 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing What You Miss: Vision-Language Pre-training with Semantic Completion Learning
Nov 24, 2022Cross-modal alignment is essential for vision-language pre-training (VLP) models to learn the correct corresponding information across different modalities. For this purpose, inspired by the success of masked language modeling (MLM) tasks in the NLP pre-training area, numerous masked modeling tasks have been proposed for VLP to further promote cross-modal interactions. The core idea of previous masked modeling tasks is to focus on reconstructing the masked tokens based on visible context for learning local-to-local alignment. However, most of them pay little attention to the global semantic features generated for the masked data, resulting in the limited cross-modal alignment ability of global representations. Therefore, in this paper, we propose a novel Semantic Completion Learning (SCL) task, complementary to existing masked modeling tasks, to facilitate global-to-local alignment. Specifically, the SCL task complements the missing semantics of masked data by capturing the corresponding information from the other modality, promoting learning more representative global features which have a great impact on the performance of downstream tasks. Moreover, we present a flexible vision encoder, which enables our model to perform image-text and video-text multimodal tasks simultaneously. Experimental results show that our proposed method obtains state-of-the-art performance on various vision-language benchmarks, such as visual question answering, image-text retrieval, and video-text retrieval.
MAP: Modality-Agnostic Uncertainty-Aware Vision-Language Pre-training Model
Oct 11, 2022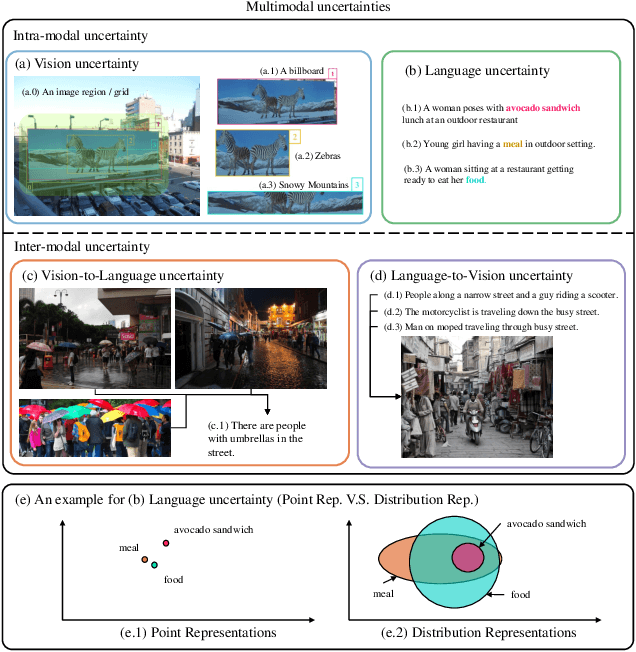
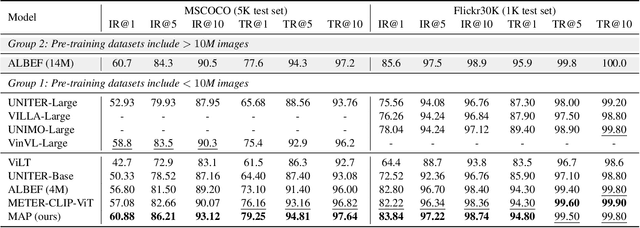
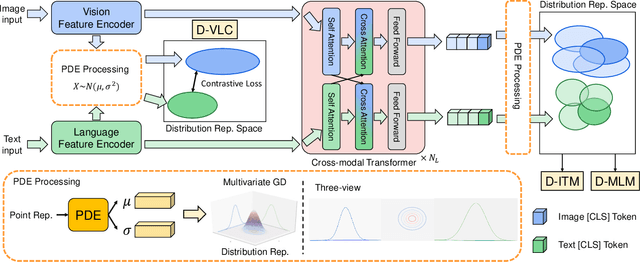
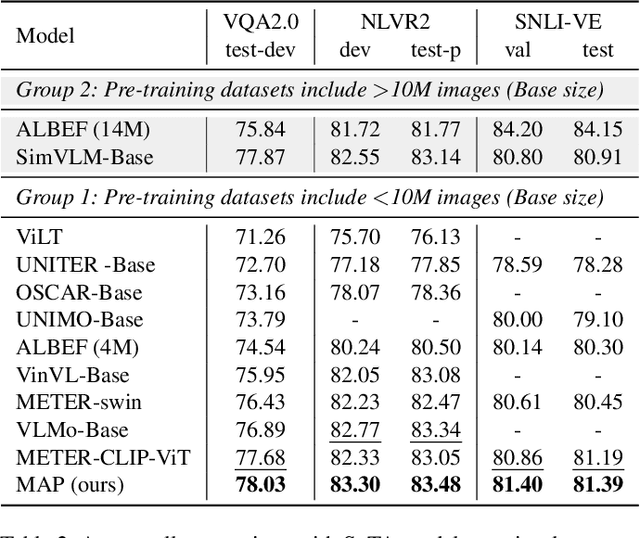
