 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning under Distributed Concept Drift
Jun 01, 2022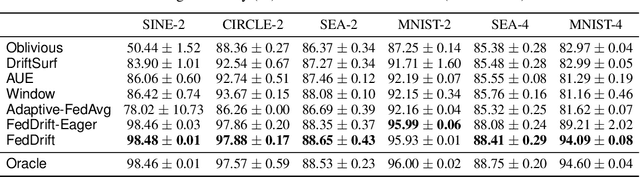


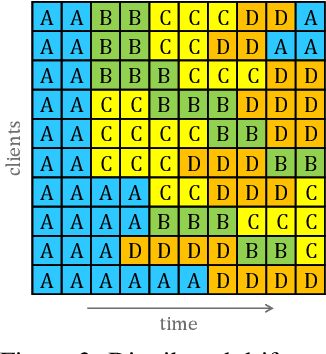
Federated Learning (FL) under distributed concept drift is a largely unexplored area. Although concept drift is itself a well-studied phenomenon, it poses particular challenges for FL, because drifts arise staggered in time and space (across clients). Our work is the first to explicitly study data heterogeneity in both dimensions. We first demonstrate that prior solutions to drift adaptation, with their single global model, are ill-suited to staggered drifts, necessitating multi-model solutions. We identify the problem of drift adaptation as a time-varying clustering problem, and we propose two new clustering algorithms for reacting to drifts based on local drift detection and hierarchical clustering. Empirical evaluation shows that our solutions achieve significantly higher accuracy than existing baselines, and are comparable to an idealized algorithm with oracle knowledge of the ground-truth clustering of clients to concepts at each time step.
To Federate or Not To Federate: Incentivizing Client Participation in Federated Learning
May 30, 2022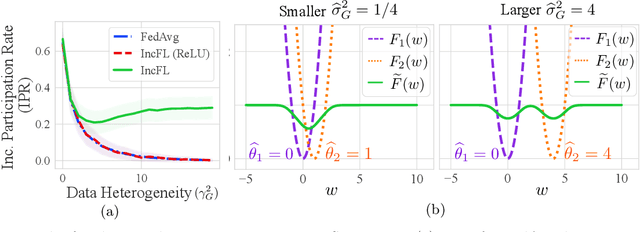
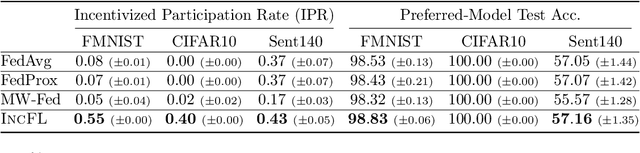
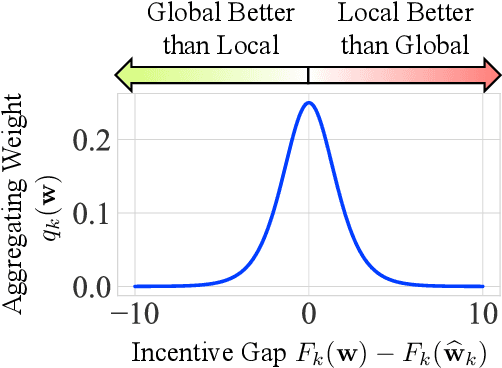
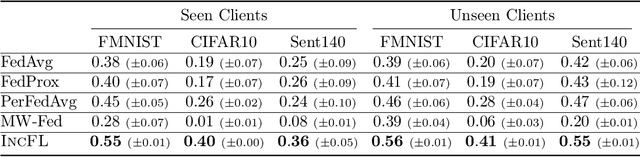
Federated learning (FL) facilitates collaboration between a group of clients who seek to train a common machine learning model without directly sharing their local data. Although there is an abundance of research on improving the speed, efficiency, and accuracy of federated training, most works implicitly assume that all clients are willing to participate in the FL framework. Due to data heterogeneity, however, the global model may not work well for some clients, and they may instead choose to use their own local model. Such disincentivization of clients can be problematic from the server's perspective because having more participating clients yields a better global model, and offers better privacy guarantees to the participating clients. In this paper, we propose an algorithm called IncFL that explicitly maximizes the fraction of clients who are incentivized to use the global model by dynamically adjusting the aggregation weights assigned to their updates. Our experiments show that IncFL increases the number of incentivized clients by 30-55% compared to standard federated training algorithms, and can also improve the generalization performance of the global model on unseen clients.
