 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoubly Stochastic Models: Learning with Unbiased Label Noises and Inference Stability
Apr 01, 2023Random label noises (or observational noises) widely exist in practical machine learning settings. While previous studies primarily focus on the affects of label noises to the performance of learning, our work intends to investigate the implicit regularization effects of the label noises, under mini-batch sampling settings of stochastic gradient descent (SGD), with assumptions that label noises are unbiased. Specifically, we analyze the learning dynamics of SGD over the quadratic loss with unbiased label noises, where we model the dynamics of SGD as a stochastic differentiable equation (SDE) with two diffusion terms (namely a Doubly Stochastic Model). While the first diffusion term is caused by mini-batch sampling over the (label-noiseless) loss gradients as many other works on SGD, our model investigates the second noise term of SGD dynamics, which is caused by mini-batch sampling over the label noises, as an implicit regularizer. Our theoretical analysis finds such implicit regularizer would favor some convergence points that could stabilize model outputs against perturbation of parameters (namely inference stability). Though similar phenomenon have been investigated, our work doesn't assume SGD as an Ornstein-Uhlenbeck like process and achieve a more generalizable result with convergence of approximation proved. To validate our analysis, we design two sets of empirical studies to analyze the implicit regularizer of SGD with unbiased random label noises for deep neural networks training and linear regression.
Video4MRI: An Empirical Study on Brain Magnetic Resonance Image Analytics with CNN-based Video Classification Frameworks
Feb 24, 2023To address the problem of medical image recognition, computer vision techniques like convolutional neural networks (CNN) are frequently used. Recently, 3D CNN-based models dominate the field of magnetic resonance image (MRI) analytics. Due to the high similarity between MRI data and videos, we conduct extensive empirical studies on video recognition techniques for MRI classification to answer the questions: (1) can we directly use video recognition models for MRI classification, (2) which model is more appropriate for MRI, (3) are the common tricks like data augmentation in video recognition still useful for MRI classification? Our work suggests that advanced video techniques benefit MRI classification. In this paper, four datasets of Alzheimer's and Parkinson's disease recognition are utilized in experiments, together with three alternative video recognition models and data augmentation techniques that are frequently applied to video tasks. In terms of efficiency, the results reveal that the video framework performs better than 3D-CNN models by 5% - 11% with 50% - 66% less trainable parameters. This report pushes forward the potential fusion of 3D medical imaging and video understanding research.
Towards Long-Term Time-Series Forecasting: Feature, Pattern, and Distribution
Jan 05, 2023



Long-term time-series forecasting (LTTF) has become a pressing demand in many applications, such as wind power supply planning. Transformer models have been adopted to deliver high prediction capacity because of the high computational self-attention mechanism. Though one could lower the complexity of Transformers by inducing the sparsity in point-wise self-attentions for LTTF, the limited information utilization prohibits the model from exploring the complex dependencies comprehensively. To this end, we propose an efficient Transformerbased model, named Conformer, which differentiates itself from existing methods for LTTF in three aspects: (i) an encoder-decoder architecture incorporating a linear complexity without sacrificing information utilization is proposed on top of sliding-window attention and Stationary and Instant Recurrent Network (SIRN); (ii) a module derived from the normalizing flow is devised to further improve the information utilization by inferring the outputs with the latent variables in SIRN directly; (iii) the inter-series correlation and temporal dynamics in time-series data are modeled explicitly to fuel the downstream self-attention mechanism. Extensive experiments on seven real-world datasets demonstrate that Conformer outperforms the state-of-the-art methods on LTTF and generates reliable prediction results with uncertainty quantification.
Learning from Training Dynamics: Identifying Mislabeled Data Beyond Manually Designed Features
Dec 20, 2022



