 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
Oct 14, 2022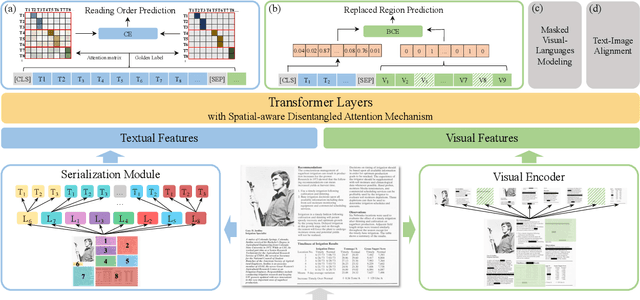
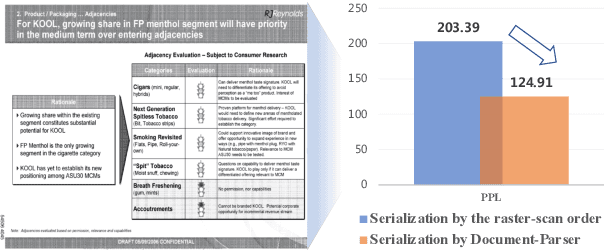
Recent years have witnessed the rise and success of pre-training techniques in visually-rich document understanding. However, most existing methods lack the systematic mining and utilization of layout-centered knowledge, leading to sub-optimal performances. In this paper, we propose ERNIE-Layout, a novel document pre-training solution with layout knowledge enhancement in the whole workflow, to learn better representations that combine the features from text, layout, and image. Specifically, we first rearrange input sequences in the serialization stage, and then present a correlative pre-training task, reading order prediction, to learn the proper reading order of documents. To improve the layout awareness of the model, we integrate a spatial-aware disentangled attention into the multi-modal transformer and a replaced regions prediction task into the pre-training phase. Experimental results show that ERNIE-Layout achieves superior performance on various downstream tasks, setting new state-of-the-art on key information extraction, document image classification, and document question answering datasets. The code and models are publicly available at http://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout.
ERNIE-ViL 2.0: Multi-view Contrastive Learning for Image-Text Pre-training
Sep 30, 2022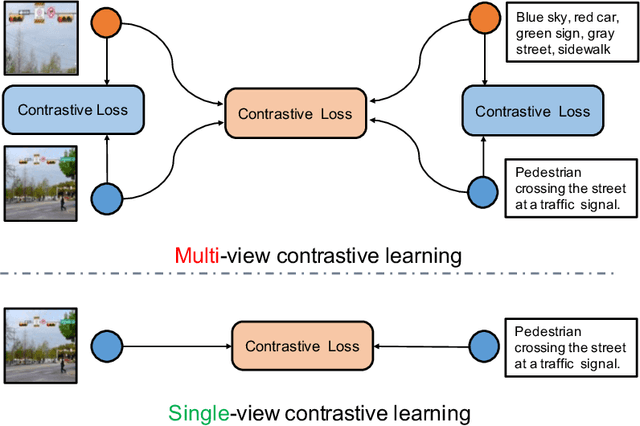
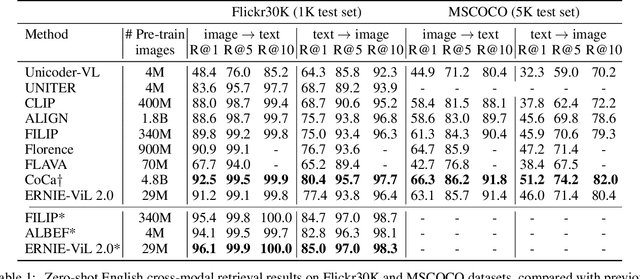
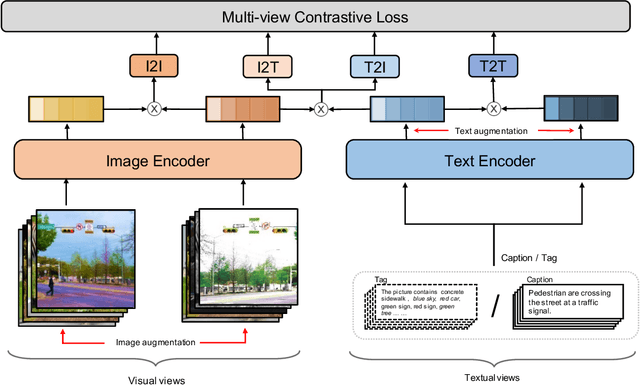
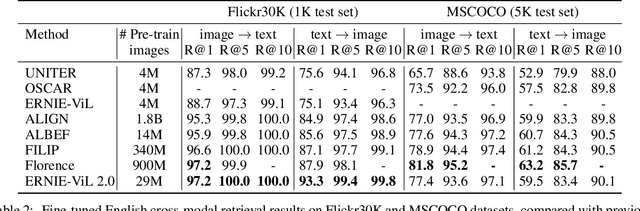
Recent Vision-Language Pre-trained (VLP) models based on dual encoder have attracted extensive attention from academia and industry due to their superior performance on various cross-modal tasks and high computational efficiency. They attempt to learn cross-modal representation using contrastive learning on image-text pairs, however, the built inter-modal correlations only rely on a single view for each modality. Actually, an image or a text contains various potential views, just as humans could capture a real-world scene via diverse descriptions or photos. In this paper, we propose ERNIE-ViL 2.0, a Multi-View Contrastive