Heterogeneous Ensemble Knowledge Transfer for Training Large Models in Federated Learning
Apr 27, 2022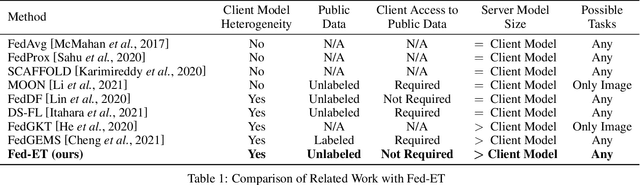
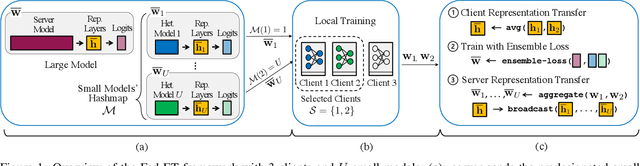
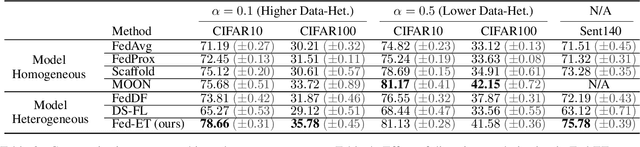
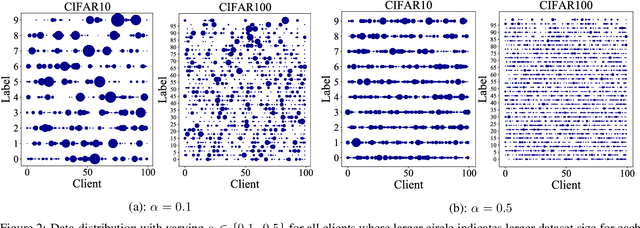
Federated learning (FL) enables edge-devices to collaboratively learn a model without disclosing their private data to a central aggregating server. Most existing FL algorithms require models of identical architecture to be deployed across the clients and server, making it infeasible to train large models due to clients' limited system resources. In this work, we propose a novel ensemble knowledge transfer method named Fed-ET in which small models (different in architecture) are trained on clients, and used to train a larger model at the server. Unlike in conventional ensemble learning, in FL the ensemble can be trained on clients' highly heterogeneous data. Cognizant of this property, Fed-ET uses a weighted consensus distillation scheme with diversity regularization that efficiently extracts reliable consensus from the ensemble while improving generalization by exploiting the diversity within the ensemble. We show the generalization bound for the ensemble of weighted models trained on heterogeneous datasets that supports the intuition of Fed-ET. Our experiments on image and language tasks show that Fed-ET significantly outperforms other state-of-the-art FL algorithms with fewer communicated parameters, and is also robust against high data-heterogeneity.
