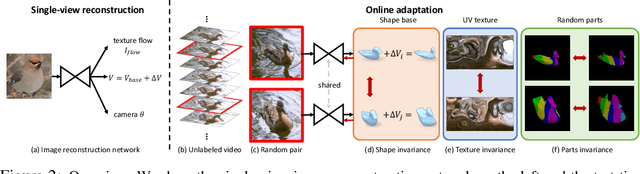
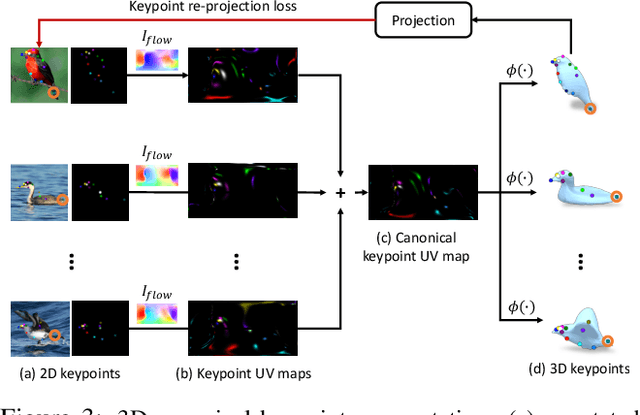
This paper presents an algorithm to reconstruct temporally consistent 3D meshes of deformable object instances from videos in the wild. Without requiring annotations of 3D mesh, 2D keypoints, or camera pose for each video frame, we pose video-based reconstruction as a self-supervised online adaptation problem applied to any incoming test video. We first learn a category-specific 3D reconstruction model from a collection of single-view images of the same category that jointly predicts the shape, texture, and camera pose of an image. Then, at inference time, we adapt the model to a test video over time using self-supervised regularization terms that exploit temporal consistency of an object instance to enforce that all reconstructed meshes share a common texture map, a base shape, as well as parts. We demonstrate that our algorithm recovers temporally consistent and reliable 3D structures from videos of non-rigid objects including those of animals captured in the wild -- an extremely challenging task rarely addressed before.
DeepGMR: Learning Latent Gaussian Mixture Models for Registration
Aug 20, 2020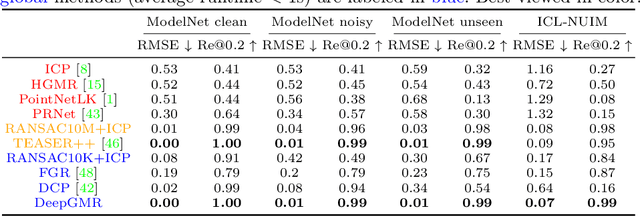
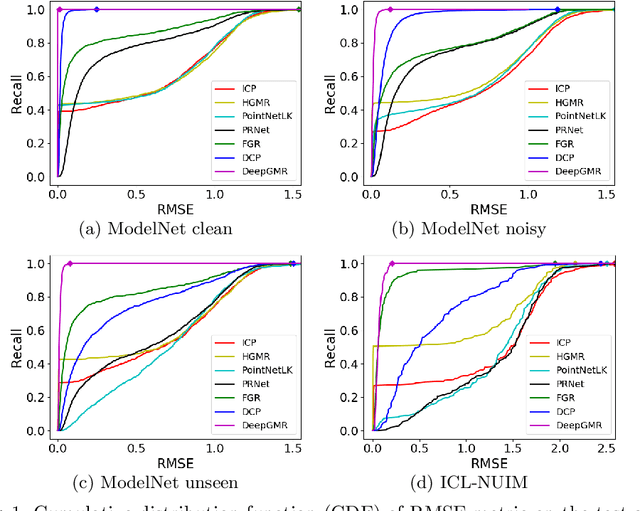
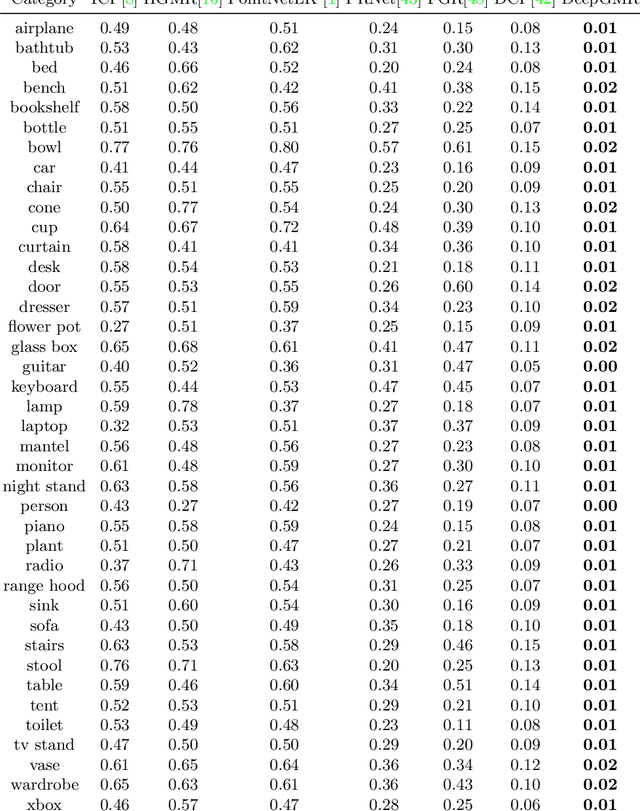
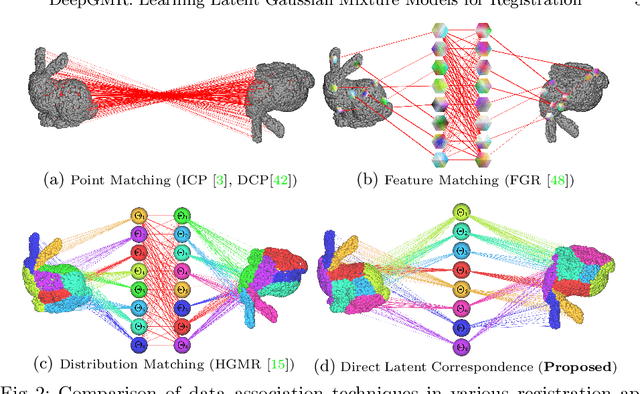
Point cloud registration is a fundamental problem in 3D computer vision, graphics and robotics. For the last few decades, existing registration algorithms have struggled in situations with large transformations, noise, and time constraints. In this paper, we introduce Deep Gaussian Mixture Registration (DeepGMR), the first learning-based registration method that explicitly leverages a probabilistic registration paradigm by formulating registration as the