 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConSurv: Multimodal Continual Learning for Survival Analysis
Nov 13, 2025Survival prediction of cancers is crucial for clinical practice, as it informs mortality risks and influences treatment plans. However, a static model trained on a single dataset fails to adapt to the dynamically evolving clinical environment and continuous data streams, limiting its practical utility. While continual learning (CL) offers a solution to learn dynamically from new datasets, existing CL methods primarily focus on unimodal inputs and suffer from severe catastrophic forgetting in survival prediction. In real-world scenarios, multimodal inputs often provide comprehensive and complementary information, such as whole slide images and genomics; and neglecting inter-modal correlations negatively impacts the performance. To address the two challenges of catastrophic forgetting and complex inter-modal interactions between gigapixel whole slide images and genomics, we propose ConSurv, the first multimodal continual learning (MMCL) method for survival analysis. ConSurv incorporates two key components: Multi-staged Mixture of Experts (MS-MoE) and Feature Constrained Replay (FCR). MS-MoE captures both task-shared and task-specific knowledge at different learning stages of the network, including two modality encoders and the modality fusion component, learning inter-modal relationships. FCR further enhances learned knowledge and mitigates forgetting by restricting feature deviation of previous data at different levels, including encoder-level features of two modalities and the fusion-level representations. Additionally, we introduce a new benchmark integrating four datasets, Multimodal Survival Analysis Incremental Learning (MSAIL), for comprehensive evaluation in the CL setting. Extensive experiments demonstrate that ConSurv outperforms competing methods across multiple metrics.
Two-Dimensional Pinching-Antenna Systems: Modeling and Beamforming Design
Nov 12, 2025



Recently, the pinching-antenna system (PASS) has emerged as a promising architecture owing to its ability to reconfigure large-scale path loss and signal phase by activating radiation points along a dielectric waveguide. However, existing studies mainly focus on line-shaped PASS architectures, whose limited spatial flexibility constrains their applicability in multiuser and indoor scenarios. In this paper, we propose a novel two-dimensional (2D) pinching-antenna system (2D-PASS) that extends the conventional line-shaped structure into a continuous dielectric waveguide plane, thereby forming a reconfigurable radiating plane capable of dynamic beam adaptation across a 2D spatial domain. An optimization framework is developed to maximize the minimum received signal-to-noise ratio (SNR) among user equipments (UEs) by adaptively adjusting the spatial configuration of pinching antennas (PAs), serving as an analog beamforming mechanism for dynamic spatial control. For the continuous-position scenario, a particle swarm optimization (PSO)-based algorithm is proposed to efficiently explore the nonconvex search space, while a discrete variant is introduced to accommodate practical hardware constraints with limited PA placement resolution. Simulation results demonstrate that the proposed 2D-PASS substantially improves the minimum SNR compared with conventional line-shaped PASS and fixed-position antenna (FPA) benchmarks, while maintaining robustness under varying user distributions and distances.
Deep learning EPI-TIRF cross-modality enables background subtraction and axial super-resolution for widefield fluorescence microscopy
Nov 10, 2025


The resolving ability of wide-field fluorescence microscopy is fundamentally limited by out-of-focus background owing to its low axial resolution, particularly for densely labeled biological samples. To address this, we developed ET2dNet, a deep learning-based EPI-TIRF cross-modality network that achieves TIRF-comparable background subtraction and axial super-resolution from a single wide-field image without requiring hardware modifications. The model employs a physics-informed hybrid architecture, synergizing supervised learning with registered EPI-TIRF image pairs and self-supervised physical modeling via convolution with the point spread function. This framework ensures exceptional generalization across microscope objectives, enabling few-shot adaptation to new imaging setups. Rigorous validation on cellular and tissue samples confirms ET2dNet's superiority in background suppression and axial resolution enhancement, while maintaining compatibility with deconvolution techniques for lateral resolution improvement. Furthermore, by extending this paradigm through knowledge distillation, we developed ET3dNet, a dedicated three-dimensional reconstruction network that produces artifact-reduced volumetric results. ET3dNet effectively removes out-of-focus background signals even when the input image stack lacks the source of background. This framework makes axial super-resolution imaging more accessible by providing an easy-to-deploy algorithm that avoids additional hardware costs and complexity, showing great potential for live cell studies and clinical histopathology.
Learning from Online Videos at Inference Time for Computer-Use Agents
Nov 06, 2025



Computer-use agents can operate computers and automate laborious tasks, but despite recent rapid progress, they still lag behind human users, especially when tasks require domain-specific procedural knowledge about particular applications, platforms, and multi-step workflows. Humans can bridge this gap by watching video tutorials: we search, skim, and selectively imitate short segments that match our current subgoal. In this paper, we study how to enable computer-use agents to learn from online videos at inference time effectively. We propose a framework that retrieves and filters tutorial videos, converts them into structured demonstration trajectories, and dynamically selects trajectories as in-context guidance during execution. Particularly, using a VLM, we infer UI actions, segment videos into short subsequences of actions, and assign each subsequence a textual objective. At inference time, a two-stage selection mechanism dynamically chooses a single trajectory to add in context at each step, focusing the agent on the most helpful local guidance for its next decision. Experiments on two widely used benchmarks show that our framework consistently outperforms strong base agents and variants that use only textual tutorials or transcripts. Analyses highlight the importance of trajectory segmentation and selection, action filtering, and visual information, suggesting that abundant online videos can be systematically distilled into actionable guidance that improves computer-use agents at inference time. Our code is available at https://github.com/UCSB-NLP-Chang/video_demo.