Federated Minimax Optimization: Improved Convergence Analyses and Algorithms
Mar 09, 2022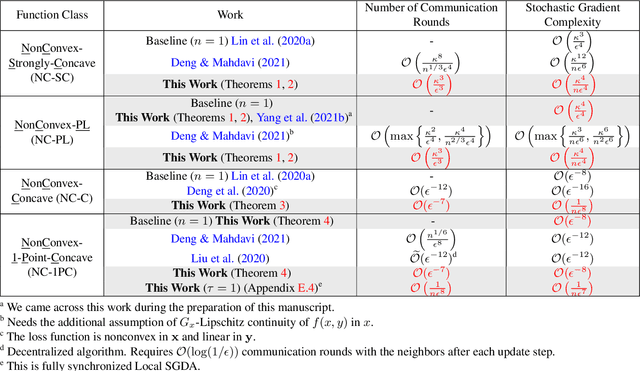
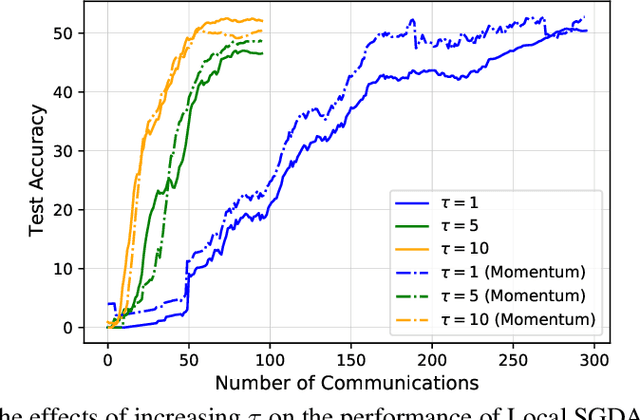
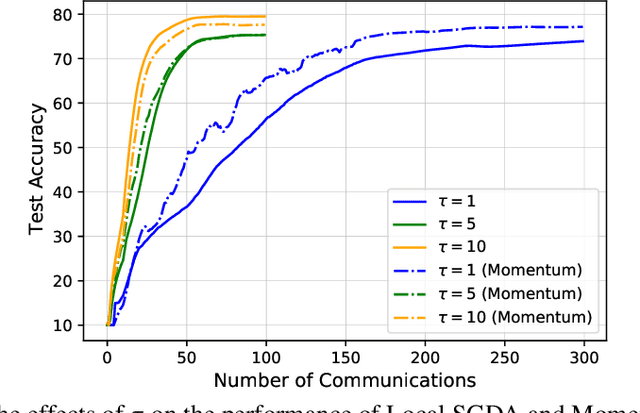

In this paper, we consider nonconvex minimax optimization, which is gaining prominence in many modern machine learning applications such as GANs. Large-scale edge-based collection of training data in these applications calls for communication-efficient distributed optimization algorithms, such as those used in federated learning, to process the data. In this paper, we analyze Local stochastic gradient descent ascent (SGDA), the local-update version of the SGDA algorithm. SGDA is the core algorithm used in minimax optimization, but it is not well-understood in a distributed setting. We prove that Local SGDA has \textit{order-optimal} sample complexity for several classes of nonconvex-concave and nonconvex-nonconcave minimax problems, and also enjoys \textit{linear speedup} with respect to the number of clients. We provide a novel and tighter analysis, which improves the convergence and communication guarantees in the existing literature. For nonconvex-PL and nonconvex-one-point-concave functions, we improve the existing complexity results for centralized minimax problems. Furthermore, we propose a momentum-based local-update algorithm, which has the same convergence guarantees, but outperforms Local SGDA as demonstrated in our experiments.