Multimodal semantic understanding often has to deal with uncertainty, which means the obtained message tends to refer to multiple targets. Such uncertainty is problematic for our interpretation, including intra-modal and inter-modal uncertainty. Little effort studies the modeling of this uncertainty, particularly in pre-training on unlabeled datasets and fine-tuning in task-specific downstream tasks. To address this, we project the representations of all modalities as probabilistic distributions via a Probability Distribution Encoder (PDE) by utilizing rich multimodal semantic information. Furthermore, we integrate uncertainty modeling with popular pre-training frameworks and propose suitable pre-training tasks: Distribution-based Vision-Language Contrastive learning (D-VLC), Distribution-based Masked Language Modeling (D-MLM), and Distribution-based Image-Text Matching (D-ITM). The fine-tuned models are applied to challenging downstream tasks, including image-text retrieval, visual question answering, visual reasoning, and visual entailment, and achieve state-of-the-art results. Code is released at https://github.com/IIGROUP/MAP.
Unsupervised Hashing with Semantic Concept Mining
Sep 23, 2022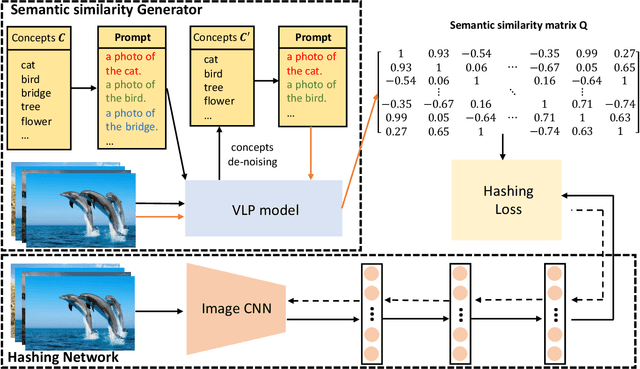
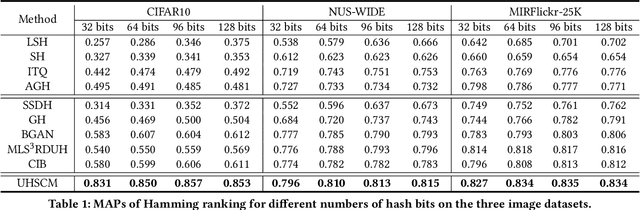
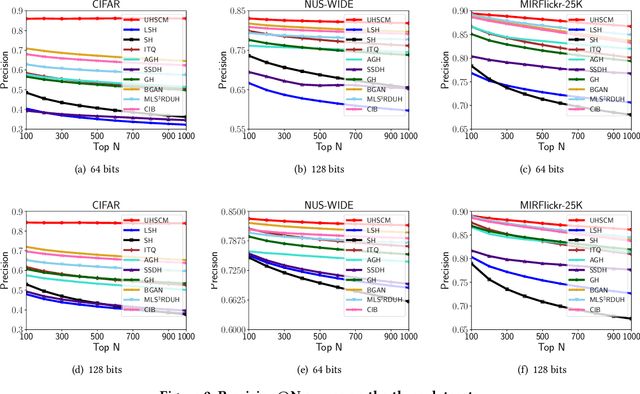
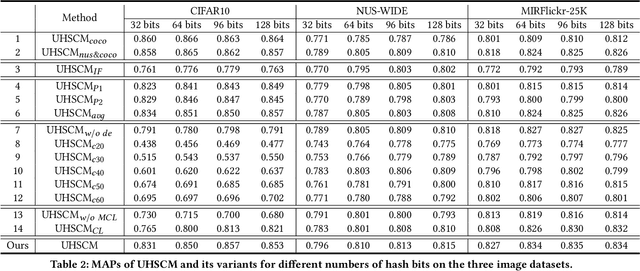
Recently, to improve the unsupervised image retrieval performance, plenty of unsupervised hashing methods have been proposed by designing a semantic similarity matrix, which is based on the similarities between image features extracted by a pre-trained CNN model. However, most of these methods tend to ignore high-level abstract semantic concepts contained in images. Intuitively, concepts play an important role in calculating the similarity among images. In real-world scenarios, each image is associated with some concepts, and the similarity between two images will be larger if they share more identical concepts. Inspired by the above intuition, in this work, we propose a novel Unsupervised Hashing with Semantic