 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrFedDis: Trusted Federated Disentangling Network for Non-IID Domain Feature
Jan 30, 2023



Federated learning (FL), as an effective decentralized distributed learning approach, enables multiple institutions to jointly train a model without sharing their local data. However, the domain feature shift caused by different acquisition devices/clients substantially degrades the performance of the FL model. Furthermore, most existing FL approaches aim to improve accuracy without considering reliability (e.g., confidence or uncertainty). The predictions are thus unreliable when deployed in safety-critical applications. Therefore, aiming at improving the performance of FL in non-Domain feature issues while enabling the model more reliable. In this paper, we propose a novel trusted federated disentangling network, termed TrFedDis, which utilizes feature disentangling to enable the ability to capture the global domain-invariant cross-client representation and preserve local client-specific feature learning. Meanwhile, to effectively integrate the decoupled features, an uncertainty-aware decision fusion is also introduced to guide the network for dynamically integrating the decoupled features at the evidence level, while producing a reliable prediction with an estimated uncertainty. To the best of our knowledge, our proposed TrFedDis is the first work to develop an FL approach based on evidential uncertainty combined with feature disentangling, which enhances the performance and reliability of FL in non-IID domain features. Extensive experimental results show that our proposed TrFedDis provides outstanding performance with a high degree of reliability as compared to other state-of-the-art FL approaches.
EvidenceCap: Towards trustworthy medical image segmentation via evidential identity cap
Jan 01, 2023



Medical image segmentation (MIS) is essential for supporting disease diagnosis and treatment effect assessment. Despite considerable advances in artificial intelligence (AI) for MIS, clinicians remain skeptical of its utility, maintaining low confidence in such black box systems, with this problem being exacerbated by low generalization for out-of-distribution (OOD) data. To move towards effective clinical utilization, we propose a foundation model named EvidenceCap, which makes the box transparent in a quantifiable way by uncertainty estimation. EvidenceCap not only makes AI visible in regions of uncertainty and OOD data, but also enhances the reliability, robustness, and computational efficiency of MIS. Uncertainty is modeled explicitly through subjective logic theory to gather strong evidence from features. We show the effectiveness of EvidenceCap in three segmentation datasets and apply it to the clinic. Our work sheds light on clinical safe applications and explainable AI, and can contribute towards trustworthiness in the medical domain.
Reliable Joint Segmentation of Retinal Edema Lesions in OCT Images
Dec 01, 2022



Focusing on the complicated pathological features, such as blurred boundaries, severe scale differences between symptoms, background noise interference, etc., in the task of retinal edema lesions joint segmentation from OCT images and enabling the segmentation results more reliable. In this paper, we propose a novel reliable multi-scale wavelet-enhanced transformer network, which can provide accurate segmentation results with reliability assessment. Specifically, aiming at improving the model's ability to learn the complex pathological features of retinal edema lesions in OCT images, we develop a novel segmentation backbone that integrates a wavelet-enhanced feature extractor network and a multi-scale transformer module of our newly designed. Meanwhile, to make the segmentation results more reliable, a novel uncertainty segmentation head based on the subjective logical evidential theory is introduced to generate the final segmentation results with a corresponding overall uncertainty evaluation score map. We conduct comprehensive experiments on the public database of AI-Challenge 2018 for retinal edema lesions segmentation, and the results show that our proposed method achieves better segmentation accuracy with a high degree of reliability as compared to other state-of-the-art segmentation approaches. The code will be released on: https://github.com/LooKing9218/ReliableRESeg.
ExpNet: A unified network for Expert-Level Classification
Nov 29, 2022



Different from the general visual classification, some classification tasks are more challenging as they need the professional categories of the images. In the paper, we call them expert-level classification. Previous fine-grained vision classification (FGVC) has made many efforts on some of its specific sub-tasks. However, they are difficult to expand to the general cases which rely on the comprehensive analysis of part-global correlation and the hierarchical features interaction. In this paper, we propose Expert Network (ExpNet) to address the unique challenges of expert-level classification through a unified network. In ExpNet, we hierarchically decouple the part and context features and individually process them using a novel attentive mechanism, called Gaze-Shift. In each stage, Gaze-Shift produces a focal-part feature for the subsequent abstraction and memorizes a context-related embedding. Then we fuse the final focal embedding with all memorized context-related embedding to make the prediction. Such an architecture realizes the dual-track processing of partial and global information and hierarchical feature interactions. We conduct the experiments over three representative expert-level classification tasks: FGVC, disease classification, and artwork attributes classification. In these experiments, superior performance of our ExpNet is observed comparing to the state-of-the-arts in a wide range of fields, indicating the effectiveness and generalization of our ExpNet. The code will be made publicly available.