FedLite: A Scalable Approach for Federated Learning on Resource-constrained Clients
Feb 16, 2022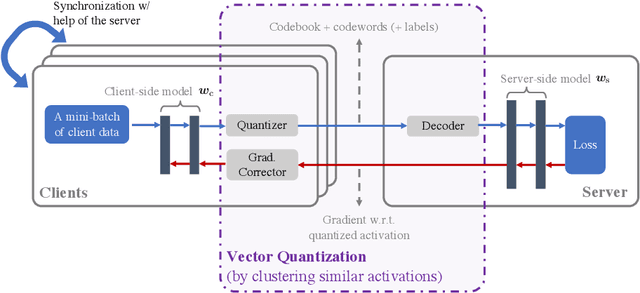

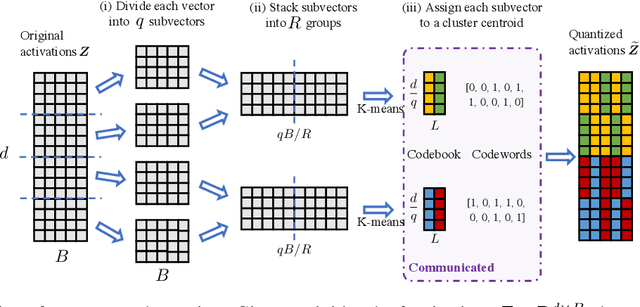
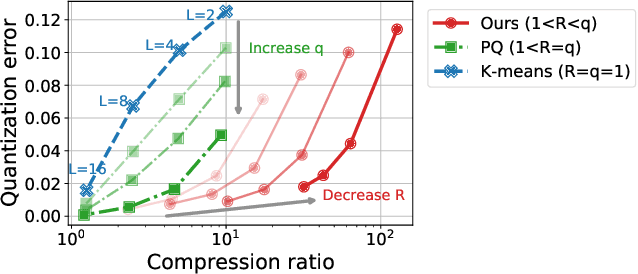
In classical federated learning, the clients contribute to the overall training by communicating local updates for the underlying model on their private data to a coordinating server. However, updating and communicating the entire model becomes prohibitively expensive when resource-constrained clients collectively aim to train a large machine learning model. Split learning provides a natural solution in such a setting, where only a small part of the model is stored and trained on clients while the remaining large part of the model only stays at the servers. However, the model partitioning employed in split learning introduces a significant amount of communication cost. This paper addresses this issue by compressing the additional communication using a novel clustering scheme accompanied by a gradient correction method. Extensive empirical evaluations on image and text benchmarks show that the proposed method can achieve up to $490\times$ communication cost reduction with minimal drop in accuracy, and enables a desirable performance vs. communication trade-off.
Leveraging Spatial and Temporal Correlations in Sparsified Mean Estimation
Oct 14, 2021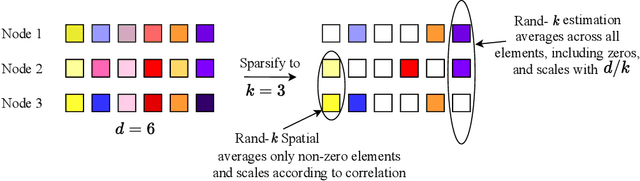
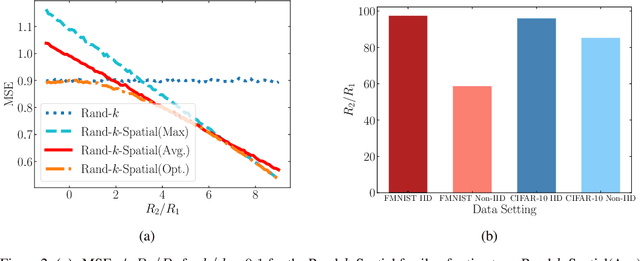
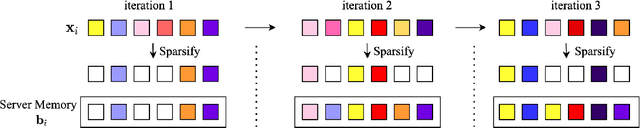
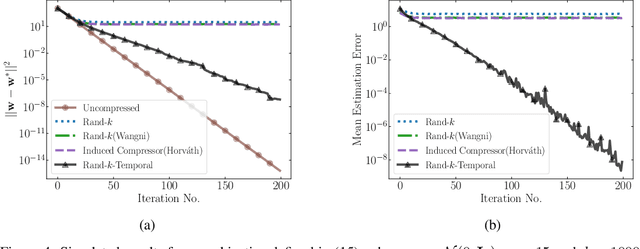
We study the problem of estimating at a central server the mean of a set of vectors distributed across several nodes (one vector per node). When the vectors are high-dimensional, the communication cost of sending entire vectors may be prohibitive, and it may be imperative for them to use sparsification techniques. While most existing work on sparsified mean estimation is agnostic to the characteristics of the data vectors, in many practical applications such as federated learning, there may be spatial correlations (similarities in the vectors sent by different nodes) or temporal correlations (similarities in the data sent by a single node over different iterations of the algorithm) in the data vectors. We leverage these correlations by simply modifying the decoding method used by the server to estimate the mean. We provide an analysis of the resulting estimation error as well as experiments for PCA, K-Means and Logistic Regression, which show that our estimators consistently outperform more sophisticated and expensive sparsification methods.