minimization of KL-divergence between two probability distributions modeled as mixtures of Gaussians. We design a neural network that extracts pose-invariant correspondences between raw point clouds and Gaussian Mixture Model (GMM) parameters and two differentiable compute blocks that recover the optimal transformation from matched GMM parameters. This construction allows the network learn an SE(3)-invariant feature space, producing a global registration method that is real-time, generalizable, and robust to noise. Across synthetic and real-world data, our proposed method shows favorable performance when compared with state-of-the-art geometry-based and learning-based registration methods.
Bi3D: Stereo Depth Estimation via Binary Classifications
Jun 01, 2020Stereo-based depth estimation is a cornerstone of computer vision, with state-of-the-art methods delivering accurate results in real time. For several applications such as autonomous navigation, however, it may be useful to trade accuracy for lower latency. We present Bi3D, a method that estimates depth via a series of binary classifications. Rather than testing if objects are at a particular depth $D$, as existing stereo methods do, it classifies them as being closer or farther than $D$. This property offers a powerful mechanism to balance accuracy and latency. Given a strict time budget, Bi3D can detect objects closer than a given distance in as little as a few milliseconds, or estimate depth with arbitrarily coarse quantization, with complexity linear with the number of quantization levels. Bi3D can also use the allotted quantization levels to get continuous depth, but in a specific depth range. For standard stereo (i.e., continuous depth on the whole range), our method is close to or on par with state-of-the-art, finely tuned stereo methods.