learning framework to build intra-modal and inter-modal correlations between diverse views simultaneously, aiming at learning a more robust cross-modal representation. Specifically, we construct multiple views within each modality to learn the intra-modal correlation for enhancing the single-modal representation. Besides the inherent visual/textual views, we construct sequences of object tags as a special textual view to narrow the cross-modal semantic gap on noisy image-text pairs. Pre-trained with 29M publicly available datasets, ERNIE-ViL 2.0 achieves competitive results on English cross-modal retrieval. Additionally, to generalize our method to Chinese cross-modal tasks, we train ERNIE-ViL 2.0 through scaling up the pre-training datasets to 1.5B Chinese image-text pairs, resulting in significant improvements compared to previous SOTA results on Chinese cross-modal retrieval. We release our pre-trained models in https://github.com/PaddlePaddle/ERNIE.
Towards Boosting the Open-Domain Chatbot with Human Feedback
Aug 30, 2022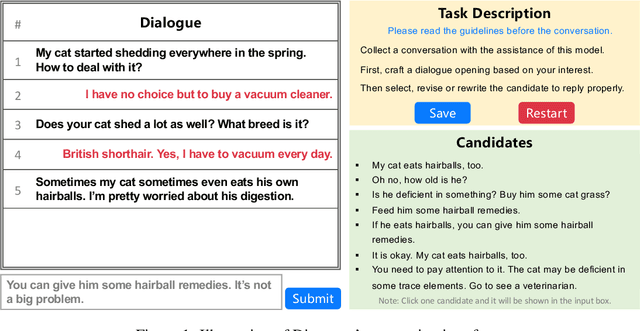
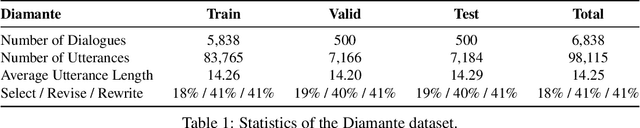
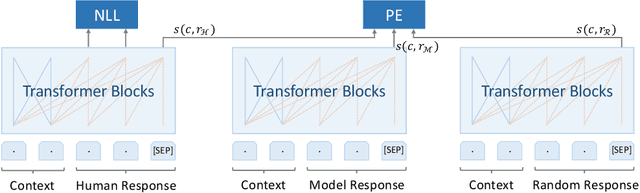

Many open-domain dialogue models pre-trained with social media comments can generate coherent replies but have difficulties producing engaging responses when interacting with real users. This phenomenon might mainly result from the deficiency of annotated human-human conversations and the misalignment with human preference. In this paper, we propose a novel and efficient approach Diamante to boost the open-domain chatbot, where two kinds of human feedback (including explicit demonstration and implicit preference) are collected and leveraged. By asking annotators to select or amend the model-generated candidate responses, Diamante efficiently collects the human demonstrated responses and constructs a Chinese chit-chat dataset. To enhance the alignment with human preference, Diamante leverages the implicit preference in the data collection process and introduces the generation-evaluation joint training. Comprehensive experiments indicate that the Diamante dataset and joint training paradigm can significantly boost the performance of Chinese pre-trained dialogue models.