Dual Multi-scale Mean Teacher Network for Semi-supervised Infection Segmentation in Chest CT Volume for COVID-19
Nov 10, 2022Automated detecting lung infections from computed tomography (CT) data plays an important role for combating COVID-19. However, there are still some challenges for developing AI system. 1) Most current COVID-19 infection segmentation methods mainly relied on 2D CT images, which lack 3D sequential constraint. 2) Existing 3D CT segmentation methods focus on single-scale representations, which do not achieve the multiple level receptive field sizes on 3D volume. 3) The emergent breaking out of COVID-19 makes it hard to annotate sufficient CT volumes for training deep model. To address these issues, we first build a multiple dimensional-attention convolutional neural network (MDA-CNN) to aggregate multi-scale information along different dimension of input feature maps and impose supervision on multiple predictions from different CNN layers. Second, we assign this MDA-CNN as a basic network into a novel dual multi-scale mean teacher network (DM${^2}$T-Net) for semi-supervised COVID-19 lung infection segmentation on CT volumes by leveraging unlabeled data and exploring the multi-scale information. Our DM${^2}$T-Net encourages multiple predictions at different CNN layers from the student and teacher networks to be consistent for computing a multi-scale consistency loss on unlabeled data, which is then added to the supervised loss on the labeled data from multiple predictions of MDA-CNN. Third, we collect two COVID-19 segmentation datasets to evaluate our method. The experimental results show that our network consistently outperforms the compared state-of-the-art methods.
Degradation-invariant Enhancement of Fundus Images via Pyramid Constraint Network
Oct 18, 2022As an economical and efficient fundus imaging modality, retinal fundus images have been widely adopted in clinical fundus examination. Unfortunately, fundus images often suffer from quality degradation caused by imaging interferences, leading to misdiagnosis. Despite impressive enhancement performances that state-of-the-art methods have achieved, challenges remain in clinical scenarios. For boosting the clinical deployment of fundus image enhancement, this paper proposes the pyramid constraint to develop a degradation-invariant enhancement network (PCE-Net), which mitigates the demand for clinical data and stably enhances unknown data. Firstly, high-quality images are randomly degraded to form sequences of low-quality ones sharing the same content (SeqLCs). Then individual low-quality images are decomposed to Laplacian pyramid features (LPF) as the multi-level input for the enhancement. Subsequently, a feature pyramid constraint (FPC) for the sequence is introduced to enforce the PCE-Net to learn a degradation-invariant model. Extensive experiments have been conducted under the evaluation metrics of enhancement and segmentation. The effectiveness of the PCE-Net was demonstrated in comparison with state-of-the-art methods and the ablation study. The source code of this study is publicly available at https://github.com/HeverLaw/PCENet-Image-Enhancement.
Localizing Anatomical Landmarks in Ocular Images using Zoom-In Attentive Networks
Sep 25, 2022Localizing anatomical landmarks are important tasks in medical image analysis. However, the landmarks to be localized often lack prominent visual features. Their locations are elusive and easily confused with the background, and thus precise localization highly depends on the context formed by their surrounding areas. In addition, the required precision is usually higher than segmentation and object detection tasks. Therefore, localization has its unique challenges different from segmentation or detection. In this paper, we propose a zoom-in attentive network (ZIAN) for anatomical landmark localization in ocular images. First, a coarse-to-fine, or "zoom-in" strategy is utilized to learn the contextualized features in different scales. Then, an attentive fusion module is adopted to aggregate multi-scale features, which consists of 1) a co-attention network with a multiple regions-of-interest (ROIs) scheme that learns complementary features from the multiple ROIs, 2) an attention-based fusion module which integrates the multi-ROIs features and non-ROI features. We evaluated ZIAN on two open challenge tasks, i.e., the fovea localization in fundus images and scleral spur localization in AS-OCT images. Experiments show that ZIAN achieves promising performances and outperforms state-of-the-art localization methods. The source code and trained models of ZIAN are available at https://github.com/leixiaofeng-astar/OMIA9-ZIAN.