Novel View Synthesis of Dynamic Scenes with Globally Coherent Depths from a Monocular Camera
Apr 02, 2020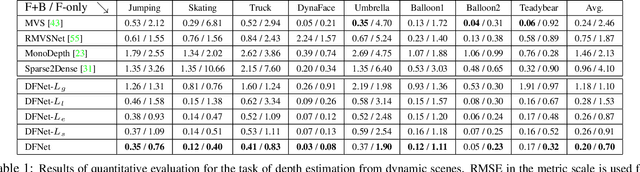
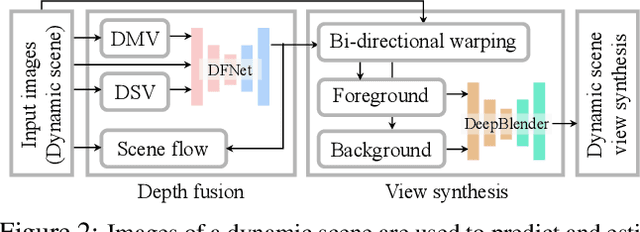
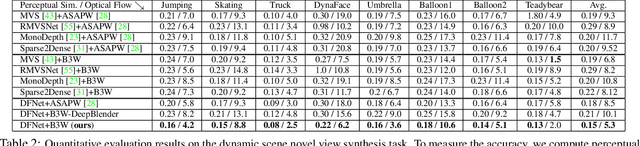
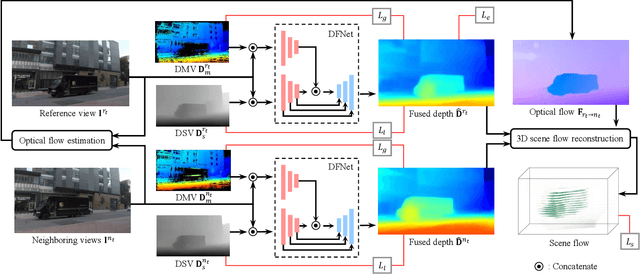
This paper presents a new method to synthesize an image from arbitrary views and times given a collection of images of a dynamic scene. A key challenge for the novel view synthesis arises from dynamic scene reconstruction where epipolar geometry does not apply to the local motion of dynamic contents. To address this challenge, we propose to combine the depth from single view (DSV) and the depth from multi-view stereo (DMV), where DSV is complete, i.e., a depth is assigned to every pixel, yet view-variant in its scale, while DMV is view-invariant yet incomplete. Our insight is that although its scale and quality are inconsistent with other views, the depth estimation from a single view can be used to reason about the globally coherent geometry of dynamic contents. We cast this problem as learning to correct the scale of DSV, and to refine each depth with locally consistent motions between views to form a coherent depth estimation. We integrate these tasks into a depth fusion network in a self-supervised fashion. Given the fused depth maps, we synthesize a photorealistic virtual view in a specific location and time with our deep blending network that completes the scene and renders the virtual view. We evaluate our method of depth estimation and view synthesis on diverse real-world dynamic scenes and show the outstanding performance over existing methods.
