 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep learning EPI-TIRF cross-modality enables background subtraction and axial super-resolution for widefield fluorescence microscopy
Nov 10, 2025


The resolving ability of wide-field fluorescence microscopy is fundamentally limited by out-of-focus background owing to its low axial resolution, particularly for densely labeled biological samples. To address this, we developed ET2dNet, a deep learning-based EPI-TIRF cross-modality network that achieves TIRF-comparable background subtraction and axial super-resolution from a single wide-field image without requiring hardware modifications. The model employs a physics-informed hybrid architecture, synergizing supervised learning with registered EPI-TIRF image pairs and self-supervised physical modeling via convolution with the point spread function. This framework ensures exceptional generalization across microscope objectives, enabling few-shot adaptation to new imaging setups. Rigorous validation on cellular and tissue samples confirms ET2dNet's superiority in background suppression and axial resolution enhancement, while maintaining compatibility with deconvolution techniques for lateral resolution improvement. Furthermore, by extending this paradigm through knowledge distillation, we developed ET3dNet, a dedicated three-dimensional reconstruction network that produces artifact-reduced volumetric results. ET3dNet effectively removes out-of-focus background signals even when the input image stack lacks the source of background. This framework makes axial super-resolution imaging more accessible by providing an easy-to-deploy algorithm that avoids additional hardware costs and complexity, showing great potential for live cell studies and clinical histopathology.
Fake It till You Make It: Curricular Dynamic Forgery Augmentations towards General Deepfake Detection
Sep 22, 2024Previous studies in deepfake detection have shown promising results when testing face forgeries from the same dataset as the training. However, the problem remains challenging when one tries to generalize the detector to forgeries from unseen datasets and created by unseen methods. In this work, we present a novel general deepfake detection method, called \textbf{C}urricular \textbf{D}ynamic \textbf{F}orgery \textbf{A}ugmentation (CDFA), which jointly trains a deepfake detector with a forgery augmentation policy network. Unlike the previous works, we propose to progressively apply forgery augmentations following a monotonic curriculum during the training. We further propose a dynamic forgery searching strategy to select one suitable forgery augmentation operation for each image varying between training stages, producing a forgery augmentation policy optimized for better generalization. In addition, we propose a novel forgery augmentation named self-shifted blending image to simply imitate the temporal inconsistency of deepfake generation. Comprehensive experiments show that CDFA can significantly improve both cross-datasets and cross-manipulations performances of various naive deepfake detectors in a plug-and-play way, and make them attain superior performances over the existing methods in several benchmark datasets.
STD-NET: Search of Image Steganalytic Deep-learning Architecture via Hierarchical Tensor Decomposition
Jun 12, 2022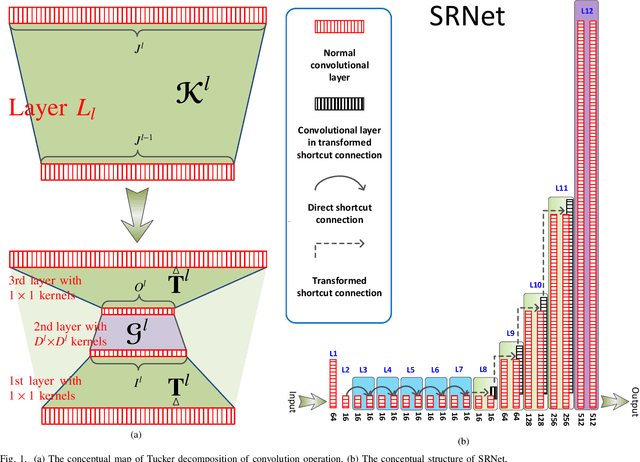
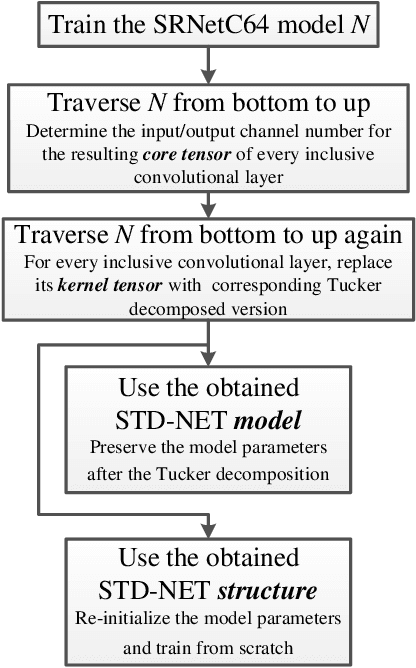
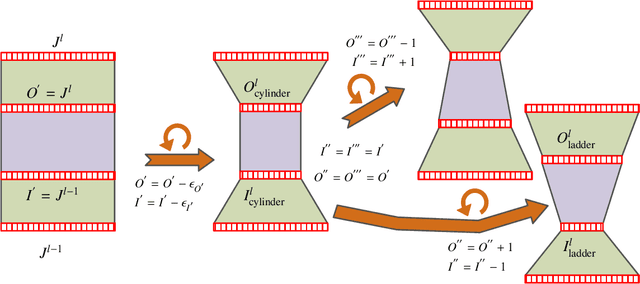
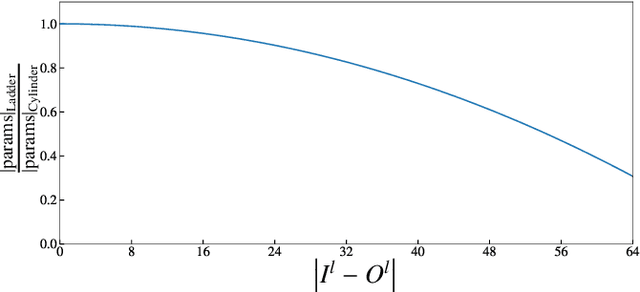
Recent studies shows that the majority of existing deep steganalysis models have a large amount of redundancy, which leads to a huge waste of storage and computing resources. The existing model compression method cannot flexibly compress the convolutional layer in residual shortcut block so that a satisfactory shrinking rate cannot be obtained. In this paper, we propose STD-NET, an unsupervised deep-learning architecture search approach via hierarchical tensor decomposition for image steganalysis. Our proposed strategy will not be restricted by various residual connections, since this strategy does not change the number of input and output channels of the convolution block. We propose a normalized distortion threshold to evaluate the sensitivity of each involved convolutional layer of the base model to guide STD-NET to compress target network in an efficient and unsupervised approach, and obtain two network structures of different shapes with low computation cost and similar performance compared with the original one. Extensive experiments have confirmed that, on one hand, our model can achieve comparable or even better detection performance in various steganalytic scenarios due to the great adaptivity of the obtained network architecture. On the other hand, the experimental results also demonstrate that our proposed strategy is more efficient and can remove more redundancy compared with previous steganalytic network compression methods.