Concept Mining, called UHSCM, which leverages a VLP model to construct a high-quality similarity matrix. Specifically, a set of randomly chosen concepts is first collected. Then, by employing a vision-language pretraining (VLP) model with the prompt engineering which has shown strong power in visual representation learning, the set of concepts is denoised according to the training images. Next, the proposed method UHSCM applies the VLP model with prompting again to mine the concept distribution of each image and construct a high-quality semantic similarity matrix based on the mined concept distributions. Finally, with the semantic similarity matrix as guiding information, a novel hashing loss with a modified contrastive loss based regularization item is proposed to optimize the hashing network. Extensive experiments on three benchmark datasets show that the proposed method outperforms the state-of-the-art baselines in the image retrieval task.
Adaptive Perception Transformer for Temporal Action Localization
Aug 25, 2022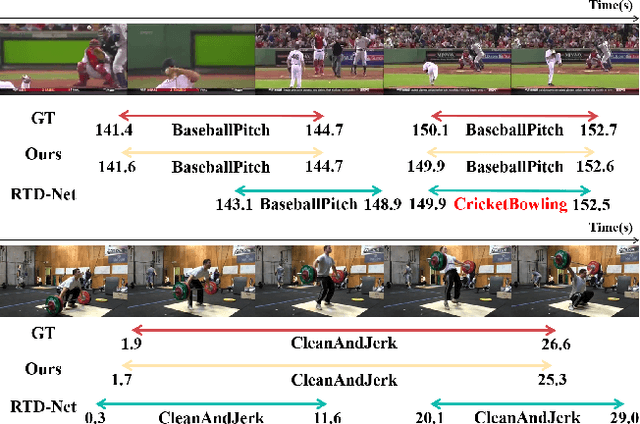
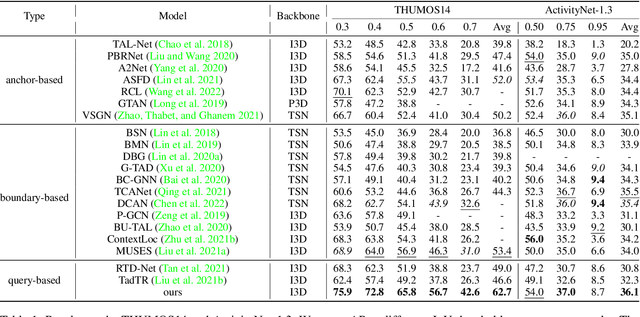
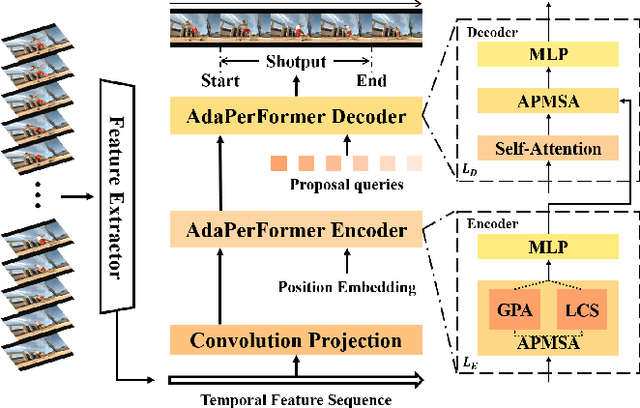
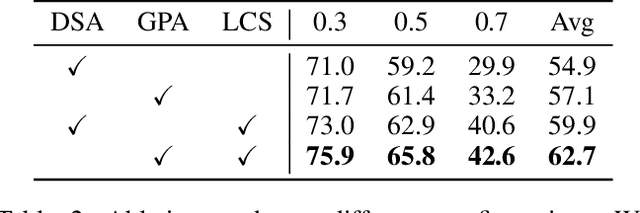
Temporal action localization aims to predict the boundary and category of each action instance in untrimmed long videos. Most of previous methods based on anchors or proposals neglect the global-local context interaction in entire video sequences. Besides, their multi-stage designs cannot generate action boundaries and categories straightforwardly. To address the above issues, this paper proposes a novel end-to-end model, called adaptive perception transformer (AdaPerFormer for short). Specifically, AdaPerFormer explores a dual-branch multi-head self-attention mechanism. One branch takes care of the global perception attention, which can model entire video sequences and aggregate global relevant contexts. While the other branch concentrates on the local convolutional shift to aggregate