While mislabeled or ambiguously-labeled samples in the training set could negatively affect the performance of deep models, diagnosing the dataset and identifying mislabeled samples helps to improve the generalization power. Training dynamics, i.e., the traces left by iterations of optimization algorithms, have recently been proved to be effective to localize mislabeled samples with hand-crafted features. In this paper, beyond manually designed features, we introduce a novel learning-based solution, leveraging a noise detector, instanced by an LSTM network, which learns to predict whether a sample was mislabeled using the raw training dynamics as input. Specifically, the proposed method trains the noise detector in a supervised manner using the dataset with synthesized label noises and can adapt to various datasets (either naturally or synthesized label-noised) without retraining. We conduct extensive experiments to evaluate the proposed method. We train the noise detector based on the synthesized label-noised CIFAR dataset and test such noise detector on Tiny ImageNet, CUB-200, Caltech-256, WebVision and Clothing1M. Results show that the proposed method precisely detects mislabeled samples on various datasets without further adaptation, and outperforms state-of-the-art methods. Besides, more experiments demonstrate that the mislabel identification can guide a label correction, namely data debugging, providing orthogonal improvements of algorithm-centric state-of-the-art techniques from the data aspect.
Temporal Output Discrepancy for Loss Estimation-based Active Learning
Dec 20, 2022



While deep learning succeeds in a wide range of tasks, it highly depends on the massive collection of annotated data which is expensive and time-consuming. To lower the cost of data annotation, active learning has been proposed to interactively query an oracle to annotate a small proportion of informative samples in an unlabeled dataset. Inspired by the fact that the samples with higher loss are usually more informative to the model than the samples with lower loss, in this paper we present a novel deep active learning approach that queries the oracle for data annotation when the unlabeled sample is believed to incorporate high loss. The core of our approach is a measurement Temporal Output Discrepancy (TOD) that estimates the sample loss by evaluating the discrepancy of outputs given by models at different optimization steps. Our theoretical investigation shows that TOD lower-bounds the accumulated sample loss thus it can be used to select informative unlabeled samples. On basis of TOD, we further develop an effective unlabeled data sampling strategy as well as an unsupervised learning criterion for active learning. Due to the simplicity of TOD, our methods are efficient, flexible, and task-agnostic. Extensive experimental results demonstrate that our approach achieves superior performances than the state-of-the-art active learning methods on image classification and semantic segmentation tasks. In addition, we show that TOD can be utilized to select the best model of potentially the highest testing accuracy from a pool of candidate models.
ExpNet: A unified network for Expert-Level Classification
Nov 29, 2022



Different from the general visual classification, some classification tasks are more challenging as they need the professional categories of the images. In the paper, we call them expert-level classification. Previous fine-grained vision classification (FGVC) has made many efforts on some of its specific sub-tasks. However, they are difficult to expand to the general cases which rely on the comprehensive analysis of part-global correlation and the hierarchical features interaction. In this paper, we propose Expert Network (ExpNet) to address the unique challenges of expert-level classification through a unified network. In ExpNet, we hierarchically decouple the part and context features and individually process them using a novel attentive mechanism, called Gaze-Shift. In each stage, Gaze-Shift produces a focal-part feature for the subsequent abstraction and memorizes a context-related embedding. Then we fuse the final focal embedding with all memorized context-related embedding to make the prediction. Such an architecture realizes the dual-track processing of partial and global information and hierarchical feature interactions. We conduct the experiments over three representative expert-level classification tasks: FGVC, disease classification, and artwork attributes classification. In these experiments, superior performance of our ExpNet is observed comparing to the state-of-the-arts in a wide range of fields, indicating the effectiveness and generalization of our ExpNet. The code will be made publicly available.
GLARE: A Dataset for Traffic Sign Detection in Sun Glare
Sep 19, 2022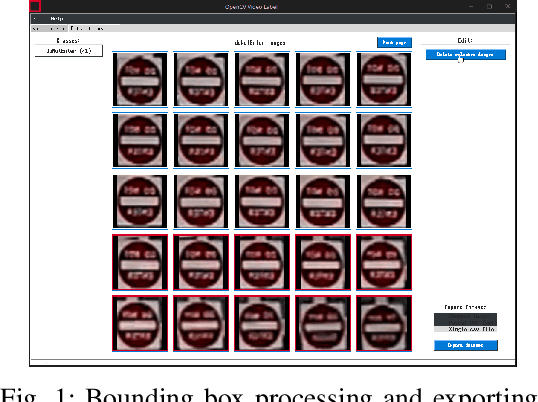
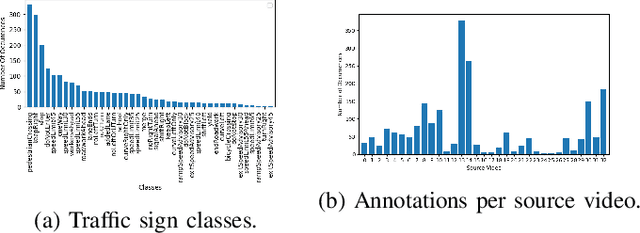

