 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAntenna Elements' Trajectory Optimization for Throughput Maximization in Continuous-Trajectory Fluid Antenna-Aided Wireless Communications
Mar 27, 2026Fluid antenna (FA) systems offer novel spatial degrees of freedom (DoFs) with the potential for significant performance gains. Compared to existing works focusing solely on optimizing FA positions at discrete time instants, we introduce the concept of continuous-trajectory fluid antenna (CTFA), which explicitly considers the antenna element's movement trajectory across continuous time intervals and incorporates the inherent kinematic constraints present in practical FA implementations. Accordingly, we formulate the total throughput maximization problem in CTFA-aided wireless communication systems, addressing the joint optimization of continuous antenna trajectories in conjunction with the transmit covariance matrices under kinematic constraints. To effectively solve this non-convex problem with highly coupled optimization variables, we develop an iterative algorithm based on block coordinate descent (BCD) and majorization-minimization (MM) principles with the aid of the weighted minimum mean square error (WMMSE) method. Finally, numerical results are presented to validate the efficacy of the proposed algorithms and to quantify the substantial total throughput advantages afforded by the conceived CTFA-aided system compared to conventional fixed-position antenna (FPA) benchmarks and alternative approaches employing simplified trajectories.
NL2CA: Auto-formalizing Cognitive Decision-Making from Natural Language Using an Unsupervised CriticNL2LTL Framework
Dec 20, 2025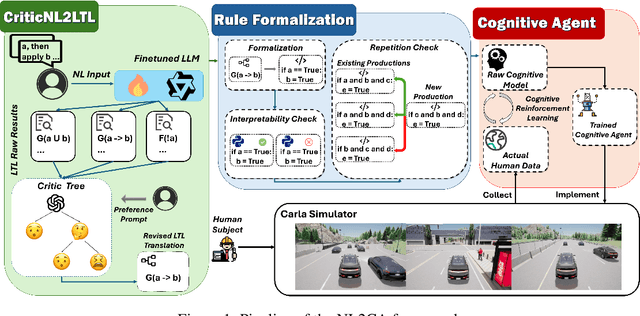
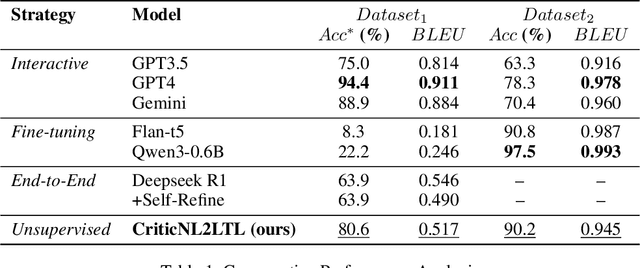
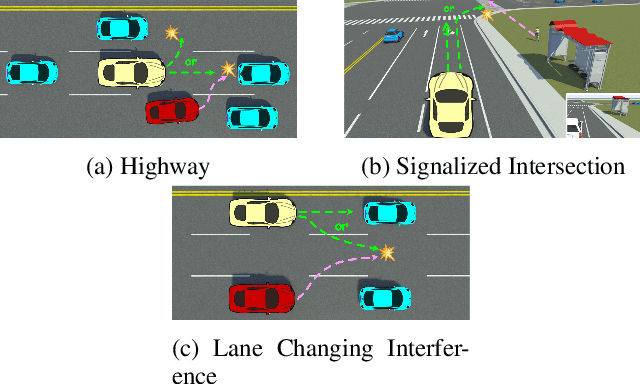

Cognitive computing models offer a formal and interpretable way to characterize human's deliberation and decision-making, yet their development remains labor-intensive. In this paper, we propose NL2CA, a novel method for auto-formalizing cognitive decision-making rules from natural language descriptions of human experience. Different from most related work that exploits either pure manual or human guided interactive modeling, our method is fully automated without any human intervention. The approach first translates text into Linear Temporal Logic (LTL) using a fine-tuned large language model (LLM), then refines the logic via an unsupervised Critic Tree, and finally transforms the output into executable production rules compatible with symbolic cognitive frameworks. Based on the resulted rules, a cognitive agent is further constructed and optimized through cognitive reinforcement learning according to the real-world behavioral data. Our method is validated in two domains: (1) NL-to-LTL translation, where our CriticNL2LTL module achieves consistent performance across both expert and large-scale benchmarks without human-in-the-loop feed-backs, and (2) cognitive driving simulation, where agents automatically constructed from human interviews have successfully learned the diverse decision patterns of about 70 trials in different critical scenarios. Experimental results demonstrate that NL2CA enables scalable, interpretable, and human-aligned cognitive modeling from unstructured textual data, offering a novel paradigm to automatically design symbolic cognitive agents.
Two-Dimensional Pinching-Antenna Systems: Modeling and Beamforming Design
Nov 12, 2025



