 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoMA: A Real-to-Sim Neural Simulator for Robotic Soft-body Manipulation
Feb 02, 2026Simulating deformable objects under rich interactions remains a fundamental challenge for real-to-sim robot manipulation, with dynamics jointly driven by environmental effects and robot actions. Existing simulators rely on predefined physics or data-driven dynamics without robot-conditioned control, limiting accuracy, stability, and generalization. This paper presents SoMA, a 3D Gaussian Splat simulator for soft-body manipulation. SoMA couples deformable dynamics, environmental forces, and robot joint actions in a unified latent neural space for end-to-end real-to-sim simulation. Modeling interactions over learned Gaussian splats enables controllable, stable long-horizon manipulation and generalization beyond observed trajectories without predefined physical models. SoMA improves resimulation accuracy and generalization on real-world robot manipulation by 20%, enabling stable simulation of complex tasks such as long-horizon cloth folding.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
eTracer: Towards Traceable Text Generation via Claim-Level Grounding
Jan 07, 2026How can system-generated responses be efficiently verified, especially in the high-stakes biomedical domain? To address this challenge, we introduce eTracer, a plug-and-play framework that enables traceable text generation by grounding claims against contextual evidence. Through post-hoc grounding, each response claim is aligned with contextual evidence that either supports or contradicts it. Building on claim-level grounding results, eTracer not only enables users to precisely trace responses back to their contextual source but also quantifies response faithfulness, thereby enabling the verifiability and trustworthiness of generated responses. Experiments show that our claim-level grounding approach alleviates the limitations of conventional grounding methods in aligning generated statements with contextual sentence-level evidence, resulting in substantial improvements in overall grounding quality and user verification efficiency. The code and data are available at https://github.com/chubohao/eTracer.
Towards Fine-Grained and Multi-Granular Contrastive Language-Speech Pre-training
Jan 06, 2026Modeling fine-grained speaking styles remains challenging for language-speech representation pre-training, as existing speech-text models are typically trained with coarse captions or task-specific supervision, and scalable fine-grained style annotations are unavailable. We present FCaps, a large-scale dataset with fine-grained free-text style descriptions, encompassing 47k hours of speech and 19M fine-grained captions annotated via a novel end-to-end pipeline that directly grounds detailed captions in audio, thereby avoiding the error propagation caused by LLM-based rewriting in existing cascaded pipelines. Evaluations using LLM-as-a-judge demonstrate that our annotations surpass existing cascaded annotations in terms of correctness, coverage, and naturalness. Building on FCaps, we propose CLSP, a contrastive language-speech pre-trained model that integrates global and fine-grained supervision, enabling unified representations across multiple granularities. Extensive experiments demonstrate that CLSP learns fine-grained and multi-granular speech-text representations that perform reliably across global and fine-grained speech-text retrieval, zero-shot paralinguistic classification, and speech style similarity scoring, with strong alignment to human judgments. All resources will be made publicly available.
DL$^3$M: A Vision-to-Language Framework for Expert-Level Medical Reasoning through Deep Learning and Large Language Models
Dec 14, 2025Medical image classifiers detect gastrointestinal diseases well, but they do not explain their decisions. Large language models can generate clinical text, yet they struggle with visual reasoning and often produce unstable or incorrect explanations. This leaves a gap between what a model sees and the type of reasoning a clinician expects. We introduce a framework that links image classification with structured clinical reasoning. A new hybrid model, MobileCoAtNet, is designed for endoscopic images and achieves high accuracy across eight stomach-related classes. Its outputs are then used to drive reasoning by several LLMs. To judge this reasoning, we build two expert-verified benchmarks covering causes, symptoms, treatment, lifestyle, and follow-up care. Thirty-two LLMs are evaluated against these gold standards. Strong classification improves the quality of their explanations, but none of the models reach human-level stability. Even the best LLMs change their reasoning when prompts vary. Our study shows that combining DL with LLMs can produce useful clinical narratives, but current LLMs remain unreliable for high-stakes medical decisions. The framework provides a clearer view of their limits and a path for building safer reasoning systems. The complete source code and datasets used in this study are available at https://github.com/souravbasakshuvo/DL3M.