Two-shot Spatially-varying BRDF and Shape Estimation
Apr 01, 2020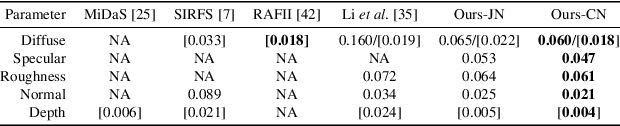
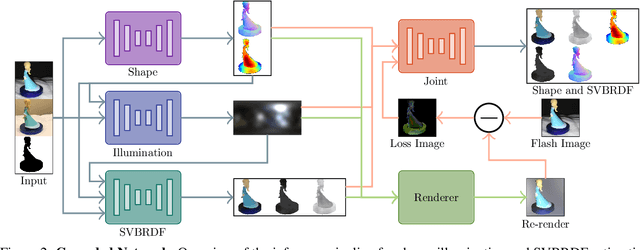
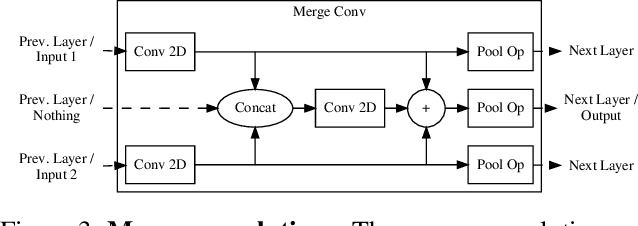

Capturing the shape and spatially-varying appearance (SVBRDF) of an object from images is a challenging task that has applications in both computer vision and graphics. Traditional optimization-based approaches often need a large number of images taken from multiple views in a controlled environment. Newer deep learning-based approaches require only a few input images, but the reconstruction quality is not on par with optimization techniques. We propose a novel deep learning architecture with a stage-wise estimation of shape and SVBRDF. The previous predictions guide each estimation, and a joint refinement network later refines both SVBRDF and shape. We follow a practical mobile image capture setting and use unaligned two-shot flash and no-flash images as input. Both our two-shot image capture and network inference can run on mobile hardware. We also create a large-scale synthetic training dataset with domain-randomized geometry and realistic materials. Extensive experiments on both synthetic and real-world datasets show that our network trained on a synthetic dataset can generalize well to real-world images. Comparisons with recent approaches demonstrate the superior performance of the proposed approach.
Self-supervised Single-view 3D Reconstruction via Semantic Consistency
Mar 13, 2020
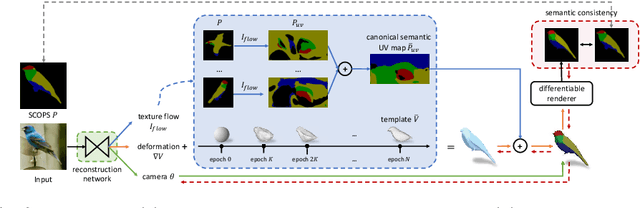

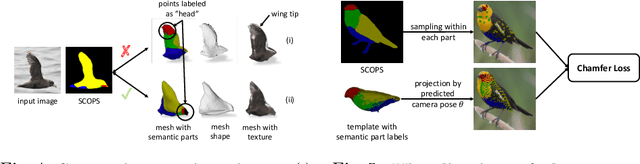
We learn a self-supervised, single-view 3D reconstruction model that predicts the 3D mesh shape, texture and camera pose of a target object with a collection of 2D images and silhouettes. The proposed method does not necessitate 3D supervision, manually annotated keypoints, multi-view images of an object or a prior 3D template. The key insight of our work is that objects can be represented as a collection of deformable parts, and each part is semantically coherent across different instances of the same category (e.g., wings on birds and wheels on cars). Therefore, by leveraging self-supervisedly learned part segmentation of a large collection of category-specific images, we can effectively enforce semantic consistency between the reconstructed meshes and the original images. This significantly reduces ambiguities during joint prediction of shape and camera pose of an object, along with texture. To the best of our knowledge, we are the first to try and solve the single-view reconstruction problem without a category-specific template mesh or semantic keypoints. Thus our model can easily generalize to various object categories without such labels, e.g., horses, penguins, etc. Through a variety of experiments on several categories of deformable and rigid objects, we demonstrate that our unsupervised method performs comparably if not better than existing category-specific reconstruction methods learned with supervision.