Personalized Federated Learning for Heterogeneous Clients with Clustered Knowledge Transfer
Sep 16, 2021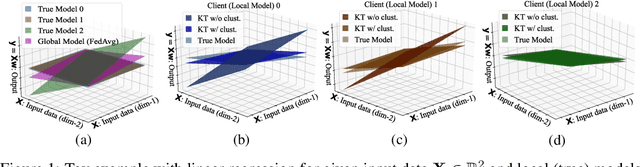
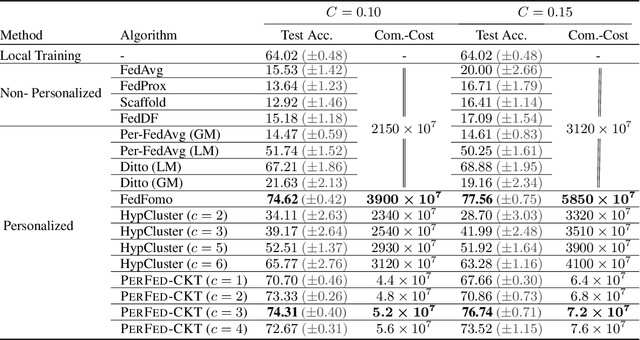
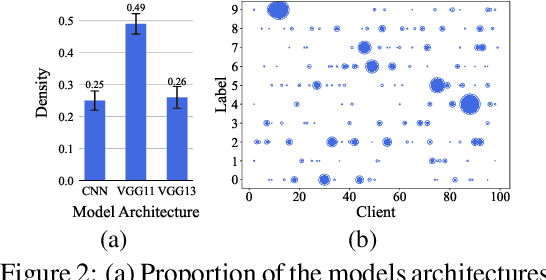
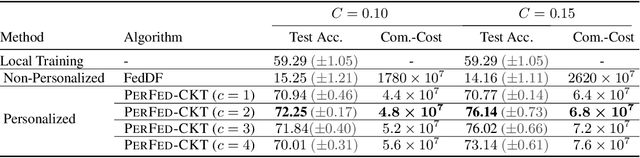
Personalized federated learning (FL) aims to train model(s) that can perform well for individual clients that are highly data and system heterogeneous. Most work in personalized FL, however, assumes using the same model architecture at all clients and increases the communication cost by sending/receiving models. This may not be feasible for realistic scenarios of FL. In practice, clients have highly heterogeneous system-capabilities and limited communication resources. In our work, we propose a personalized FL framework, PerFed-CKT, where clients can use heterogeneous model architectures and do not directly communicate their model parameters. PerFed-CKT uses clustered co-distillation, where clients use logits to transfer their knowledge to other clients that have similar data-distributions. We theoretically show the convergence and generalization properties of PerFed-CKT and empirically show that PerFed-CKT achieves high test accuracy with several orders of magnitude lower communication cost compared to the state-of-the-art personalized FL schemes.