SeSQL: Yet Another Large-scale Session-level Chinese Text-to-SQL Dataset
Aug 26, 2022
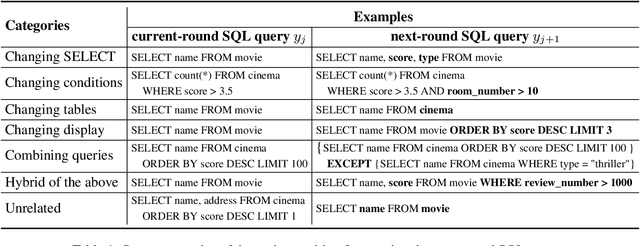
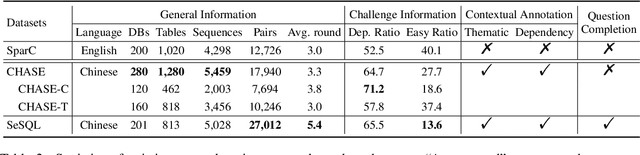
As the first session-level Chinese dataset, CHASE contains two separate parts, i.e., 2,003 sessions manually constructed from scratch (CHASE-C), and 3,456 sessions translated from English SParC (CHASE-T). We find the two parts are highly discrepant and incompatible as training and evaluation data. In this work, we present SeSQL, yet another large-scale session-level text-to-SQL dataset in Chinese, consisting of 5,028 sessions all manually constructed from scratch. In order to guarantee data quality, we adopt an iterative annotation workflow to facilitate intense and in-time review of previous-round natural language (NL) questions and SQL queries. Moreover, by completing all context-dependent NL questions, we obtain 27,012 context-independent question/SQL pairs, allowing SeSQL to be used as the largest dataset for single-round multi-DB text-to-SQL parsing. We conduct benchmark session-level text-to-SQL parsing experiments on SeSQL by employing three competitive session-level parsers, and present detailed analysis.
GEM-2: Next Generation Molecular Property Prediction Network with Many-body and Full-range Interaction Modeling
Aug 15, 2022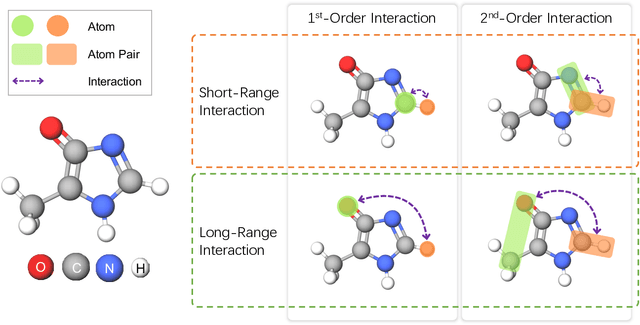
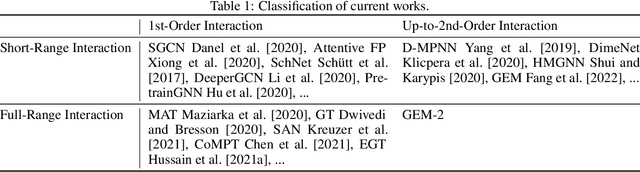
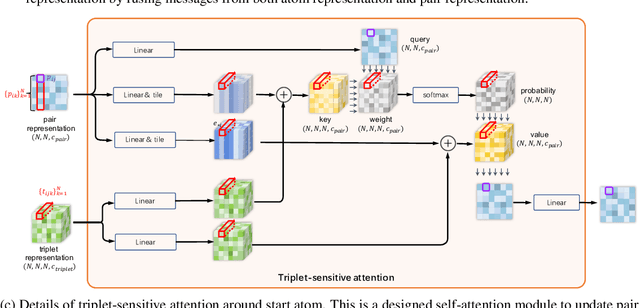
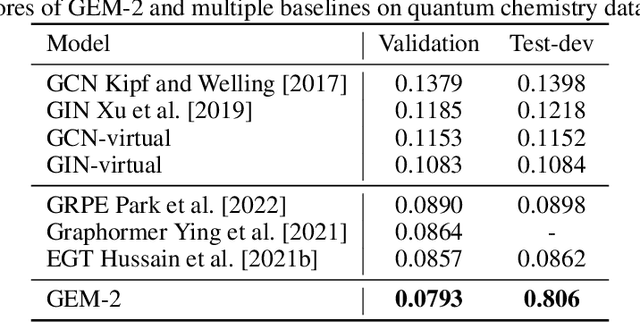
Molecular property prediction is a fundamental task in the drug and material industries. Physically, the properties of a molecule are determined by its own electronic structure, which can be exactly described by the Schr\"odinger equation. However, solving the Schr\"odinger equation for most molecules is extremely challenging due to long-range interactions in the behavior of a quantum many-body system. While deep learning methods have proven to be effective in molecular property prediction, we design a novel method, namely GEM-2, which comprehensively considers both the long-range and many-body interactions in molecules. GEM-2 consists of two interacted tracks: an atom-level track modeling both the local and global correlation between any two atoms, and a pair-level track modeling the correlation between all atom pairs, which embed information between any 3 or 4 atoms. Extensive experiments demonstrated the superiority of GEM-2 over multiple baseline methods in quantum chemistry and drug discovery tasks.