STGRAT: A Spatio-Temporal Graph Attention Network for Traffic Forecasting
Nov 29, 2019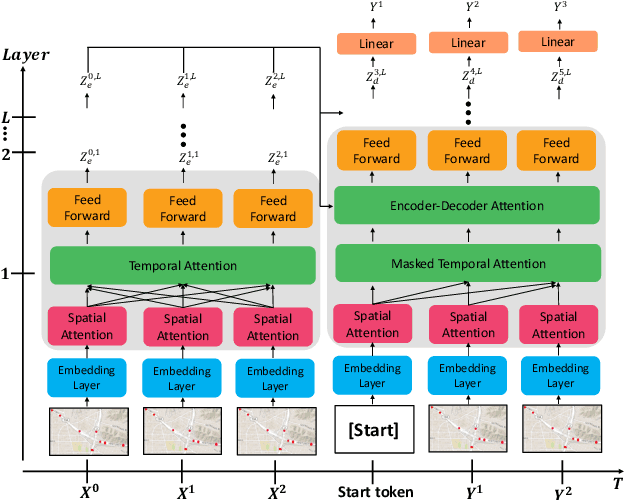
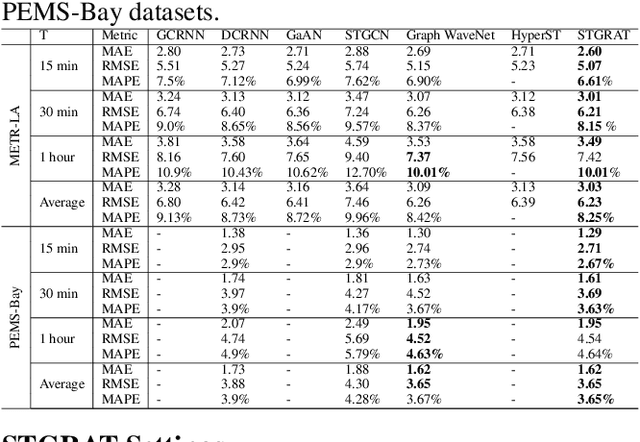
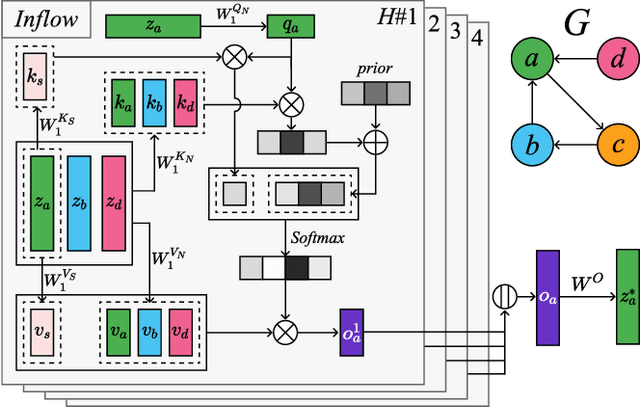
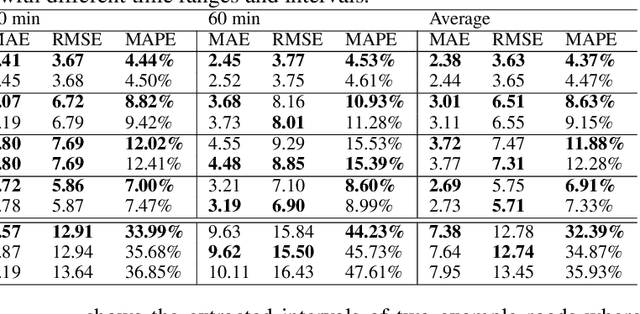
Predicting the road traffic speed is a challenging task due to different types of roads, abrupt speed changes, and spatial dependencies between roads, which requires the modeling of dynamically changing spatial dependencies among roads and temporal patterns over long input sequences. This paper proposes a novel Spatio-Temporal Graph Attention (STGRAT) that effectively captures the spatio-temporal dynamics in road networks. The features of our approach mainly include spatial attention, temporal attention, and spatial sentinel vectors. The spatial attention takes the graph structure information (e.g., distance between roads) and dynamically adjusts spatial correlation based on road states. The temporal attention is responsible for capturing traffic speed changes, while the sentinel vectors allow the model to retrieve new features from spatially correlated nodes or preserve existing features. The experimental results show that STGRAT outperforms existing models, especially in difficult conditions where traffic speeds rapidly change (e.g., rush hours). We additionally provide a qualitative study to analyze when and where STGRAT mainly attended to make accurate predictions during a rush-hour time.
