 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
Oct 24, 2025



This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.
Multi-Label Stereo Matching for Transparent Scene Depth Estimation
May 20, 2025In this paper, we present a multi-label stereo matching method to simultaneously estimate the depth of the transparent objects and the occluded background in transparent scenes.Unlike previous methods that assume a unimodal distribution along the disparity dimension and formulate the matching as a single-label regression problem, we propose a multi-label regression formulation to estimate multiple depth values at the same pixel in transparent scenes. To resolve the multi-label regression problem, we introduce a pixel-wise multivariate Gaussian representation, where the mean vector encodes multiple depth values at the same pixel, and the covariance matrix determines whether a multi-label representation is necessary for a given pixel. The representation is iteratively predicted within a GRU framework. In each iteration, we first predict the update step for the mean parameters and then use both the update step and the updated mean parameters to estimate the covariance matrix. We also synthesize a dataset containing 10 scenes and 89 objects to validate the performance of transparent scene depth estimation. The experiments show that our method greatly improves the performance on transparent surfaces while preserving the background information for scene reconstruction. Code is available at https://github.com/BFZD233/TranScene.
Diving into the Fusion of Monocular Priors for Generalized Stereo Matching
May 20, 2025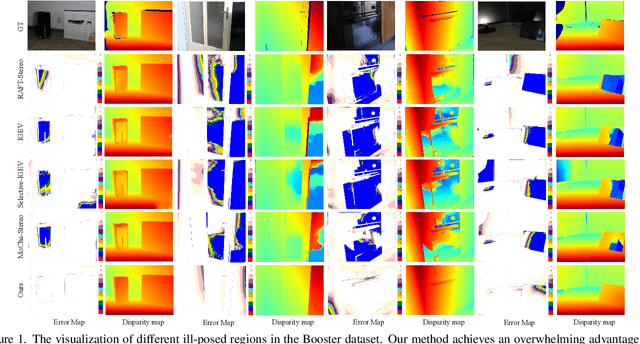
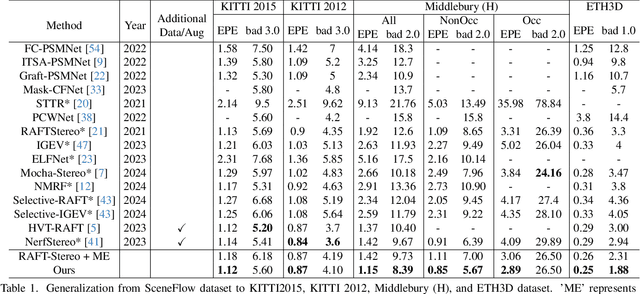
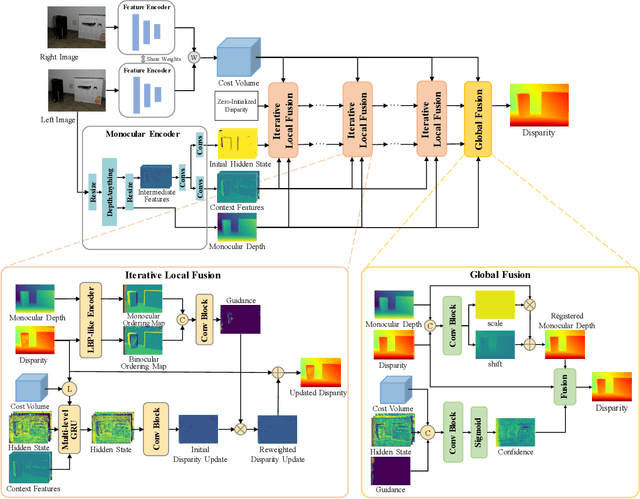
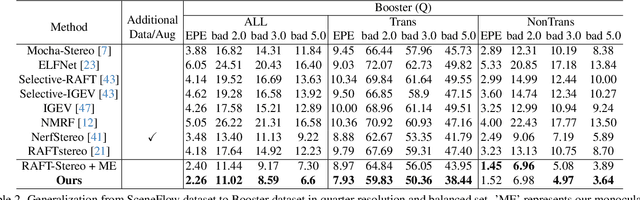
The matching formulation makes it naturally hard for the stereo matching to handle ill-posed regions like occlusions and non-Lambertian surfaces. Fusing monocular priors has been proven helpful for ill-posed matching, but the biased monocular prior learned from small stereo datasets constrains the generalization. Recently, stereo matching has progressed by leveraging the unbiased monocular prior from the vision foundation model (VFM) to improve the generalization in ill-posed regions. We dive into the fusion process and observe three main problems limiting the fusion of the VFM monocular prior. The first problem is the misalignment between affine-invariant relative monocular depth and absolute depth of disparity. Besides, when we use the monocular feature in an iterative update structure, the over-confidence in the disparity update leads to local optima results. A direct fusion of a monocular depth map could alleviate the local optima problem, but noisy disparity results computed at the first several iterations will misguide the fusion. In this paper, we propose a binary local ordering map to guide the fusion, which converts the depth map into a binary relative format, unifying the relative and absolute depth representation. The computed local