HelixFold-Single: MSA-free Protein Structure Prediction by Using Protein Language Model as an Alternative
Aug 09, 2022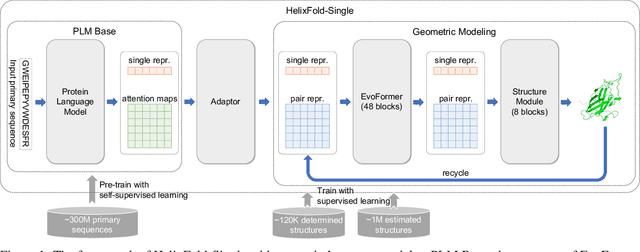

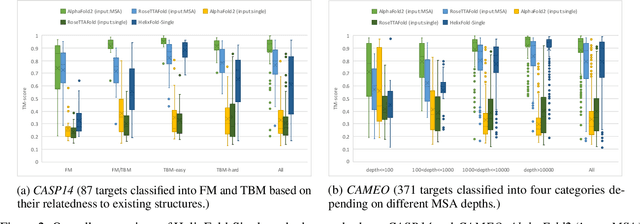
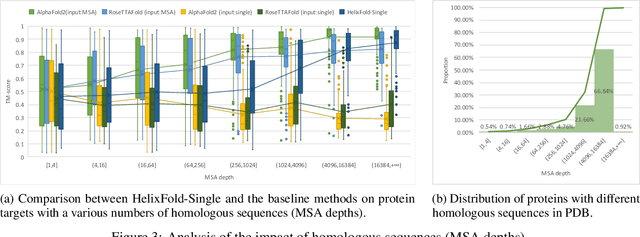
AI-based protein structure prediction pipelines, such as AlphaFold2, have achieved near-experimental accuracy. These advanced pipelines mainly rely on Multiple Sequence Alignments (MSAs) as inputs to learn the co-evolution information from the homologous sequences. Nonetheless, searching MSAs from protein databases is time-consuming, usually taking dozens of minutes. Consequently, we attempt to explore the limits of fast protein structure prediction by using only primary sequences of proteins. HelixFold-Single is proposed to combine a large-scale protein language model with the superior geometric learning capability of AlphaFold2. Our proposed method, HelixFold-Single, first pre-trains a large-scale protein language model (PLM) with thousands of millions of primary sequences utilizing the self-supervised learning paradigm, which will be used as an alternative to MSAs for learning the co-evolution information. Then, by combining the pre-trained PLM and the essential components of AlphaFold2, we obtain an end-to-end differentiable model to predict the 3D coordinates of atoms from only the primary sequence. HelixFold-Single is validated in datasets CASP14 and CAMEO, achieving competitive accuracy with the MSA-based methods on the targets with large homologous families. Furthermore, HelixFold-Single consumes much less time than the mainstream pipelines for protein structure prediction, demonstrating its potential in tasks requiring many predictions. The code of HelixFold-Single is available at https://github.com/PaddlePaddle/PaddleHelix/tree/dev/apps/protein_folding/helixfold-single, and we also provide stable web services on https://paddlehelix.baidu.com/app/drug/protein-single/forecast.