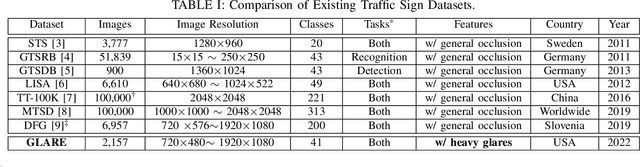
Real-time machine learning detection algorithms are often found within autonomous vehicle technology and depend on quality datasets. It is essential that these algorithms work correctly in everyday conditions as well as under strong sun glare. Reports indicate glare is one of the two most prominent environment-related reasons for crashes. However, existing datasets, such as LISA and the German Traffic Sign Recognition Benchmark, do not reflect the existence of sun glare at all. This paper presents the GLARE traffic sign dataset: a collection of images with U.S based traffic signs under heavy visual interference by sunlight. GLARE contains 2,157 images of traffic signs with sun glare, pulled from 33 videos of dashcam footage of roads in the United States. It provides an essential enrichment to the widely used LISA Traffic Sign dataset. Our experimental study shows that although several state-of-the-art baseline methods demonstrate superior performance when trained and tested against traffic sign datasets without sun glare, they greatly suffer when tested against GLARE (e.g., ranging from 9% to 21% mean mAP, which is significantly lower than the performances on LISA dataset). We also notice that current architectures have better detection accuracy (e.g., on average 42% mean mAP gain for mainstream algorithms) when trained on images of traffic signs in sun glare.
AA-Forecast: Anomaly-Aware Forecast for Extreme Events
Aug 21, 2022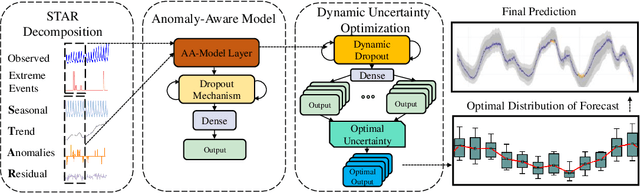
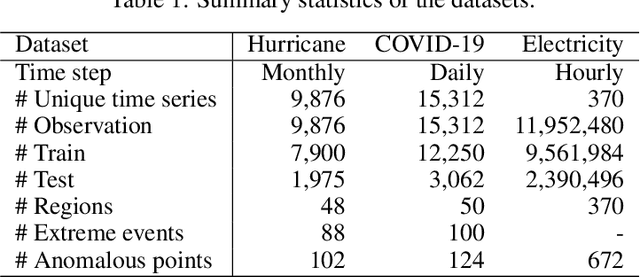
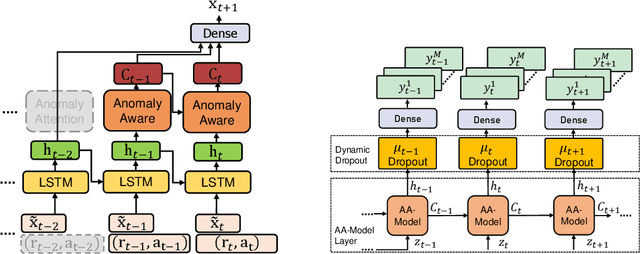