Learning to screen Glaucoma like the ophthalmologists
Sep 23, 2022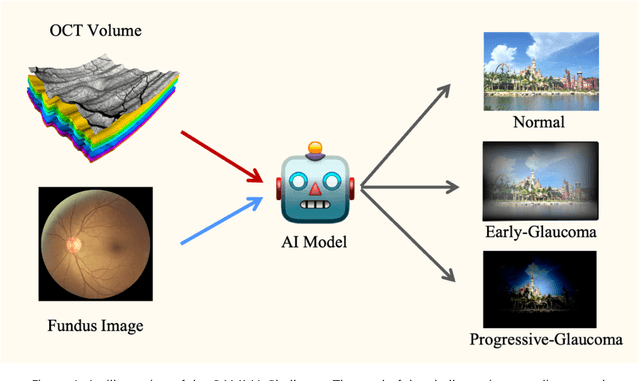
GAMMA Challenge is organized to encourage the AI models to screen the glaucoma from a combination of 2D fundus image and 3D optical coherence tomography volume, like the ophthalmologists.
Unsupervised Domain Adaptation via Style-Aware Self-intermediate Domain
Sep 05, 2022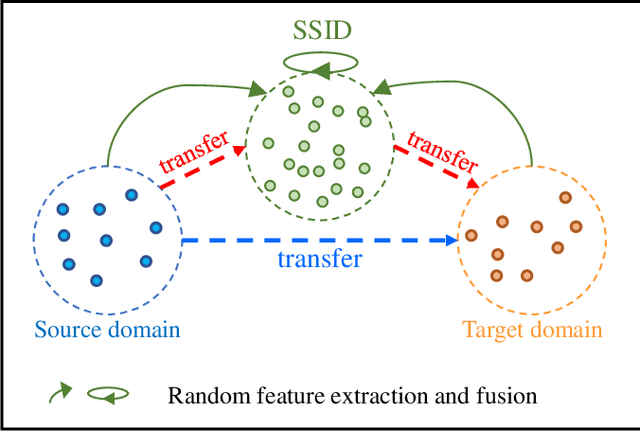
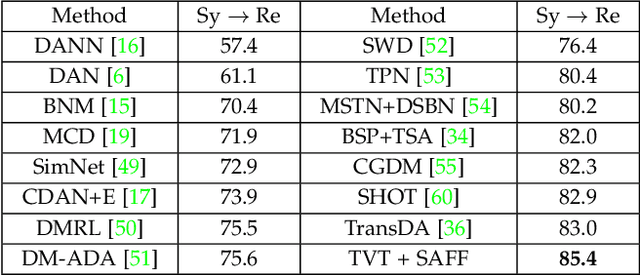
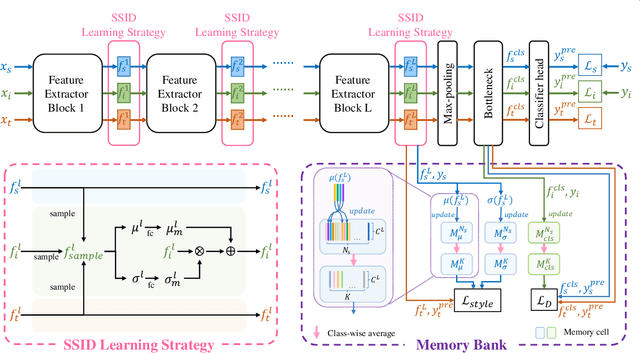
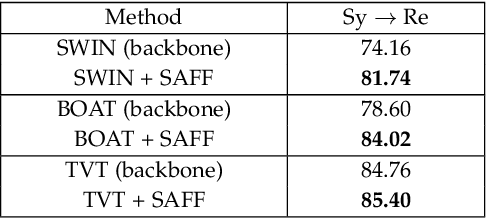
Unsupervised domain adaptation (UDA) has attracted considerable attention, which transfers knowledge from a label-rich source domain to a related but unlabeled target domain. Reducing inter-domain differences has always been a crucial factor to improve performance in UDA, especially for tasks where there is a large gap between source and target domains. To this end, we propose a novel style-aware feature fusion method (SAFF) to bridge the large domain gap and transfer knowledge while alleviating the loss of class-discriminative information. Inspired by the human transitive inference and learning ability, a novel style-aware self-intermediate domain (SSID) is investigated to link two seemingly unrelated concepts through a series of intermediate auxiliary synthesized concepts. Specifically, we propose a novel learning strategy of SSID, which selects samples from both source and target domains as anchors, and then randomly fuses the object and style features of these anchors to generate labeled and style-rich intermediate auxiliary features for knowledge transfer. Moreover, we design an external memory bank to store and update specified labeled features to obtain stable class features and class-wise style features. Based on the proposed memory bank, the intra- and inter-domain loss functions are designed to improve the class recognition ability and feature compatibility, respectively. Meanwhile, we simulate the rich latent feature space of SSID by infinite sampling and the convergence of the loss function by mathematical theory. Finally, we conduct comprehensive experiments on commonly used domain adaptive benchmarks to evaluate the proposed SAFF, and the experimental results show that the proposed SAFF can be easily combined with different backbone networks and obtain better performance as a plug-in-plug-out module.