An Interpretability Evaluation Benchmark for Pre-trained Language Models
Jul 28, 2022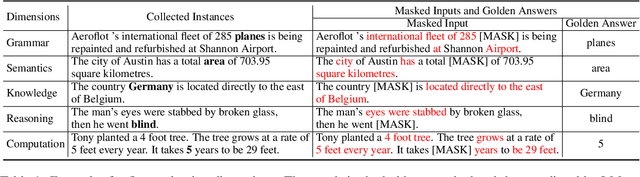
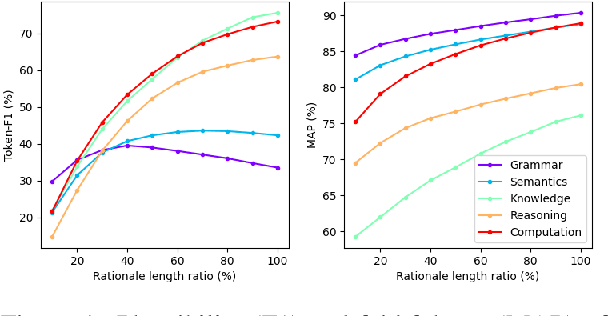

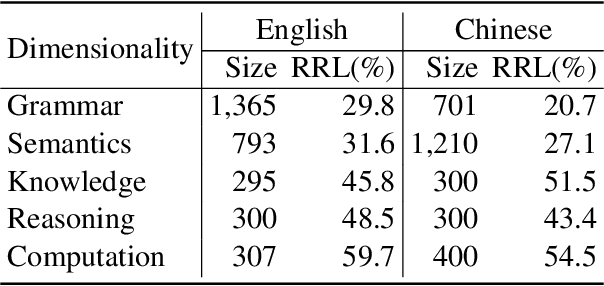
While pre-trained language models (LMs) have brought great improvements in many NLP tasks, there is increasing attention to explore capabilities of LMs and interpret their predictions. However, existing works usually focus only on a certain capability with some downstream tasks. There is a lack of datasets for directly evaluating the masked word prediction performance and the interpretability of pre-trained LMs. To fill in the gap, we propose a novel evaluation benchmark providing with both English and Chinese annotated data. It tests LMs abilities in multiple dimensions, i.e., grammar, semantics, knowledge, reasoning and computation. In addition, it provides carefully annotated token-level rationales that satisfy sufficiency and compactness. It contains perturbed instances for each original instance, so as to use the rationale consistency under perturbations as the metric for faithfulness, a perspective of interpretability. We conduct experiments on several widely-used pre-trained LMs. The results show that they perform very poorly on the dimensions of knowledge and computation. And their plausibility in all dimensions is far from satisfactory, especially when the rationale is short. In addition, the pre-trained LMs we evaluated are not robust on syntax-aware data. We will release this evaluation benchmark at \url{http://xyz}, and hope it can facilitate the research progress of pre-trained LMs.
SINC: Service Information Augmented Open-Domain Conversation
Jun 28, 2022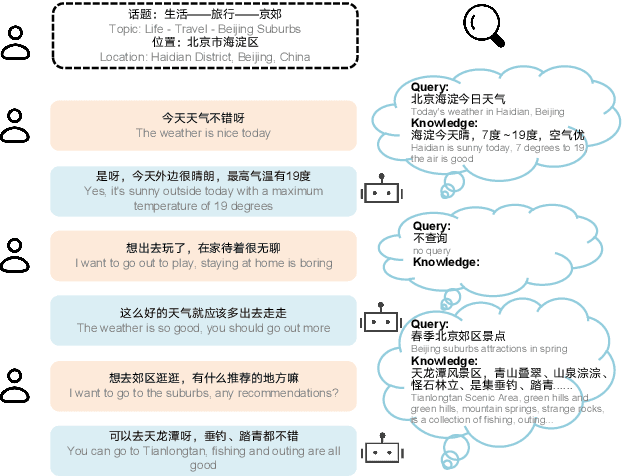
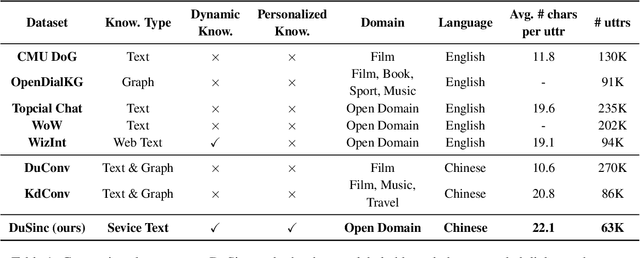
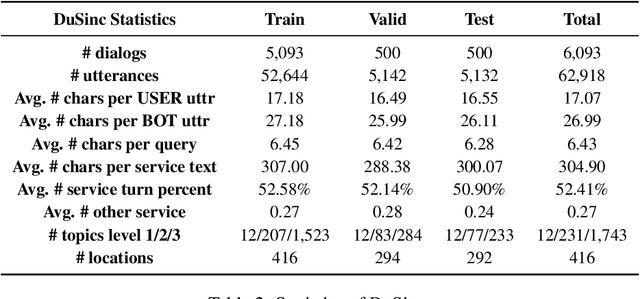
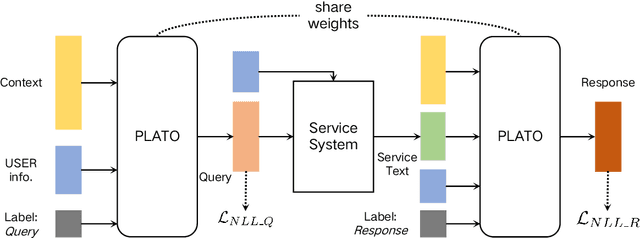