ordering map is also used to re-weight the initial disparity update, resolving the local optima and noisy problem. In addition, we formulate the final direct fusion of monocular depth to the disparity as a registration problem, where a pixel-wise linear regression module can globally and adaptively align them. Our method fully exploits the monocular prior to support stereo matching results effectively and efficiently. We significantly improve the performance from the experiments when generalizing from SceneFlow to Middlebury and Booster datasets while barely reducing the efficiency.
Temporally Consistent Stereo Matching
Jul 16, 2024Stereo matching provides depth estimation from binocular images for downstream applications. These applications mostly take video streams as input and require temporally consistent depth maps. However, existing methods mainly focus on the estimation at the single-frame level. This commonly leads to temporally inconsistent results, especially in ill-posed regions. In this paper, we aim to leverage temporal information to improve the temporal consistency, accuracy, and efficiency of stereo matching. To achieve this, we formulate video stereo matching as a process of temporal disparity completion followed by continuous iterative refinements. Specifically, we first project the disparity of the previous timestamp to the current viewpoint, obtaining a semi-dense disparity map. Then, we complete this map through a disparity completion module to obtain a well-initialized disparity map. The state features from the current completion module and from the past refinement are fused together, providing a temporally coherent state for subsequent refinement. Based on this coherent state, we introduce a dual-space refinement module to iteratively refine the initialized result in both disparity and disparity gradient spaces, improving estimations in ill-posed regions. Extensive experiments demonstrate that our method effectively alleviates temporal inconsistency while enhancing both accuracy and efficiency.
A Decomposition Model for Stereo Matching
Apr 15, 2021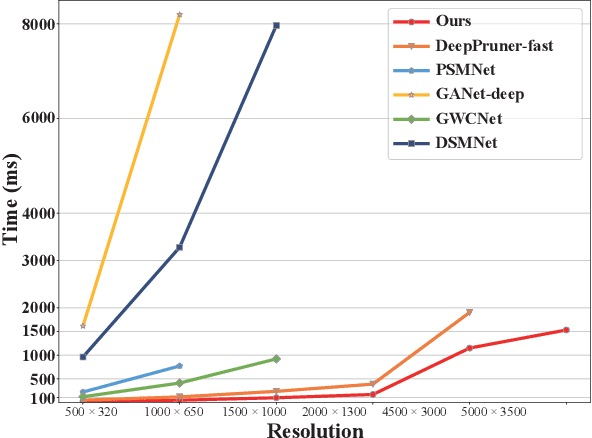
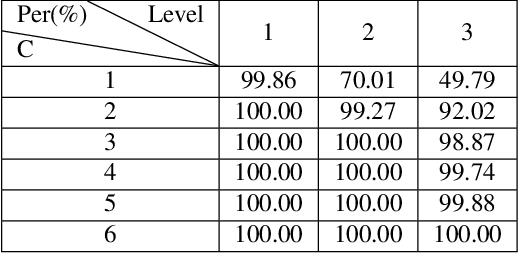
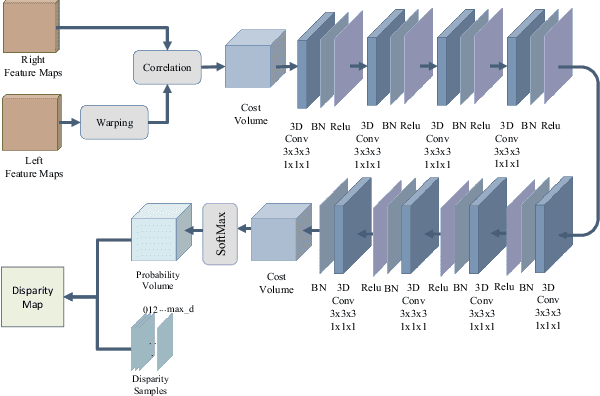

In this paper, we present a decomposition model for stereo matching to solve the problem of excessive growth in computational cost (time and memory cost) as the resolution increases. In order to reduce the huge cost of stereo matching at the original resolution, our model only runs dense matching at a very low resolution and uses sparse matching at different higher resolutions to recover the disparity of lost details scale-by-scale. After the decomposition of stereo matching, our model iteratively fuses the sparse and dense disparity maps from adjacent scales with an occlusion-aware mask. A refinement network is also applied to improving the fusion result. Compared with high-performance methods like PSMNet and GANet, our method achieves $10-100\times$ speed increase while obtaining comparable disparity estimation results.