Recently, the pinching-antenna system (PASS) has emerged as a promising architecture owing to its ability to reconfigure large-scale path loss and signal phase by activating radiation points along a dielectric waveguide. However, existing studies mainly focus on line-shaped PASS architectures, whose limited spatial flexibility constrains their applicability in multiuser and indoor scenarios. In this paper, we propose a novel two-dimensional (2D) pinching-antenna system (2D-PASS) that extends the conventional line-shaped structure into a continuous dielectric waveguide plane, thereby forming a reconfigurable radiating plane capable of dynamic beam adaptation across a 2D spatial domain. An optimization framework is developed to maximize the minimum received signal-to-noise ratio (SNR) among user equipments (UEs) by adaptively adjusting the spatial configuration of pinching antennas (PAs), serving as an analog beamforming mechanism for dynamic spatial control. For the continuous-position scenario, a particle swarm optimization (PSO)-based algorithm is proposed to efficiently explore the nonconvex search space, while a discrete variant is introduced to accommodate practical hardware constraints with limited PA placement resolution. Simulation results demonstrate that the proposed 2D-PASS substantially improves the minimum SNR compared with conventional line-shaped PASS and fixed-position antenna (FPA) benchmarks, while maintaining robustness under varying user distributions and distances.
Pinching-Antenna-Assisted Index Modulation: Channel Modeling, Transceiver Design, and Performance Analysis
Jul 03, 2025In this paper, a novel pinching-antenna assisted index modulation (PA-IM) scheme is proposed for improving the spectral efficiency without increasing the hardware complexity, where the information bits are conveyed not only by the conventional M-ary quadrature amplitude modulation (QAM) symbols but also by the indices of pinching antenna (PA) position patterns. To realize the full potential of this scheme, this paper focuses on the comprehensive transceiver design, addressing key challenges in signal detection at the receiver and performance optimization at thetransmitter. First, a comprehensive channel model is formulated for this architecture, which sophisticatedly integrates the deterministic in-waveguide propagation effects with the stochastic nature of wireless channels, including both largescale path loss and small-scale fading. Next, to overcome the prohibitive complexity of optimal maximum likelihood (ML) detection, a low-complexity box-optimized sphere decoding (BOSD) algorithm is designed, which adaptively prunes the search space whilst preserving optimal ML performance. Furthermore, an analytical upper bound on the bit error rate (BER) is derived and validated by the simulations. Moreover, a new transmit precoding method is designed using manifold optimization, which minimizes the BER by jointly optimizing the complex-valued precoding coefficients across the waveguides for the sake of maximizing the minimum Euclidean distance of all received signal points. Finally, the simulation results demonstrate that the proposed PA-IM scheme attains a significant performance gain over its conventional counterparts and that the overall BER of the pinching-antenna system is substantially improved by the proposed precoding design.
A foundation model for human-AI collaboration in medical literature mining
Jan 27, 2025



Systematic literature review is essential for evidence-based medicine, requiring comprehensive analysis of clinical trial publications. However, the application of artificial intelligence (AI) models for medical literature mining has been limited by insufficient training and evaluation across broad therapeutic areas and diverse tasks. Here, we present LEADS, an AI foundation model for study search, screening, and data extraction from medical literature. The model is trained on 633,759 instruction data points in LEADSInstruct, curated from 21,335 systematic reviews, 453,625 clinical trial publications, and 27,015 clinical trial registries. We showed that LEADS demonstrates consistent improvements over four cutting-edge generic large language models (LLMs) on six tasks. Furthermore, LEADS enhances expert workflows by providing supportive references following expert requests, streamlining processes while maintaining high-quality results. A study with 16 clinicians and medical researchers from 14 different institutions revealed that experts collaborating with LEADS achieved a recall of 0.81 compared to 0.77 experts working alone in study selection, with a time savings of 22.6%. In data extraction tasks, experts using LEADS achieved an accuracy of 0.85 versus 0.80 without using LEADS, alongside a 26.9% time savings. These findings highlight the potential of specialized medical literature foundation models to outperform generic models, delivering significant quality and efficiency benefits when integrated into expert workflows for medical literature mining.
Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine
Jan 24, 2024Recent studies indicate that Generative Pre-trained Transformer 4 with Vision (GPT-4V) outperforms human physicians in medical challenge tasks. However, these evaluations primarily focused on the accuracy of multi-choice questions alone. Our study extends the current scope by conducting a comprehensive analysis of GPT-4V's rationales of image comprehension, recall of medical knowledge, and step-by-step multimodal reasoning when solving New England Journal of Medicine (NEJM) Image Challenges - an imaging quiz designed to test the knowledge and diagnostic capabilities of medical professionals. Evaluation results confirmed that GPT-4V outperforms human physicians regarding multi-choice accuracy (88.0% vs. 77.0%, p=0.034). GPT-4V also performs well in cases where physicians incorrectly answer, with over 80% accuracy. However, we discovered that GPT-4V frequently presents flawed rationales in cases where it makes the correct final choices (27.3%), most prominent in image comprehension (21.6%). Regardless of GPT-4V's high accuracy in multi-choice questions, our findings emphasize the necessity for further in-depth evaluations of its rationales before integrating such models into clinical workflows.
Artificial Intelligence Security Competition (AISC)
Dec 07, 2022



The security of artificial intelligence (AI) is an important research area towards safe, reliable, and trustworthy AI systems. To accelerate the research on AI security, the Artificial Intelligence Security Competition (AISC) was organized by the Zhongguancun Laboratory, China Industrial Control Systems Cyber Emergency Response Team, Institute for Artificial Intelligence, Tsinghua University, and RealAI as part of the Zhongguancun International Frontier Technology Innovation Competition (https://www.zgc-aisc.com/en). The competition consists of three tracks, including Deepfake Security Competition, Autonomous Driving Security Competition, and Face Recognition Security Competition. This report will introduce the competition rules of these three tracks and the solutions of top-ranking teams in each track.