 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAP: Modality-Agnostic Uncertainty-Aware Vision-Language Pre-training Model
Paper and Code
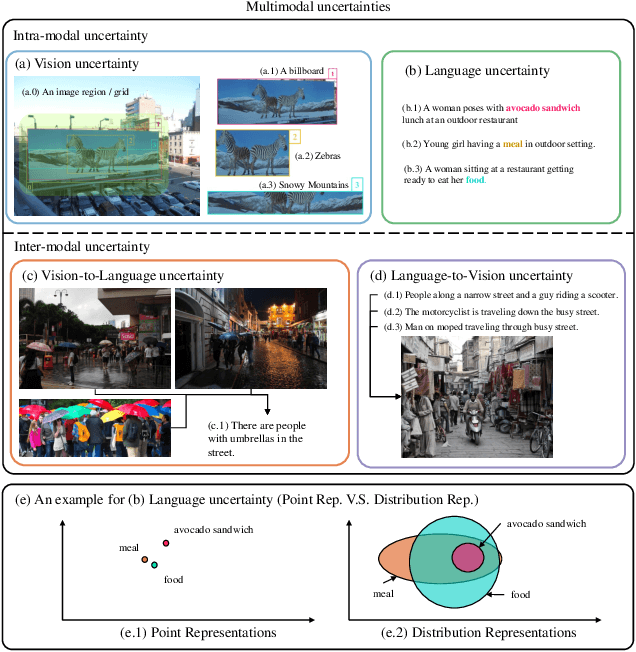
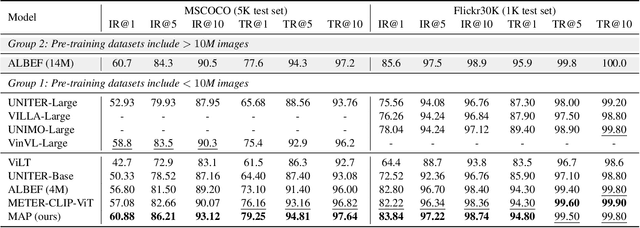
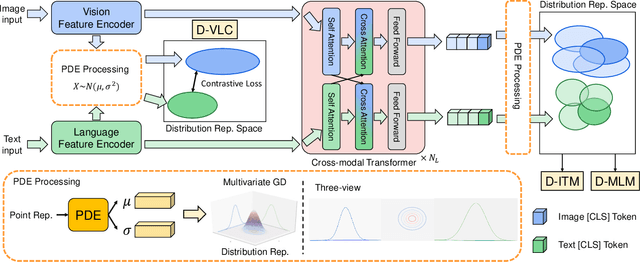
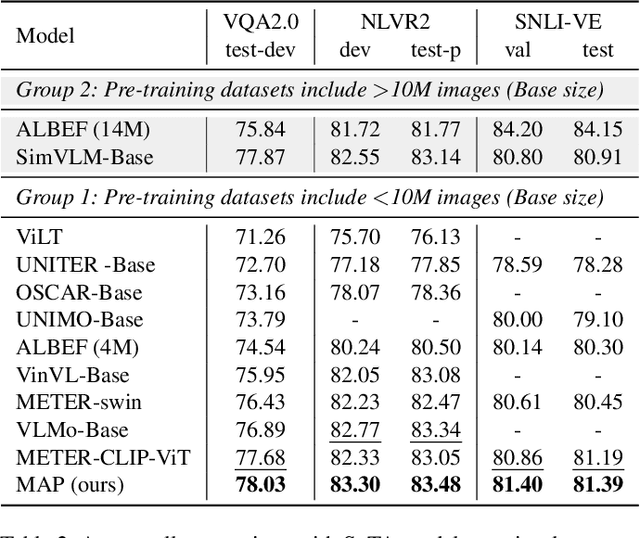
Multimodal semantic understanding often has to deal with uncertainty, which means the obtained message tends to refer to multiple targets. Such uncertainty is problematic for our interpretation, including intra-modal and inter-modal uncertainty. Little effort studies the modeling of this uncertainty, particularly in pre-training on unlabeled datasets and fine-tuning in task-specific downstream tasks. To address this, we project the representations of all modalities as probabilistic distributions via a Probability Distribution Encoder (PDE) by utilizing rich multimodal semantic information. Furthermore, we integrate uncertainty modeling with popular pre-training frameworks and propose suitable pre-training tasks: Distribution-based Vision-Language Contrastive learning (D-VLC), Distribution-based Masked Language Modeling (D-MLM), and Distribution-based Image-Text Matching (D-ITM). The fine-tuned models are applied to challenging downstream tasks, including image-text retrieval, visual question answering, visual reasoning, and visual entailment, and achieve state-of-the-art results. Code is released at https://github.com/IIGROUP/MAP.