Content-Aware Inter-Scale Cost Aggregation for Stereo Matching
Jun 05, 2020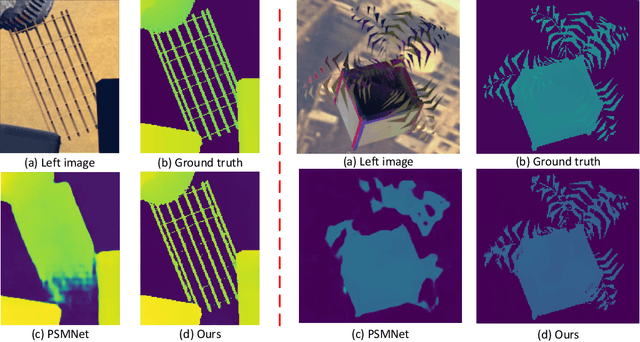

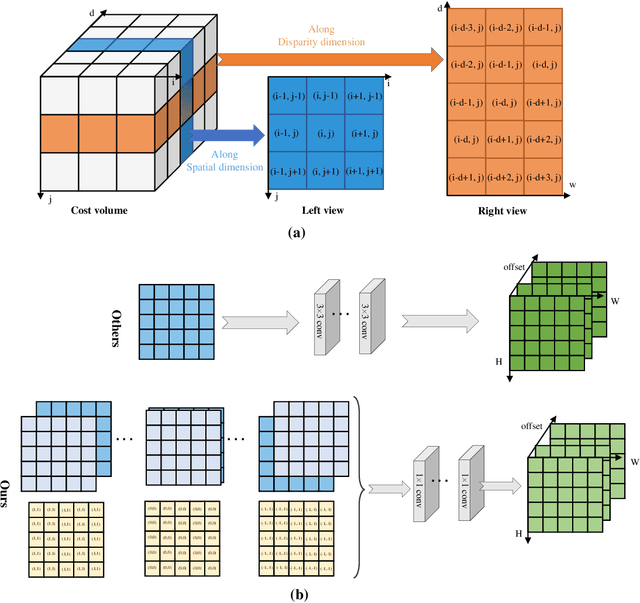

Cost aggregation is a key component of stereo matching for high-quality depth estimation. Most methods use multi-scale processing to downsample cost volume for proper context information, but will cause loss of details when upsampling. In this paper, we present a content-aware inter-scale cost aggregation method that adaptively aggregates and upsamples the cost volume from coarse-scale to fine-scale by learning dynamic filter weights according to the content of the left and right views on the two scales. Our method achieves reliable detail recovery when upsampling through the aggregation of information across different scales. Furthermore, a novel decomposition strategy is proposed to efficiently construct the 3D filter weights and aggregate the 3D cost volume, which greatly reduces the computation cost. We first learn the 2D similarities via the feature maps on the two scales, and then build the 3D filter weights based on the 2D similarities from the left and right views. After that, we split the aggregation in a full 3D spatial-disparity space into the aggregation in 1D disparity space and 2D spatial space. Experiment results on Scene Flow dataset, KITTI2015 and Middlebury demonstrate the effectiveness of our method.