CogMCTS: A Novel Cognitive-Guided Monte Carlo Tree Search Framework for Iterative Heuristic Evolution with Large Language Models
Dec 11, 2025



Automatic Heuristic Design (AHD) is an effective framework for solving complex optimization problems. The development of large language models (LLMs) enables the automated generation of heuristics. Existing LLM-based evolutionary methods rely on population strategies and are prone to local optima. Integrating LLMs with Monte Carlo Tree Search (MCTS) improves the trade-off between exploration and exploitation, but multi-round cognitive integration remains limited and search diversity is constrained. To overcome these limitations, this paper proposes a novel cognitive-guided MCTS framework (CogMCTS). CogMCTS tightly integrates the cognitive guidance mechanism of LLMs with MCTS to achieve efficient automated heuristic optimization. The framework employs multi-round cognitive feedback to incorporate historical experience, node information, and negative outcomes, dynamically improving heuristic generation. Dual-track node expansion combined with elite heuristic management balances the exploration of diverse heuristics and the exploitation of high-quality experience. In addition, strategic mutation modifies the heuristic forms and parameters to further enhance the diversity of the solution and the overall optimization performance. The experimental results indicate that CogMCTS outperforms existing LLM-based AHD methods in stability, efficiency, and solution quality.
PCMind-2.1-Kaiyuan-2B Technical Report
Dec 08, 2025The rapid advancement of Large Language Models (LLMs) has resulted in a significant knowledge gap between the open-source community and industry, primarily because the latter relies on closed-source, high-quality data and training recipes. To address this, we introduce PCMind-2.1-Kaiyuan-2B, a fully open-source 2-billion-parameter model focused on improving training efficiency and effectiveness under resource constraints. Our methodology includes three key innovations: a Quantile Data Benchmarking method for systematically comparing heterogeneous open-source datasets and providing insights on data mixing strategies; a Strategic Selective Repetition scheme within a multi-phase paradigm to effectively leverage sparse, high-quality data; and a Multi-Domain Curriculum Training policy that orders samples by quality. Supported by a highly optimized data preprocessing pipeline and architectural modifications for FP16 stability, Kaiyuan-2B achieves performance competitive with state-of-the-art fully open-source models, demonstrating practical and scalable solutions for resource-limited pretraining. We release all assets (including model weights, data, and code) under Apache 2.0 license at https://huggingface.co/thu-pacman/PCMind-2.1-Kaiyuan-2B.
PRISM: Proof-Carrying Artifact Generation through LLM x MDE Synergy and Stratified Constraints
Oct 29, 2025PRISM unifies Large Language Models with Model-Driven Engineering to generate regulator-ready artifacts and machine-checkable evidence for safety- and compliance-critical domains. PRISM integrates three pillars: a Unified Meta-Model (UMM) reconciles heterogeneous schemas and regulatory text into a single semantic space; an Integrated Constraint Model (ICM) compiles structural and semantic requirements into enforcement artifacts including generation-time automata (GBNF, DFA) and post-generation validators (e.g., SHACL, SMT); and Constraint-Guided Verifiable Generation (CVG) applies these through two-layer enforcement - structural constraints drive prefix-safe decoding while semantic/logical validation produces machine-checkable certificates. When violations occur, PRISM performs audit-guided repair and records generation traces for compliance review. We evaluate PRISM in automotive software engineering (AUTOSAR) and cross-border legal jurisdiction (Brussels I bis). PRISM produces structurally valid, auditable artifacts that integrate with existing tooling and substantially reduce manual remediation effort, providing a practical path toward automated artifact generation with built-in assurance.
Towards Responsible Evaluation for Text-to-Speech
Oct 08, 2025



Recent advances in text-to-speech (TTS) technology have enabled systems to produce human-indistinguishable speech, bringing benefits across accessibility, content creation, and human-computer interaction. However, current evaluation practices are increasingly inadequate for capturing the full range of capabilities, limitations, and societal implications. This position paper introduces the concept of Responsible Evaluation and argues that it is essential and urgent for the next phase of TTS development, structured through three progressive levels: (1) ensuring the faithful and accurate reflection of a model's true capabilities, with more robust, discriminative, and comprehensive objective and subjective scoring methodologies; (2) enabling comparability, standardization, and transferability through standardized benchmarks, transparent reporting, and transferable evaluation metrics; and (3) assessing and mitigating ethical risks associated with forgery, misuse, privacy violations, and security vulnerabilities. Through this concept, we critically examine current evaluation practices, identify systemic shortcomings, and propose actionable recommendations. We hope this concept of Responsible Evaluation will foster more trustworthy and reliable TTS technology and guide its development toward ethically sound and societally beneficial applications.