Dataset and Evaluation algorithm design for GOALS Challenge
Jul 29, 2022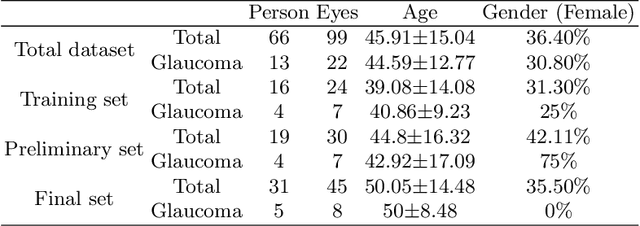
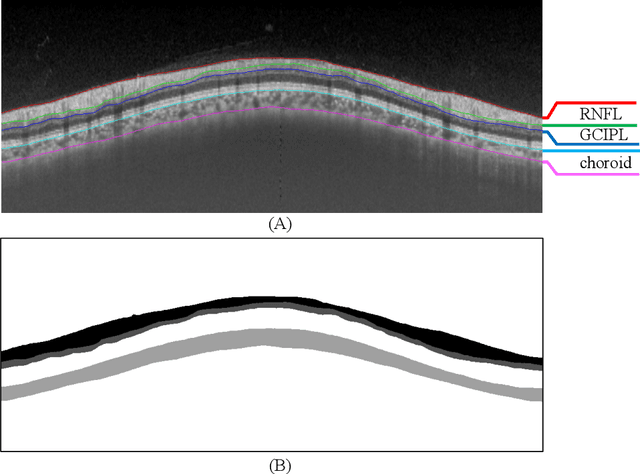
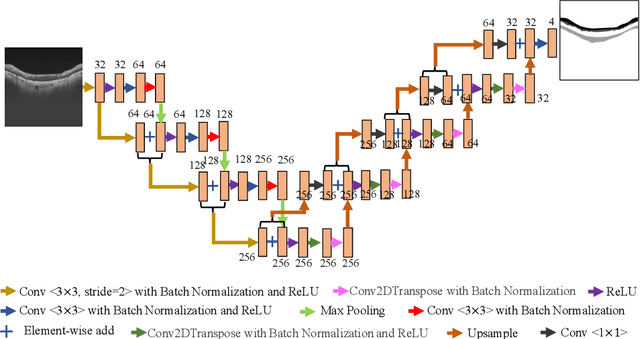
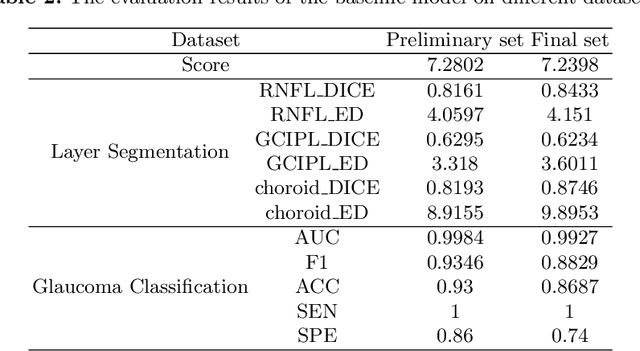
Glaucoma causes irreversible vision loss due to damage to the optic nerve, and there is no cure for glaucoma.OCT imaging modality is an essential technique for assessing glaucomatous damage since it aids in quantifying fundus structures. To promote the research of AI technology in the field of OCT-assisted diagnosis of glaucoma, we held a Glaucoma OCT Analysis and Layer Segmentation (GOALS) Challenge in conjunction with the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI) 2022 to provide data and corresponding annotations for researchers studying layer segmentation from OCT images and the classification of glaucoma. This paper describes the released 300 circumpapillary OCT images, the baselines of the two sub-tasks, and the evaluation methodology. The GOALS Challenge is accessible at https://aistudio.baidu.com/aistudio/competition/detail/230.