intra-frame and inter-frame information through our bidirectional shift operation. The end-to-end nature produces the boundaries and categories of video actions without extra steps. Extensive experiments together with ablation studies are provided to reveal the effectiveness of our design. Our method achieves a state-of-the-art accuracy on the THUMOS14 dataset (65.8\% in terms of mAP@0.5, 42.6\% mAP@0.7, and 62.7\% mAP@Avg), and obtains competitive performance on the ActivityNet-1.3 dataset with an average mAP of 36.1\%. The code and models are available at https://github.com/SouperO/AdaPerFormer.
DPTNet: A Dual-Path Transformer Architecture for Scene Text Detection
Aug 21, 2022
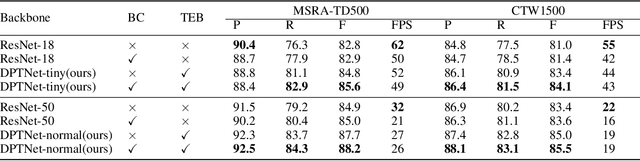
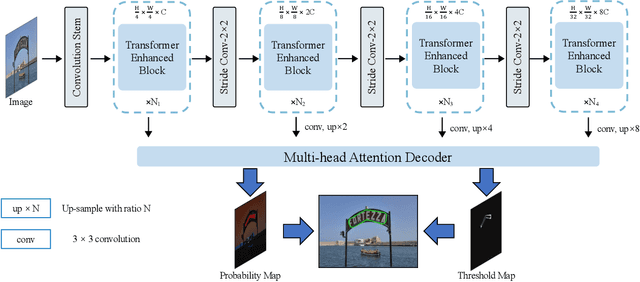
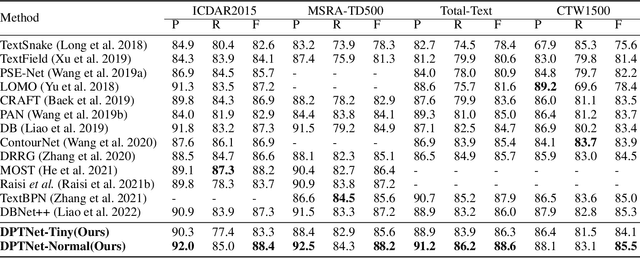
The prosperity of deep learning contributes to the rapid progress in scene text detection. Among all the methods with convolutional networks, segmentation-based ones have drawn extensive attention due to their superiority in detecting text instances of arbitrary shapes and extreme aspect ratios. However, the bottom-up methods are limited to the performance of their segmentation models. In this paper, we propose DPTNet (Dual-Path Transformer Network), a simple yet effective architecture to model the global and local information for the scene text detection task. We further propose a parallel design that integrates the convolutional network with a powerful self-attention mechanism to provide complementary clues between the attention path and convolutional path. Moreover, a bi-directional interaction module across the two paths is developed to provide complementary clues in the channel and spatial dimensions. We also upgrade the concentration operation by adding an extra multi-head attention layer to it. Our DPTNet achieves state-of-the-art results on the MSRA-TD500 dataset, and provides competitive results on other standard benchmarks in terms of both detection accuracy and speed.