Generative open-domain dialogue systems can benefit from external knowledge, but the lack of external knowledge resources and the difficulty in finding relevant knowledge limit the development of this technology. To this end, we propose a knowledge-driven dialogue task using dynamic service information. Specifically, we use a large number of service APIs that can provide high coverage and spatiotemporal sensitivity as external knowledge sources. The dialogue system generates queries to request external services along with user information, get the relevant knowledge, and generate responses based on this knowledge. To implement this method, we collect and release the first open domain Chinese service knowledge dialogue dataset DuSinc. At the same time, we construct a baseline model PLATO-SINC, which realizes the automatic utilization of service information for dialogue. Both automatic evaluation and human evaluation show that our proposed new method can significantly improve the effect of open-domain conversation, and the session-level overall score in human evaluation is improved by 59.29% compared with the dialogue pre-training model PLATO-2. The dataset and benchmark model will be open sourced.
Bi-SimCut: A Simple Strategy for Boosting Neural Machine Translation
Jun 06, 2022
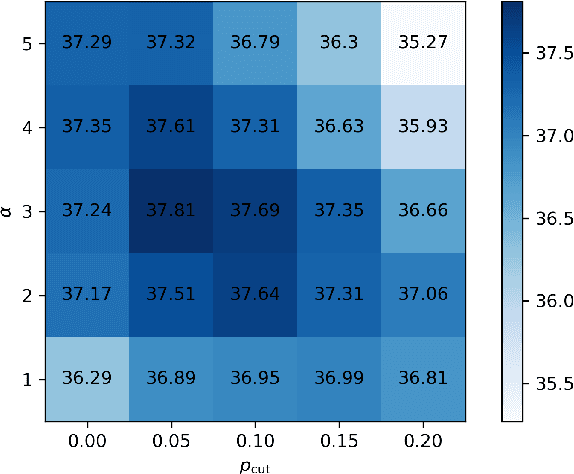
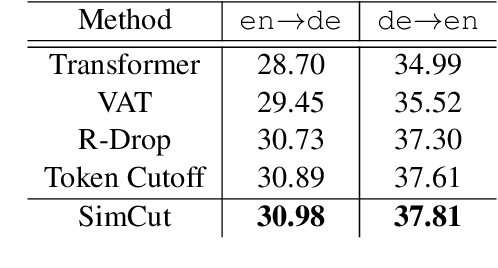
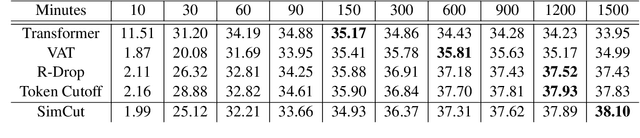
We introduce Bi-SimCut: a simple but effective training strategy to boost neural machine translation (NMT) performance. It consists of two procedures: bidirectional pretraining and unidirectional finetuning. Both procedures utilize SimCut, a simple regularization method that forces the consistency between the output distributions of the original and the cutoff sentence pairs. Without leveraging extra dataset via back-translation or integrating large-scale pretrained model, Bi-SimCut achieves strong translation performance across five translation benchmarks (data sizes range from 160K to 20.2M): BLEU scores of 31.16 for en -> de and 38.37 for de -> en on the IWSLT14 dataset, 30.78 for en -> de and 35.15 for de -> en on the WMT14 dataset, and 27.17 for zh -> en on the WMT17 dataset. SimCut is not a new method, but a version of Cutoff (Shen et al., 2020) simplified and adapted for NMT, and it could be considered as a perturbation-based method. Given the universality and simplicity of SimCut and Bi-SimCut, we believe they can serve as strong baselines for future NMT research.
