 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUSE: A Data Expansion Framework for Low-resource Automatic Modulation Recognition based on Active Learning
Jul 16, 2025Although deep neural networks have made remarkable achievements in the field of automatic modulation recognition (AMR), these models often require a large amount of labeled data for training. However, in many practical scenarios, the available target domain data is scarce and difficult to meet the needs of model training. The most direct way is to collect data manually and perform expert annotation, but the high time and labor costs are unbearable. Another common method is data augmentation. Although it can enrich training samples to a certain extent, it does not introduce new data and therefore cannot fundamentally solve the problem of data scarcity. To address these challenges, we introduce a data expansion framework called Dynamic Uncertainty-driven Sample Expansion (DUSE). Specifically, DUSE uses an uncertainty scoring function to filter out useful samples from relevant AMR datasets and employs an active learning strategy to continuously refine the scorer. Extensive experiments demonstrate that DUSE consistently outperforms 8 coreset selection baselines in both class-balance and class-imbalance settings. Besides, DUSE exhibits strong cross-architecture generalization for unseen models.
Advancing Multimodal Reasoning Capabilities of Multimodal Large Language Models via Visual Perception Reward
Jun 08, 2025Enhancing the multimodal reasoning capabilities of Multimodal Large Language Models (MLLMs) is a challenging task that has attracted increasing attention in the community. Recently, several studies have applied Reinforcement Learning with Verifiable Rewards (RLVR) to the multimodal domain in order to enhance the reasoning abilities of MLLMs. However, these works largely overlook the enhancement of multimodal perception capabilities in MLLMs, which serve as a core prerequisite and foundational component of complex multimodal reasoning. Through McNemar's test, we find that existing RLVR method fails to effectively enhance the multimodal perception capabilities of MLLMs, thereby limiting their further improvement in multimodal reasoning. To address this limitation, we propose Perception-R1, which introduces a novel visual perception reward that explicitly encourages MLLMs to perceive the visual content accurately, thereby can effectively incentivizing both their multimodal perception and reasoning capabilities. Specifically, we first collect textual visual annotations from the CoT trajectories of multimodal problems, which will serve as visual references for reward assignment. During RLVR training, we employ a judging LLM to assess the consistency between the visual annotations and the responses generated by MLLM, and assign the visual perception reward based on these consistency judgments. Extensive experiments on several multimodal reasoning benchmarks demonstrate the effectiveness of our Perception-R1, which achieves state-of-the-art performance on most benchmarks using only 1,442 training data.
Boosting Multi-Modal E-commerce Attribute Value Extraction via Unified Learning Scheme and Dynamic Range Minimization
Jul 15, 2022
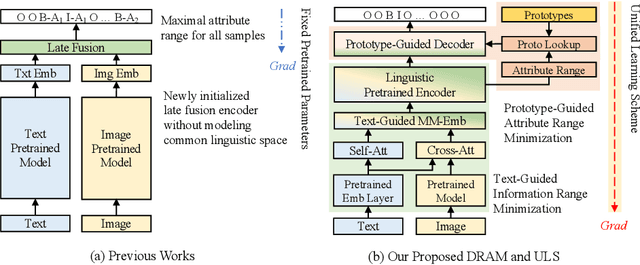
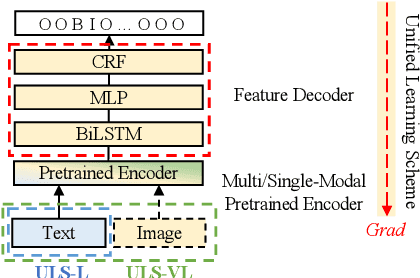

With the prosperity of e-commerce industry, various modalities, e.g., vision and language, are utilized to describe product items. It is an enormous challenge to understand such diversified data, especially via extracting the attribute-value pairs in text sequences with the aid of helpful image regions. Although a series of previous works have been dedicated to this task, there remain seldomly investigated obstacles that hinder further improvements: 1) Parameters from up-stream single-modal pretraining are inadequately applied, without proper jointly fine-tuning in a down-stream multi-modal task. 2) To select descriptive parts of images, a simple late fusion is widely applied, regardless of priori knowledge that language-related information should be encoded into a common linguistic embedding space by stronger encoders. 3) Due to diversity across products, their attribute sets tend to vary greatly, but current approaches predict with an unnecessary maximal range and lead to more potential false positives. To address these issues, we propose in this paper a novel approach to boost multi-modal e-commerce attribute value extraction via unified learning scheme and dynamic range minimization: 1) Firstly, a unified scheme is designed to jointly train a multi-modal task with pretrained single-modal parameters. 2) Secondly, a text-guided information range minimization method is proposed to adaptively encode descriptive parts of each modality into an identical space with a powerful pretrained linguistic model. 3) Moreover, a prototype-guided attribute range minimization method is proposed to first determine the proper attribute set of the current product, and then select prototypes to guide the prediction of the chosen attributes. Experiments on the popular multi-modal e-commerce benchmarks show that our approach achieves superior performance over the other state-of-the-art techniques.