Best-Arm Identification in Correlated Multi-Armed Bandits
Sep 10, 2021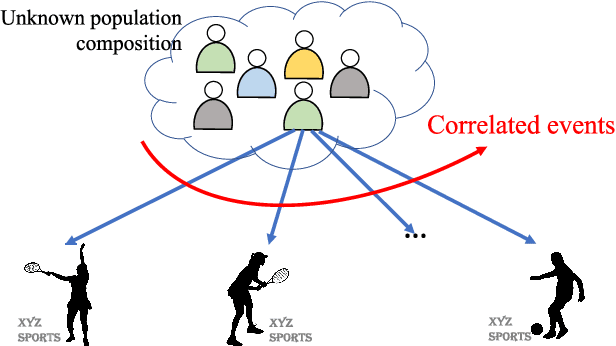
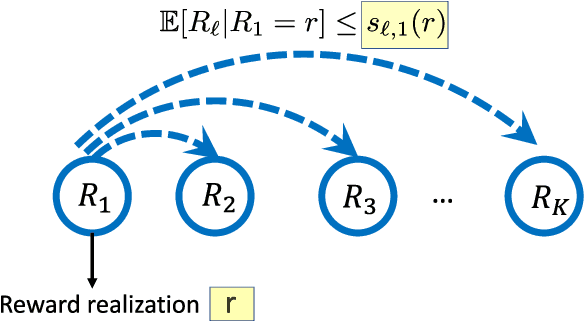
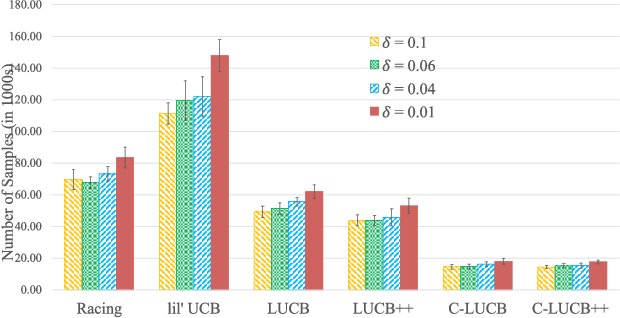
In this paper we consider the problem of best-arm identification in multi-armed bandits in the fixed confidence setting, where the goal is to identify, with probability $1-\delta$ for some $\delta>0$, the arm with the highest mean reward in minimum possible samples from the set of arms $\mathcal{K}$. Most existing best-arm identification algorithms and analyses operate under the assumption that the rewards corresponding to different arms are independent of each other. We propose a novel correlated bandit framework that captures domain knowledge about correlation between arms in the form of upper bounds on expected conditional reward of an arm, given a reward realization from another arm. Our proposed algorithm C-LUCB, which generalizes the LUCB algorithm utilizes this partial knowledge of correlations to sharply reduce the sample complexity of best-arm identification. More interestingly, we show that the total samples obtained by C-LUCB are of the form $\mathcal{O}\left(\sum_{k \in \mathcal{C}} \log\left(\frac{1}{\delta}\right)\right)$ as opposed to the typical $\mathcal{O}\left(\sum_{k \in \mathcal{K}} \log\left(\frac{1}{\delta}\right)\right)$ samples required in the independent reward setting. The improvement comes, as the $\mathcal{O}(\log(1/\delta))$ term is summed only for the set of competitive arms $\mathcal{C}$, which is a subset of the original set of arms $\mathcal{K}$. The size of the set $\mathcal{C}$, depending on the problem setting, can be as small as $2$, and hence using C-LUCB in the correlated bandits setting can lead to significant performance improvements. Our theoretical findings are supported by experiments on the Movielens and Goodreads recommendation datasets.
