 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learning of Deceptive Policies under Intermittent Observation
Sep 19, 2025In supervisory control settings, autonomous systems are not monitored continuously. Instead, monitoring often occurs at sporadic intervals within known bounds. We study the problem of deception, where an agent pursues a private objective while remaining plausibly compliant with a supervisor's reference policy when observations occur. Motivated by the behavior of real, human supervisors, we situate the problem within Theory of Mind: the representation of what an observer believes and expects to see. We show that Theory of Mind can be repurposed to steer online reinforcement learning (RL) toward such deceptive behavior. We model the supervisor's expectations and distill from them a single, calibrated scalar -- the expected evidence of deviation if an observation were to happen now. This scalar combines how unlike the reference and current action distributions appear, with the agent's belief that an observation is imminent. Injected as a state-dependent weight into a KL-regularized policy improvement step within an online RL loop, this scalar informs a closed-form update that smoothly trades off self-interest and compliance, thus sidestepping hand-crafted or heuristic policies. In real-world, real-time hardware experiments on marine (ASV) and aerial (UAV) navigation, our ToM-guided RL runs online, achieves high return and success with observed-trace evidence calibrated to the supervisor's expectations.
FlowDrive: Energy Flow Field for End-to-End Autonomous Driving
Sep 17, 2025Recent advances in end-to-end autonomous driving leverage multi-view images to construct BEV representations for motion planning. In motion planning, autonomous vehicles need considering both hard constraints imposed by geometrically occupied obstacles (e.g., vehicles, pedestrians) and soft, rule-based semantics with no explicit geometry (e.g., lane boundaries, traffic priors). However, existing end-to-end frameworks typically rely on BEV features learned in an implicit manner, lacking explicit modeling of risk and guidance priors for safe and interpretable planning. To address this, we propose FlowDrive, a novel framework that introduces physically interpretable energy-based flow fields-including risk potential and lane attraction fields-to encode semantic priors and safety cues into the BEV space. These flow-aware features enable adaptive refinement of anchor trajectories and serve as interpretable guidance for trajectory generation. Moreover, FlowDrive decouples motion intent prediction from trajectory denoising via a conditional diffusion planner with feature-level gating, alleviating task interference and enhancing multimodal diversity. Experiments on the NAVSIM v2 benchmark demonstrate that FlowDrive achieves state-of-the-art performance with an EPDMS of 86.3, surpassing prior baselines in both safety and planning quality. The project is available at https://astrixdrive.github.io/FlowDrive.github.io/.
LatticeWorld: A Multimodal Large Language Model-Empowered Framework for Interactive Complex World Generation
Sep 05, 2025



Recent research has been increasingly focusing on developing 3D world models that simulate complex real-world scenarios. World models have found broad applications across various domains, including embodied AI, autonomous driving, entertainment, etc. A more realistic simulation with accurate physics will effectively narrow the sim-to-real gap and allow us to gather rich information about the real world conveniently. While traditional manual modeling has enabled the creation of virtual 3D scenes, modern approaches have leveraged advanced machine learning algorithms for 3D world generation, with most recent advances focusing on generative methods that can create virtual worlds based on user instructions. This work explores such a research direction by proposing LatticeWorld, a simple yet effective 3D world generation framework that streamlines the industrial production pipeline of 3D environments. LatticeWorld leverages lightweight LLMs (LLaMA-2-7B) alongside the industry-grade rendering engine (e.g., Unreal Engine 5) to generate a dynamic environment. Our proposed framework accepts textual descriptions and visual instructions as multimodal inputs and creates large-scale 3D interactive worlds with dynamic agents, featuring competitive multi-agent interaction, high-fidelity physics simulation, and real-time rendering. We conduct comprehensive experiments to evaluate LatticeWorld, showing that it achieves superior accuracy in scene layout generation and visual fidelity. Moreover, LatticeWorld achieves over a $90\times$ increase in industrial production efficiency while maintaining high creative quality compared with traditional manual production methods. Our demo video is available at https://youtu.be/8VWZXpERR18
Pinching-Antenna Systems (PASS): A Tutorial
Aug 11, 2025Pinching antenna systems (PASS) present a breakthrough among the flexible-antenna technologies, and distinguish themselves by facilitating large-scale antenna reconfiguration, line-of-sight creation, scalable implementation, and near-field benefits, thus bringing wireless communications from the last mile to the last meter. A comprehensive tutorial is presented in this paper. First, the fundamentals of PASS are discussed, including PASS signal models, hardware models, power radiation models, and pinching antenna activation methods. Building upon this, the information-theoretic capacity limits achieved by PASS are characterized, and several typical performance metrics of PASS-based communications are analyzed to demonstrate its superiority over conventional antenna technologies. Next, the pinching beamforming design is investigated. The corresponding power scaling law is first characterized. For the joint transmit and pinching design in the general multiple-waveguide case, 1) a pair of transmission strategies is proposed for PASS-based single-user communications to validate the superiority of PASS, namely sub-connected and fully connected structures; and 2) three practical protocols are proposed for facilitating PASS-based multi-user communications, namely waveguide switching, waveguide division, and waveguide multiplexing. A possible implementation of PASS in wideband communications is further highlighted. Moreover, the channel state information acquisition in PASS is elaborated with a pair of promising solutions. To overcome the high complexity and suboptimality inherent in conventional convex-optimization-based approaches, machine-learning-based methods for operating PASS are also explored, focusing on selected deep neural network architectures and training algorithms. Finally, several promising applications of PASS in next-generation wireless networks are highlighted.
CoAR: Concept Injection into Autoregressive Models for Personalized Text-to-Image Generation
Aug 10, 2025