Boosting Multi-Modal E-commerce Attribute Value Extraction via Unified Learning Scheme and Dynamic Range Minimization
Jul 15, 2022
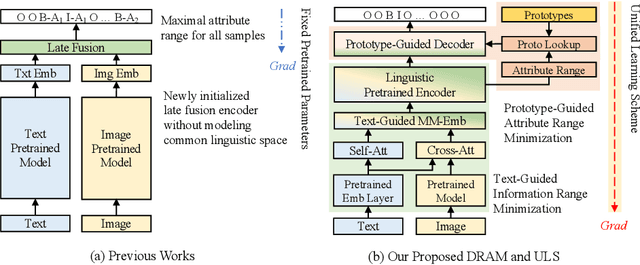
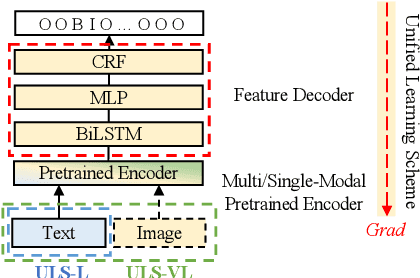

With the prosperity of e-commerce industry, various modalities, e.g., vision and language, are utilized to describe product items. It is an enormous challenge to understand such diversified data, especially via extracting the attribute-value pairs in text sequences with the aid of helpful image regions. Although a series of previous works have been dedicated to this task, there remain seldomly investigated obstacles that hinder further improvements: 1) Parameters from up-stream single-modal pretraining are inadequately applied, without proper jointly fine-tuning in a down-stream multi-modal task. 2) To select descriptive parts of images, a simple late fusion is widely applied, regardless of priori knowledge that language-related information should be encoded into a common linguistic embedding space by stronger encoders. 3) Due to diversity across products, their attribute sets tend to vary greatly, but current approaches predict with an unnecessary maximal range and lead to more potential false positives. To address these issues, we propose in this paper a novel approach to boost multi-modal e-commerce attribute value extraction via unified learning scheme and dynamic range minimization: 1) Firstly, a unified scheme is designed to jointly train a multi-modal task with pretrained single-modal parameters. 2) Secondly, a text-guided information range minimization method is proposed to adaptively encode descriptive parts of each modality into an identical space with a powerful pretrained linguistic model. 3) Moreover, a prototype-guided attribute range minimization method is proposed to first determine the proper attribute set of the current product, and then select prototypes to guide the prediction of the chosen attributes. Experiments on the popular multi-modal e-commerce benchmarks show that our approach achieves superior performance over the other state-of-the-art techniques.