High Noise Immune Time-domain Inversion via Cascade Network for Complex Scatterers
Mar 03, 2022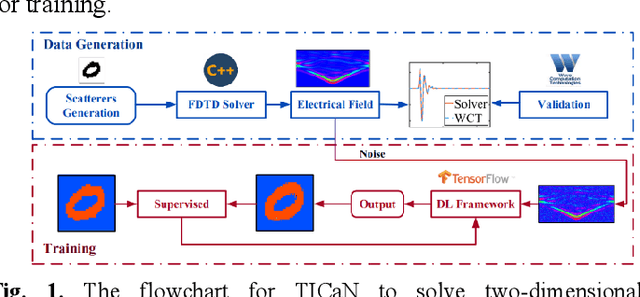
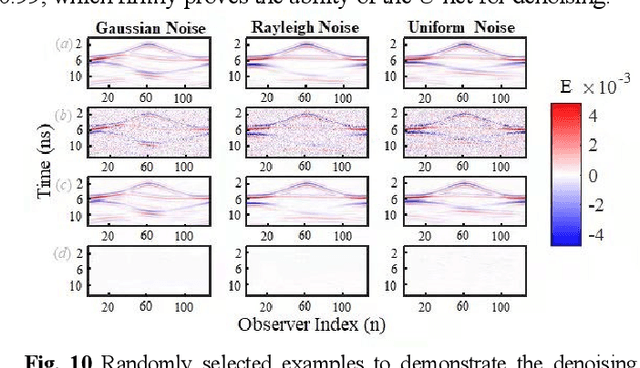
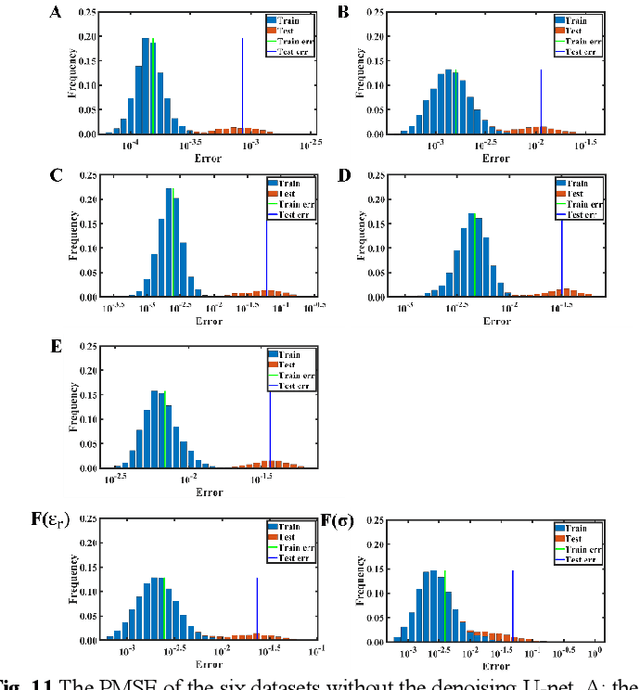
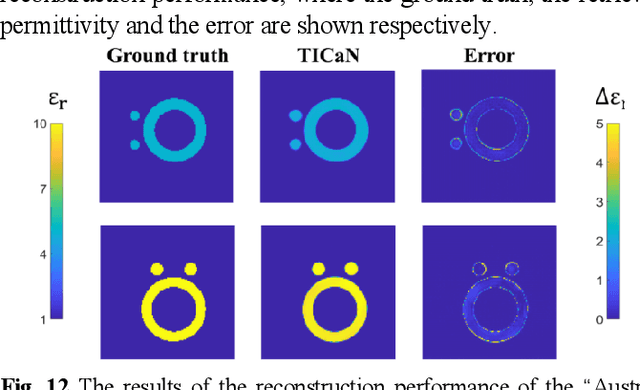
In this paper, a high noise immune time-domain inversion cascade network (TICaN) is proposed to reconstruct scatterers from the measured electromagnetic fields. The TICaN is comprised of a denoising block aiming at improving the signal-to-noise ratio, and an inversion block to reconstruct the electromagnetic properties from the raw time-domain measurements. The scatterers investigated in this study include complicated geometry shapes and high contrast, which cover the stratum layer, lossy medium and hyperfine structure, etc. After being well trained, the performance of the TICaN is evaluated from the perspective of accuracy, noise-immunity, computational acceleration, and generalizability. It can be proven that the proposed framework can realize high-precision inversion under high-intensity noise environments. Compared with traditional reconstruction methods, TICaN avoids the tedious iterative calculation by utilizing the parallel computing ability of GPU and thus significantly reduce the computing time. Besides, the proposed TICaN has certain generalization ability in reconstructing the unknown scatterers such as the famous Austria rings. Herein, it is confident that the proposed TICaN will serve as a new path for real-time quantitative microwave imaging for various practical scenarios.