A Field Guide to Federated Optimization
Jul 14, 2021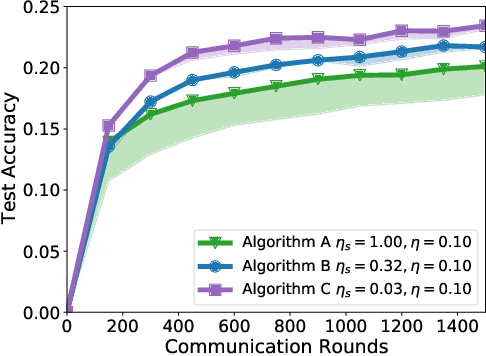


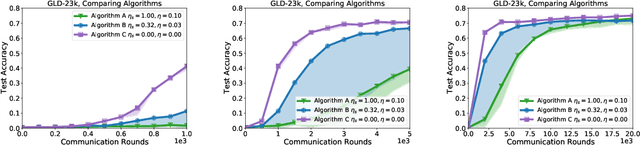
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
Job Dispatching Policies for Queueing Systems with Unknown Service Rates
Jun 10, 2021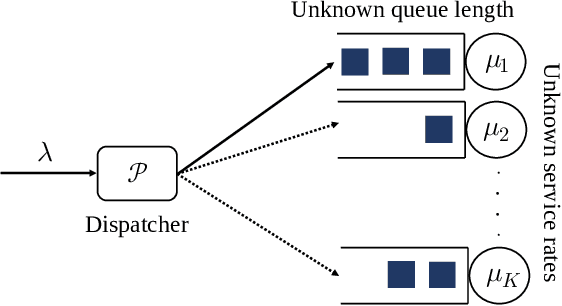
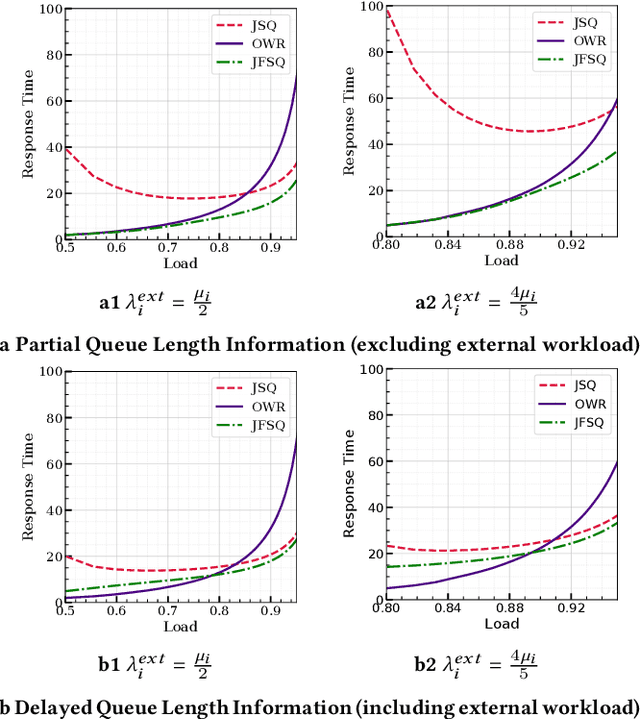
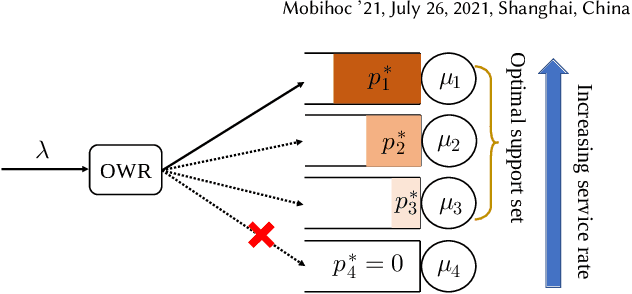
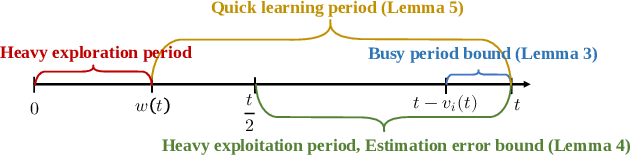
In multi-server queueing systems where there is no central queue holding all incoming jobs, job dispatching policies are used to assign incoming jobs to the queue at one of the servers. Classic job dispatching policies such as join-the-shortest-queue and shortest expected delay assume that the service rates and queue lengths of the servers are known to the dispatcher. In this work, we tackle the problem of job dispatching without the knowledge of service rates and queue lengths, where the dispatcher can only obtain noisy estimates of the service rates by observing job departures. This problem presents a novel exploration-exploitation trade-off between sending jobs to all the servers to estimate their service rates, and exploiting the currently known fastest servers to minimize the expected queueing delay. We propose a bandit-based exploration policy that learns the service rates from observed job departures. Unlike the standard multi-armed bandit problem where only one out of a finite set of actions is optimal, here the optimal policy requires identifying the optimal fraction of incoming jobs to be sent to each server. We present a regret analysis and simulations to demonstrate the effectiveness of the proposed bandit-based exploration policy.