Egocentric Video-Language Pretraining @ Ego4D Challenge 2022
Jul 04, 2022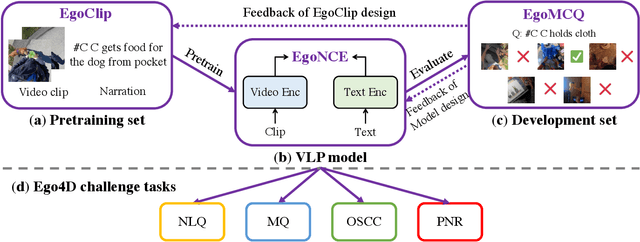
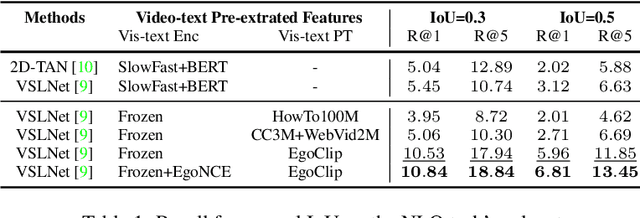
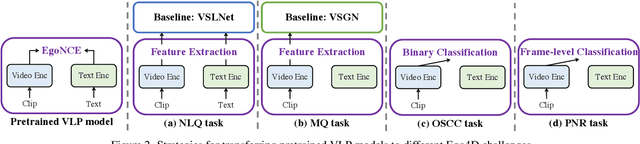
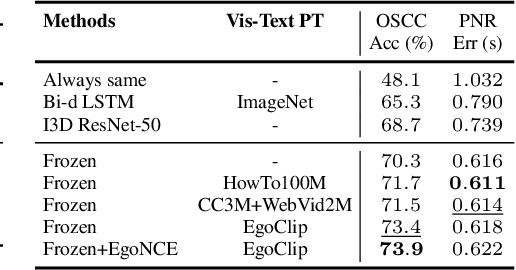
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for four Ego4D challenge tasks, including Natural Language Query (NLQ), Moment Query (MQ), Object State Change Classification (OSCC), and PNR Localization (PNR). Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation or video-only representation to several video downstream tasks. Our Egocentric VLP achieves 10.46R@1&IoU @0.3 on NLQ, 10.33 mAP on MQ, 74% Acc on OSCC, 0.67 sec error on PNR. The code is available at https://github.com/showlab/EgoVLP.
Egocentric Video-Language Pretraining @ EPIC-KITCHENS-100 Multi-Instance Retrieval Challenge 2022
Jul 04, 2022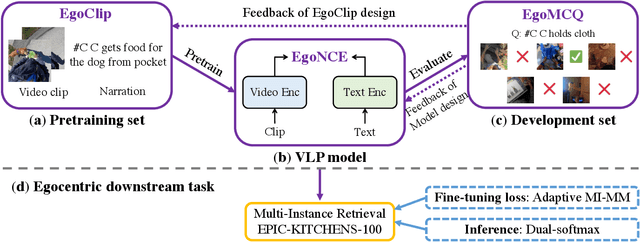
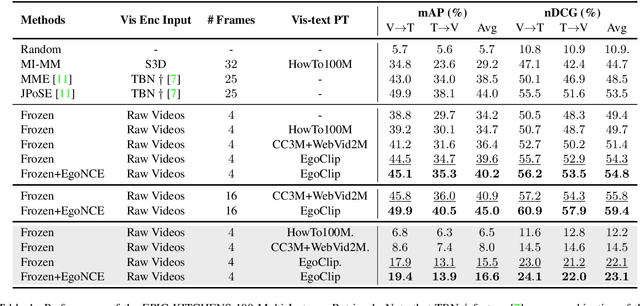
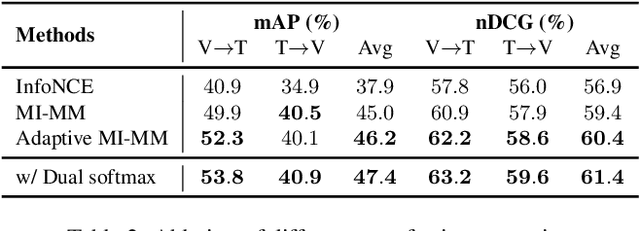
In this report, we propose a video-language pretraining (VLP) based solution \cite{kevin2022egovlp} for the EPIC-KITCHENS-100 Multi-Instance Retrieval (MIR) challenge. Especially, we exploit the recently released Ego4D dataset \cite{grauman2021ego4d} to pioneer Egocentric VLP from pretraining dataset, pretraining objective, and development set. Based on the above three designs, we develop a pretrained video-language model that is able to transfer its egocentric video-text representation to MIR benchmark. Furthermore, we devise an adaptive multi-instance max-margin loss to effectively fine-tune the model and equip the dual-softmax technique for reliable inference. Our best single model obtains strong performance on the challenge test set with 47.39% mAP and 61.44% nDCG. The code is available at https://github.com/showlab/EgoVLP.