Putting Humans in a Scene: Learning Affordance in 3D Indoor Environments
Mar 15, 2019
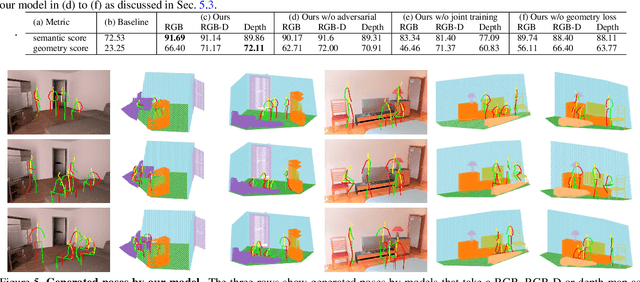
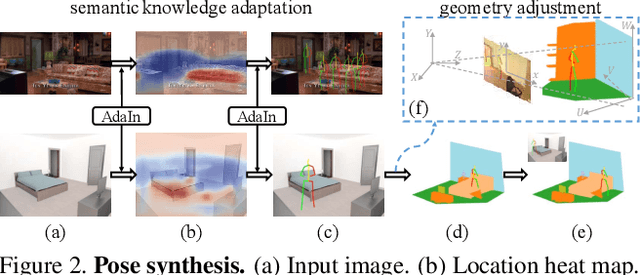
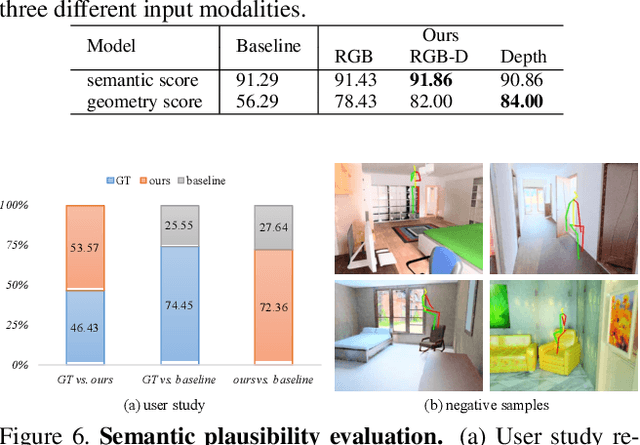
Affordance modeling plays an important role in visual understanding. In this paper, we aim to predict affordances of 3D indoor scenes, specifically what human poses are afforded by a given indoor environment, such as sitting on a chair or standing on the floor. In order to predict valid affordances and learn possible 3D human poses in indoor scenes, we need to understand the semantic and geometric structure of a scene as well as its potential interactions with a human. To learn such a model, a large-scale dataset of 3D indoor affordances is required. In this work, we build a fully automatic 3D pose synthesizer that fuses semantic knowledge from a large number of 2D poses extracted from TV shows as well as 3D geometric knowledge from voxel representations of indoor scenes. With the data created by the synthesizer, we introduce a 3D pose generative model to predict semantically plausible and physically feasible human poses within a given scene (provided as a single RGB, RGB-D, or depth image). We demonstrate that our human affordance prediction method consistently outperforms existing state-of-the-art methods.
* https://sites.google.com/view/3d-affordance-cvpr19