Less Learn Shortcut: Analyzing and Mitigating Learning of Spurious Feature-Label Correlation
May 25, 2022
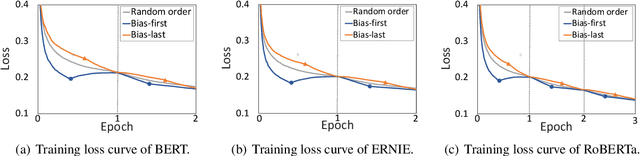
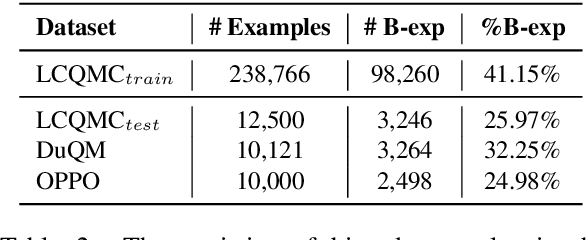
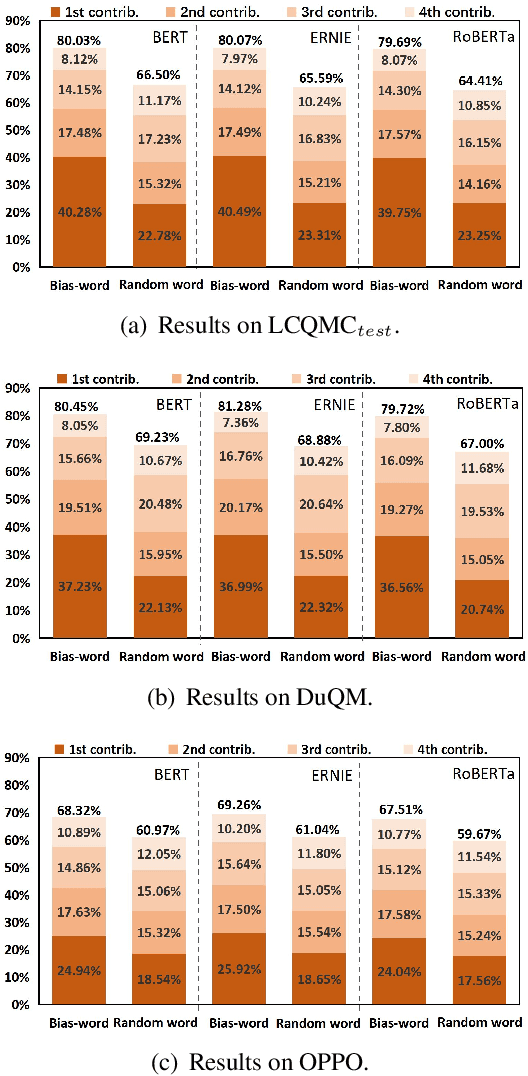
Many recent works indicate that the deep neural networks tend to take dataset biases as shortcuts to make decision, rather than understand the tasks, which results in failures on the real-world applications. In this work, we focus on the spurious correlation between feature and label, which derive from the biased data distribution in the training data, and analyze it concretely. In particular, we define the word highly co-occurring with a specific label as biased word, and the example containing biased word as biased example. Our analysis reveals that the biased examples with spurious correlations are easier for models to learn, and when predicting, the biased words make significantly higher contributions to models' predictions than other words, and the models tend to assign the labels over-relying on the spurious correlation between words and labels. To mitigate the model's over-reliance on the shortcut, we propose a training strategy Less-Learn-Shortcut (LLS): we quantify the biased degree of the biased examples, and down-weight them with the biased degree. Experimental results on QM and NLI tasks show that the models improve the performances both on in-domain and adversarial data (1.57% on DuQM and 2.12% on HANS) with our LLS.