Egocentric Video-Language Pretraining
Jun 03, 2022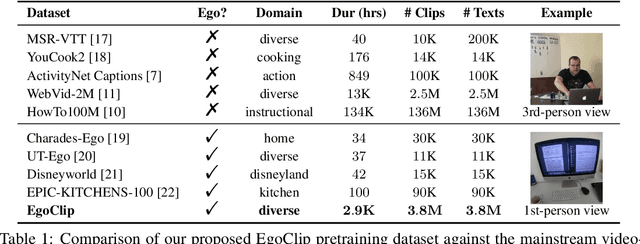
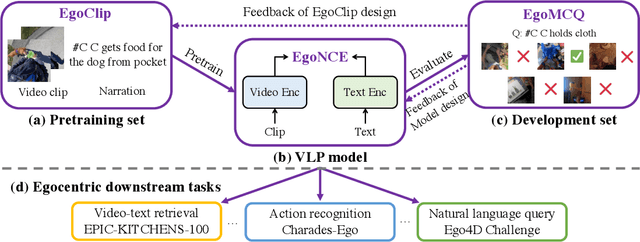

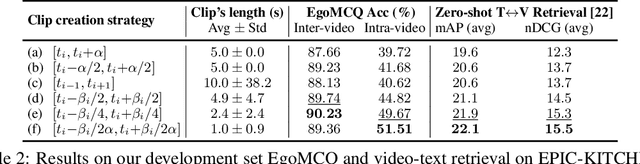
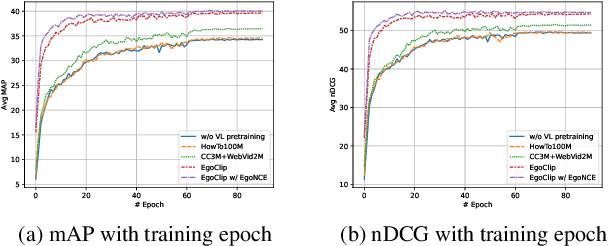
Video-Language Pretraining (VLP), aiming to learn transferable representation to advance a wide range of video-text downstream tasks, has recently received increasing attention. Dominant works that achieve strong performance rely on large-scale, 3rd-person video-text datasets, such as HowTo100M. In this work, we exploit the recently released Ego4D dataset to pioneer Egocentric VLP along three directions. (i) We create EgoClip, a 1st-person video-text pretraining dataset comprising 3.8M clip-text pairs well-chosen from Ego4D, covering a large variety of human daily activities. (ii) We propose a novel pretraining objective, dubbed as EgoNCE, which adapts video-text contrastive learning to egocentric domain by mining egocentric-aware positive and negative samples. (iii) We introduce EgoMCQ, a development benchmark that is close to EgoClip and hence can support effective validation and fast exploration of our design decisions regarding EgoClip and EgoNCE. Furthermore, we demonstrate strong performance on five egocentric downstream tasks across three datasets: video-text retrieval on EPIC-KITCHENS-100; action recognition on Charades-Ego; and natural language query, moment query, and object state change classification on Ego4D challenge benchmarks. The dataset and code will be available at https://github.com/showlab/EgoVLP.