The unified autoregressive (AR) model excels at multimodal understanding and generation, but its potential for customized image generation remains underexplored. Existing customized generation methods rely on full fine-tuning or adapters, making them costly and prone to overfitting or catastrophic forgetting. In this paper, we propose \textbf{CoAR}, a novel framework for injecting subject concepts into the unified AR models while keeping all pre-trained parameters completely frozen. CoAR learns effective, specific subject representations with only a minimal number of parameters using a Layerwise Multimodal Context Learning strategy. To address overfitting and language drift, we further introduce regularization that preserves the pre-trained distribution and anchors context tokens to improve subject fidelity and re-contextualization. Additionally, CoAR supports training-free subject customization in a user-provided style. Experiments demonstrate that CoAR achieves superior performance on both subject-driven personalization and style personalization, while delivering significant gains in computational and memory efficiency. Notably, CoAR tunes less than \textbf{0.05\%} of the parameters while achieving competitive performance compared to recent Proxy-Tuning. Code: https://github.com/KZF-kzf/CoAR
Genome-Anchored Foundation Model Embeddings Improve Molecular Prediction from Histology Images
Jun 24, 2025

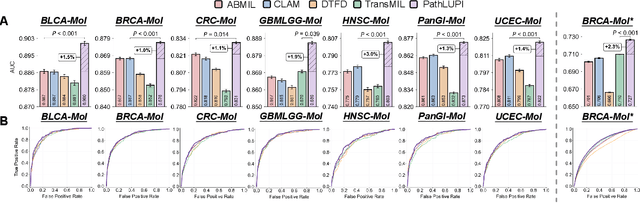

Precision oncology requires accurate molecular insights, yet obtaining these directly from genomics is costly and time-consuming for broad clinical use. Predicting complex molecular features and patient prognosis directly from routine whole-slide images (WSI) remains a major challenge for current deep learning methods. Here we introduce PathLUPI, which uses transcriptomic privileged information during training to extract genome-anchored histological embeddings, enabling effective molecular prediction using only WSIs at inference. Through extensive evaluation across 49 molecular oncology tasks using 11,257 cases among 20 cohorts, PathLUPI demonstrated superior performance compared to conventional methods trained solely on WSIs. Crucially, it achieves AUC $\geq$ 0.80 in 14 of the biomarker prediction and molecular subtyping tasks and C-index $\geq$ 0.70 in survival cohorts of 5 major cancer types. Moreover, PathLUPI embeddings reveal distinct cellular morphological signatures associated with specific genotypes and related biological pathways within WSIs. By effectively encoding molecular context to refine WSI representations, PathLUPI overcomes a key limitation of existing models and offers a novel strategy to bridge molecular insights with routine pathology workflows for wider clinical application.
Enhancing point cloud analysis via neighbor aggregation correction based on cross-stage structure correlation
Jun 18, 2025Point cloud analysis is the cornerstone of many downstream tasks, among which aggregating local structures is the basis for understanding point cloud data. While numerous works aggregate neighbor using three-dimensional relative coordinates, there are irrelevant point interference and feature hierarchy gap problems due to the limitation of local coordinates. Although some works address this limitation by refining spatial description though explicit modeling of cross-stage structure, these enhancement methods based on direct geometric structure encoding have problems of high computational overhead and noise sensitivity. To overcome these problems, we propose the Point Distribution Set Abstraction module (PDSA) that utilizes the correlation in the high-dimensional space to correct the feature distribution during aggregation, which improves the computational efficiency and robustness. PDSA distinguishes the point correlation based on a lightweight cross-stage structural descriptor, and enhances structural homogeneity by reducing the variance of the neighbor feature matrix and increasing classes separability though long-distance modeling. Additionally, we introducing a key point mechanism to optimize the computational overhead. The experimental result on semantic segmentation and classification tasks based on different baselines verify the generalization of the method we proposed, and achieve significant performance improvement with less parameter cost. The corresponding ablation and visualization results demonstrate the effectiveness and rationality of our method. The code and training weight is available at: https://github.com/AGENT9717/PointDistribution
DVP-MVS++: Synergize Depth-Normal-Edge and Harmonized Visibility Prior for Multi-View Stereo
Jun 16, 2025