OmniEduBench: A Comprehensive Chinese Benchmark for Evaluating Large Language Models in Education
Oct 30, 2025With the rapid development of large language models (LLMs), various LLM-based works have been widely applied in educational fields. However, most existing LLMs and their benchmarks focus primarily on the knowledge dimension, largely neglecting the evaluation of cultivation capabilities that are essential for real-world educational scenarios. Additionally, current benchmarks are often limited to a single subject or question type, lacking sufficient diversity. This issue is particularly prominent within the Chinese context. To address this gap, we introduce OmniEduBench, a comprehensive Chinese educational benchmark. OmniEduBench consists of 24.602K high-quality question-answer pairs. The data is meticulously divided into two core dimensions: the knowledge dimension and the cultivation dimension, which contain 18.121K and 6.481K entries, respectively. Each dimension is further subdivided into 6 fine-grained categories, covering a total of 61 different subjects (41 in the knowledge and 20 in the cultivation). Furthermore, the dataset features a rich variety of question formats, including 11 common exam question types, providing a solid foundation for comprehensively evaluating LLMs' capabilities in education. Extensive experiments on 11 mainstream open-source and closed-source LLMs reveal a clear performance gap. In the knowledge dimension, only Gemini-2.5 Pro surpassed 60\% accuracy, while in the cultivation dimension, the best-performing model, QWQ, still trailed human intelligence by nearly 30\%. These results highlight the substantial room for improvement and underscore the challenges of applying LLMs in education.
Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Oct 24, 2025



This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
Exploring Image Representation with Decoupled Classical Visual Descriptors
Oct 16, 2025Exploring and understanding efficient image representations is a long-standing challenge in computer vision. While deep learning has achieved remarkable progress across image understanding tasks, its internal representations are often opaque, making it difficult to interpret how visual information is processed. In contrast, classical visual descriptors (e.g. edge, colour, and intensity distribution) have long been fundamental to image analysis and remain intuitively understandable to humans. Motivated by this gap, we ask a central question: Can modern learning benefit from these classical cues? In this paper, we answer it with VisualSplit, a framework that explicitly decomposes images into decoupled classical descriptors, treating each as an independent but complementary component of visual knowledge. Through a reconstruction-driven pre-training scheme, VisualSplit learns to capture the essence of each visual descriptor while preserving their interpretability. By explicitly decomposing visual attributes, our method inherently facilitates effective attribute control in various advanced visual tasks, including image generation and editing, extending beyond conventional classification and segmentation, suggesting the effectiveness of this new learning approach for visual understanding. Project page: https://chenyuanqu.com/VisualSplit/.
Revisit Modality Imbalance at the Decision Layer
Oct 16, 2025Multimodal learning integrates information from different modalities to enhance model performance, yet it often suffers from modality imbalance, where dominant modalities overshadow weaker ones during joint optimization. This paper reveals that such an imbalance not only occurs during representation learning but also manifests significantly at the decision layer. Experiments on audio-visual datasets (CREMAD and Kinetic-Sounds) show that even after extensive pretraining and balanced optimization, models still exhibit systematic bias toward certain modalities, such as audio. Further analysis demonstrates that this bias originates from intrinsic disparities in feature-space and decision-weight distributions rather than from optimization dynamics alone. We argue that aggregating uncalibrated modality outputs at the fusion stage leads to biased decision-layer weighting, hindering weaker modalities from contributing effectively. To address this, we propose that future multimodal systems should focus more on incorporate adaptive weight allocation mechanisms at the decision layer, enabling relative balanced according to the capabilities of each modality.