HunYuan_tvr for Text-Video Retrivial
Apr 14, 2022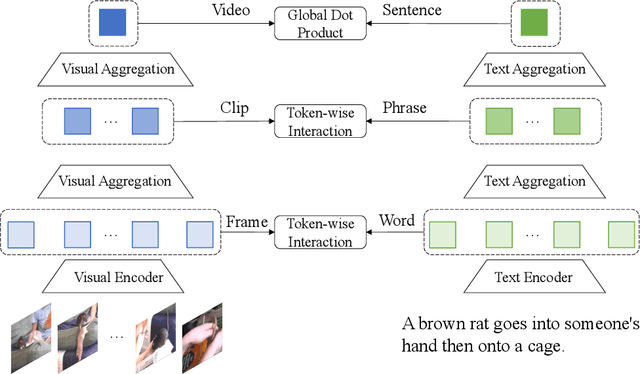
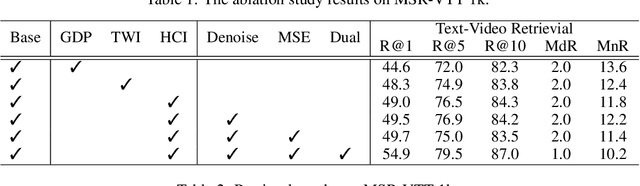
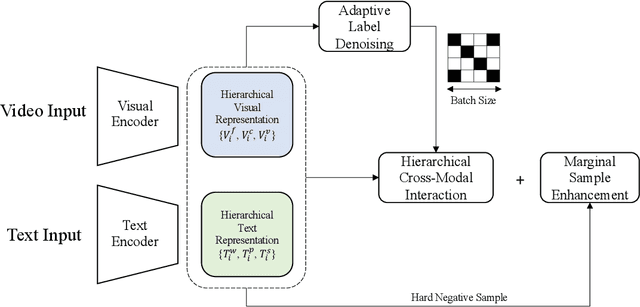
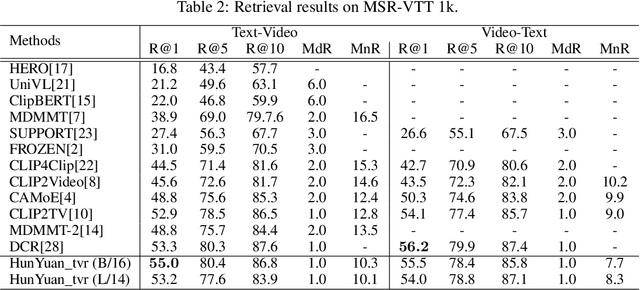
Text-Video Retrieval plays an important role in multi-modal understanding and has attracted increasing attention in recent years. Most existing methods focus on constructing contrastive pairs between whole videos and complete caption sentences, while ignoring fine-grained cross-modal relationships, e.g., short clips and phrases or single frame and word. In this paper, we propose a novel method, named HunYuan\_tvr, to explore hierarchical cross-modal interactions by simultaneously exploring video-sentence, clip-phrase, and frame-word relationships. Considering intrinsic semantic relations between frames, HunYuan\_tvr first performs self-attention to explore frame-wise correlations and adaptively clusters correlated frames into clip-level representations. Then, the clip-wise correlation is explored to aggregate clip representations into a compact one to describe the video globally. In this way, we can construct hierarchical video representations for frame-clip-video granularities, and also explore word-wise correlations to form word-phrase-sentence embeddings for the text modality. Finally, hierarchical contrastive learning is designed to explore cross-modal relationships,~\emph{i.e.,} frame-word, clip-phrase, and video-sentence, which enables HunYuan\_tvr to achieve a comprehensive multi-modal understanding. Further boosted by adaptive label denosing and marginal sample enhancement, HunYuan\_tvr obtains new state-of-the-art results on various benchmarks, e.g., Rank@1 of 55.0%, 57.8%, 29.7%, 52.1%, and 57.3% on MSR-VTT, MSVD, LSMDC, DiDemo, and ActivityNet respectively.