Recently, patch deformation-based methods have demonstrated significant effectiveness in multi-view stereo due to their incorporation of deformable and expandable perception for reconstructing textureless areas. However, these methods generally focus on identifying reliable pixel correlations to mitigate matching ambiguity of patch deformation, while neglecting the deformation instability caused by edge-skipping and visibility occlusions, which may cause potential estimation deviations. To address these issues, we propose DVP-MVS++, an innovative approach that synergizes both depth-normal-edge aligned and harmonized cross-view priors for robust and visibility-aware patch deformation. Specifically, to avoid edge-skipping, we first apply DepthPro, Metric3Dv2 and Roberts operator to generate coarse depth maps, normal maps and edge maps, respectively. These maps are then aligned via an erosion-dilation strategy to produce fine-grained homogeneous boundaries for facilitating robust patch deformation. Moreover, we reformulate view selection weights as visibility maps, and then implement both an enhanced cross-view depth reprojection and an area-maximization strategy to help reliably restore visible areas and effectively balance deformed patch, thus acquiring harmonized cross-view priors for visibility-aware patch deformation. Additionally, we obtain geometry consistency by adopting both aggregated normals via view selection and projection depth differences via epipolar lines, and then employ SHIQ for highlight correction to enable geometry consistency with highlight-aware perception, thus improving reconstruction quality during propagation and refinement stage. Evaluation results on ETH3D, Tanks & Temples and Strecha datasets exhibit the state-of-the-art performance and robust generalization capability of our proposed method.
HAIF-GS: Hierarchical and Induced Flow-Guided Gaussian Splatting for Dynamic Scene
Jun 11, 2025Reconstructing dynamic 3D scenes from monocular videos remains a fundamental challenge in 3D vision. While 3D Gaussian Splatting (3DGS) achieves real-time rendering in static settings, extending it to dynamic scenes is challenging due to the difficulty of learning structured and temporally consistent motion representations. This challenge often manifests as three limitations in existing methods: redundant Gaussian updates, insufficient motion supervision, and weak modeling of complex non-rigid deformations. These issues collectively hinder coherent and efficient dynamic reconstruction. To address these limitations, we propose HAIF-GS, a unified framework that enables structured and consistent dynamic modeling through sparse anchor-driven deformation. It first identifies motion-relevant regions via an Anchor Filter to suppresses redundant updates in static areas. A self-supervised Induced Flow-Guided Deformation module induces anchor motion using multi-frame feature aggregation, eliminating the need for explicit flow labels. To further handle fine-grained deformations, a Hierarchical Anchor Propagation mechanism increases anchor resolution based on motion complexity and propagates multi-level transformations. Extensive experiments on synthetic and real-world benchmarks validate that HAIF-GS significantly outperforms prior dynamic 3DGS methods in rendering quality, temporal coherence, and reconstruction efficiency.
Heartcare Suite: Multi-dimensional Understanding of ECG with Raw Multi-lead Signal Modeling
Jun 06, 2025We present Heartcare Suite, a multimodal comprehensive framework for finegrained electrocardiogram (ECG) understanding. It comprises three key components: (i) Heartcare-220K, a high-quality, structured, and comprehensive multimodal ECG dataset covering essential tasks such as disease diagnosis, waveform morphology analysis, and rhythm interpretation. (ii) Heartcare-Bench, a systematic and multi-dimensional benchmark designed to evaluate diagnostic intelligence and guide the optimization of Medical Multimodal Large Language Models (Med-MLLMs) in ECG scenarios. and (iii) HeartcareGPT with a tailored tokenizer Bidirectional ECG Abstract Tokenization (Beat), which compresses raw multi-lead signals into semantically rich discrete tokens via duallevel vector quantization and query-guided bidirectional diffusion mechanism. Built upon Heartcare-220K, HeartcareGPT achieves strong generalization and SoTA performance across multiple clinically meaningful tasks. Extensive experiments demonstrate that Heartcare Suite is highly effective in advancing ECGspecific multimodal understanding and evaluation. Our project is available at https://github.com/Wznnnnn/Heartcare-Suite .