Evolutionary Profiles for Protein Fitness Prediction
Oct 08, 2025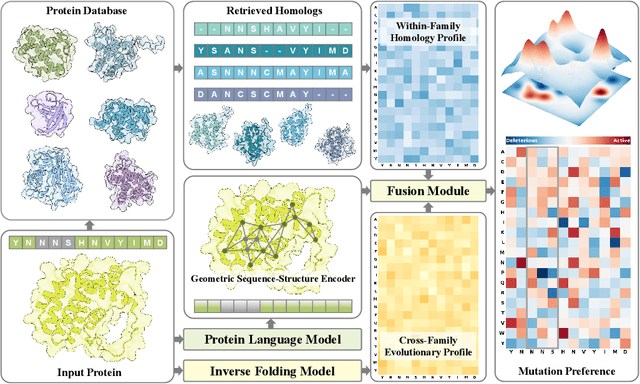
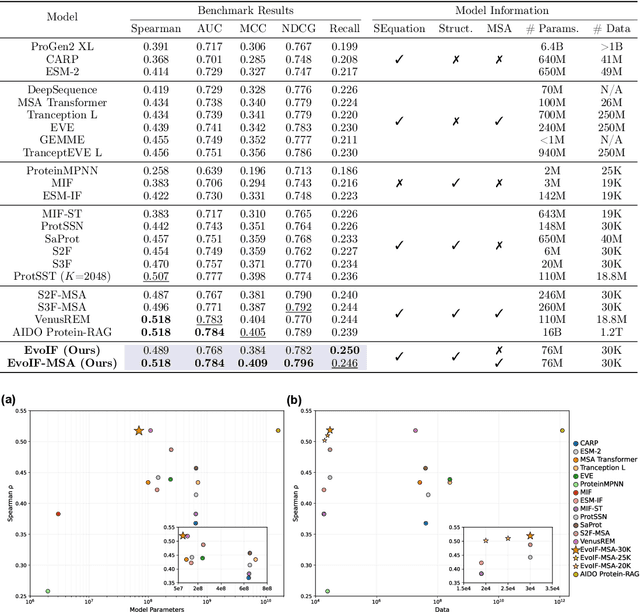
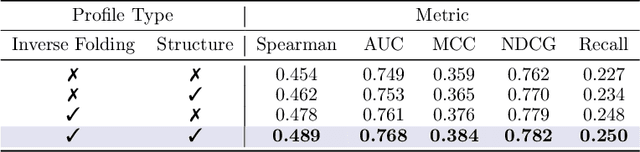
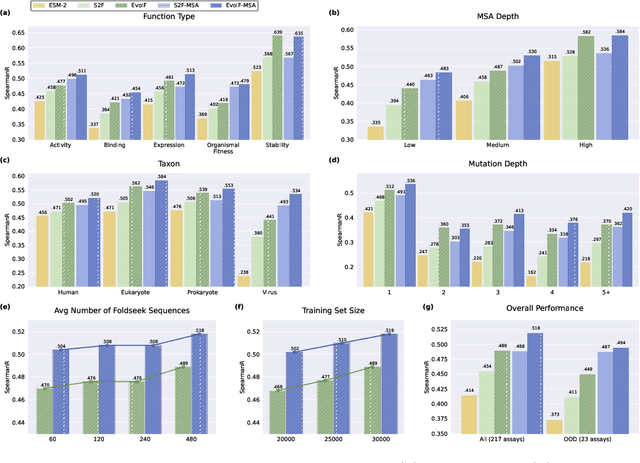
Predicting the fitness impact of mutations is central to protein engineering but constrained by limited assays relative to the size of sequence space. Protein language models (pLMs) trained with masked language modeling (MLM) exhibit strong zero-shot fitness prediction; we provide a unifying view by interpreting natural evolution as implicit reward maximization and MLM as inverse reinforcement learning (IRL), in which extant sequences act as expert demonstrations and pLM log-odds serve as fitness estimates. Building on this perspective, we introduce EvoIF, a lightweight model that integrates two complementary sources of evolutionary signal: (i) within-family profiles from retrieved homologs and (ii) cross-family structural-evolutionary constraints distilled from inverse folding logits. EvoIF fuses sequence-structure representations with these profiles via a compact transition block, yielding calibrated probabilities for log-odds scoring. On ProteinGym (217 mutational assays; >2.5M mutants), EvoIF and its MSA-enabled variant achieve state-of-the-art or competitive performance while using only 0.15% of the training data and fewer parameters than recent large models. Ablations confirm that within-family and cross-family profiles are complementary, improving robustness across function types, MSA depths, taxa, and mutation depths. The codes will be made publicly available at https://github.com/aim-uofa/EvoIF.
A Clinical-grade Universal Foundation Model for Intraoperative Pathology
Oct 06, 2025Intraoperative pathology is pivotal to precision surgery, yet its clinical impact is constrained by diagnostic complexity and the limited availability of high-quality frozen-section data. While computational pathology has made significant strides, the lack of large-scale, prospective validation has impeded its routine adoption in surgical workflows. Here, we introduce CRISP, a clinical-grade foundation model developed on over 100,000 frozen sections from eight medical centers, specifically designed to provide Clinical-grade Robust Intraoperative Support for Pathology (CRISP). CRISP was comprehensively evaluated on more than 15,000 intraoperative slides across nearly 100 retrospective diagnostic tasks, including benign-malignant discrimination, key intraoperative decision-making, and pan-cancer detection, etc. The model demonstrated robust generalization across diverse institutions, tumor types, and anatomical sites-including previously unseen sites and rare cancers. In a prospective cohort of over 2,000 patients, CRISP sustained high diagnostic accuracy under real-world conditions, directly informing surgical decisions in 92.6% of cases. Human-AI collaboration further reduced diagnostic workload by 35%, avoided 105 ancillary tests and enhanced detection of micrometastases with 87.5% accuracy. Together, these findings position CRISP as a clinical-grade paradigm for AI-driven intraoperative pathology, bridging computational advances with surgical precision and accelerating the translation of artificial intelligence into routine clinical practice.