LimiX: Unleashing Structured-Data Modeling Capability for Generalist Intelligence
Sep 03, 2025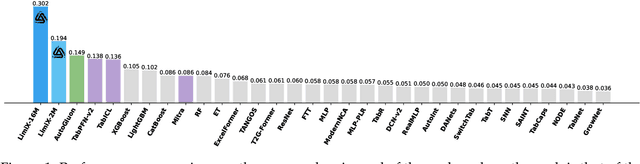
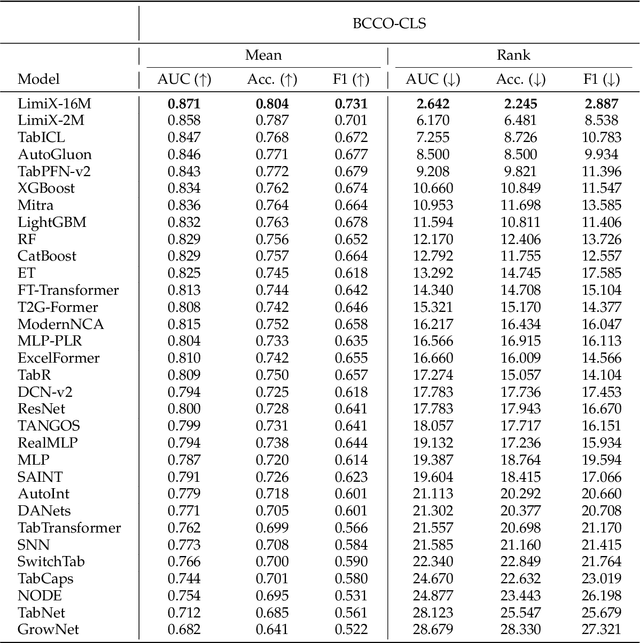
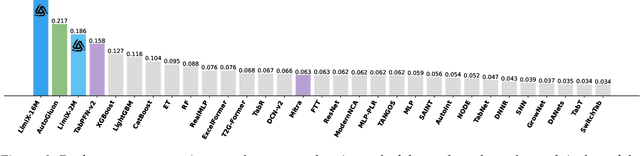
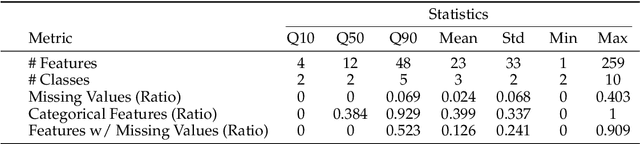
We argue that progress toward general intelligence requires complementary foundation models grounded in language, the physical world, and structured data. This report presents LimiX, the first installment of our large structured-data models (LDMs). LimiX treats structured data as a joint distribution over variables and missingness, thus capable of addressing a wide range of tabular tasks through query-based conditional prediction via a single model. LimiX is pretrained using masked joint-distribution modeling with an episodic, context-conditional objective, where the model predicts for query subsets conditioned on dataset-specific contexts, supporting rapid, training-free adaptation at inference. We evaluate LimiX across 10 large structured-data benchmarks with broad regimes of sample size, feature dimensionality, class number, categorical-to-numerical feature ratio, missingness, and sample-to-feature ratios. With a single model and a unified interface, LimiX consistently surpasses strong baselines including gradient-boosting trees, deep tabular networks, recent tabular foundation models, and automated ensembles, as shown in Figure 1 and Figure 2. The superiority holds across a wide range of tasks, such as classification, regression, missing value imputation, and data generation, often by substantial margins, while avoiding task-specific architectures or bespoke training per task. All LimiX models are publicly accessible under Apache 2.0.