Time series models often deal with extreme events and anomalies, both prevalent in real-world datasets. Such models often need to provide careful probabilistic forecasting, which is vital in risk management for extreme events such as hurricanes and pandemics. However, it is challenging to automatically detect and learn to use extreme events and anomalies for large-scale datasets, which often require manual effort. Hence, we propose an anomaly-aware forecast framework that leverages the previously seen effects of anomalies to improve its prediction accuracy during and after the presence of extreme events. Specifically, the framework automatically extracts anomalies and incorporates them through an attention mechanism to increase its accuracy for future extreme events. Moreover, the framework employs a dynamic uncertainty optimization algorithm that reduces the uncertainty of forecasts in an online manner. The proposed framework demonstrated consistent superior accuracy with less uncertainty on three datasets with different varieties of anomalies over the current prediction models.
$\textbf{P$^2$A}$: A Dataset and Benchmark for Dense Action Detection from Table Tennis Match Broadcasting Videos
Jul 26, 2022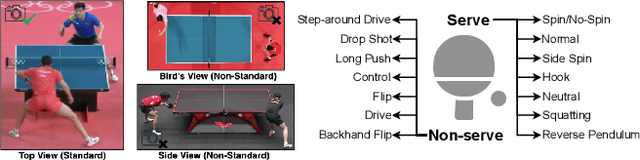
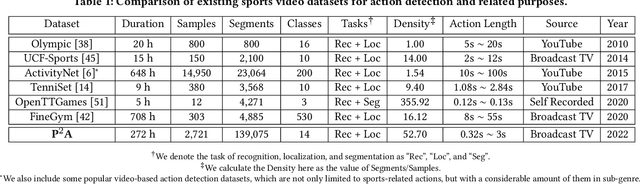

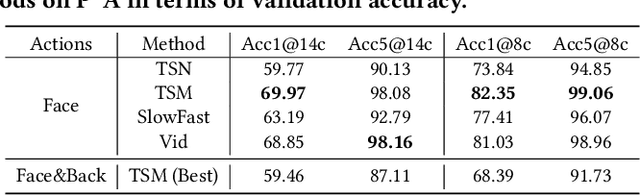
While deep learning has been widely used for video analytics, such as video classification and action detection, dense action detection with fast-moving subjects from sports videos is still challenging. In this work, we release yet another sports video dataset $\textbf{P$^2$A}$ for $\underline{P}$ing $\underline{P}$ong-$\underline{A}$ction detection, which consists of 2,721 video clips collected from the broadcasting videos of professional table tennis matches in World Table Tennis Championships and Olympiads. We work with a crew of table tennis professionals and referees to obtain fine-grained action labels (in 14 classes) for every ping-pong action that appeared in the dataset and formulate two sets of action detection problems - action localization and action recognition. We evaluate a number of commonly-seen action recognition (e.g., TSM, TSN, Video SwinTransformer, and Slowfast) and action localization models (e.g., BSN, BSN++, BMN, TCANet), using $\textbf{P$^2$A}$ for both problems, under various settings. These models can only achieve 48% area under the AR-AN curve for localization and 82% top-one accuracy for recognition since the ping-pong actions are dense with fast-moving subjects but broadcasting videos are with only 25 FPS. The results confirm that $\textbf{P$^2$A}$ is still a challenging task and can be used as a benchmark for action detection from videos.
Distilling Ensemble of Explanations for Weakly-Supervised Pre-Training of Image Segmentation Models
Jul 04, 2022While fine-tuning pre-trained networks has become a popular way to train image segmentation models, such backbone networks for image segmentation are frequently pre-trained using image classification source datasets, e.g., ImageNet. Though image classification datasets could provide the backbone networks with rich visual features and discriminative ability, they are incapable of fully pre-training the target model (i.e., backbone+segmentation modules) in an end-to-end manner. The segmentation modules are left to random initialization in the fine-tuning process due to the lack of segmentation labels in classification datasets. In our work, we propose a method that leverages Pseudo Semantic Segmentation Labels (PSSL), to enable the end-to-end pre-training for image segmentation models based on classification datasets. PSSL was inspired by the observation that the explanation results of classification models, obtained through explanation algorithms such as CAM, SmoothGrad and LIME, would be close to the pixel clusters of visual objects. Specifically, PSSL is obtained for each image by interpreting the classification results and aggregating an ensemble of explanations queried from multiple classifiers to lower the bias caused by single models. With PSSL for every image of ImageNet, the proposed method leverages a weighted segmentation learning procedure to pre-train the segmentation network en masse. Experiment results show that, with ImageNet accompanied by PSSL as the source dataset, the proposed end-to-end pre-training strategy successfully boosts the performance of various segmentation models, i.e., PSPNet-ResNet50, DeepLabV3-ResNet50, and OCRNet-HRNetW18, on a number of segmentation tasks, such as CamVid, VOC-A, VOC-C, ADE20K, and CityScapes, with significant improvements. The source code is availabel at https://github.com/PaddlePaddle/PaddleSeg.