 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCO: Reinforcing Large Reasoning Models with Discriminative Constrained Optimization
May 18, 2025The recent success and openness of DeepSeek-R1 have brought widespread attention to Group Relative Policy Optimization (GRPO) as a reinforcement learning method for large reasoning models (LRMs). In this work, we analyze the GRPO objective under a binary reward setting and reveal an inherent limitation of question-level difficulty bias. We also identify a connection between GRPO and traditional discriminative methods in supervised learning. Motivated by these insights, we introduce a new Discriminative Constrained Optimization (DisCO) framework for reinforcing LRMs, grounded in the principle of discriminative learning. The main differences between DisCO and GRPO and its recent variants are: (1) it replaces the group relative objective with a discriminative objective defined by a scoring function; (2) it abandons clipping-based surrogates in favor of non-clipping RL surrogate objectives used as scoring functions; (3) it employs a simple yet effective constrained optimization approach to enforce the KL divergence constraint, ensuring stable training. As a result, DisCO offers notable advantages over GRPO and its variants: (i) it completely eliminates difficulty bias by adopting discriminative objectives; (ii) it addresses the entropy instability in GRPO and its variants through the use of non-clipping scoring functions and a constrained optimization approach; (iii) it allows the incorporation of advanced discriminative learning techniques to address data imbalance, where a significant number of questions have more negative than positive generated answers during training. Our experiments on enhancing the mathematical reasoning capabilities of SFT-finetuned models show that DisCO significantly outperforms GRPO and its improved variants such as DAPO, achieving average gains of 7\% over GRPO and 6\% over DAPO across six benchmark tasks for an 1.5B model.
DaringFed: A Dynamic Bayesian Persuasion Pricing for Online Federated Learning under Two-sided Incomplete Information
May 09, 2025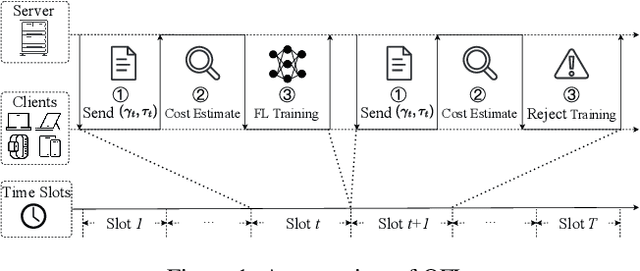


Online Federated Learning (OFL) is a real-time learning paradigm that sequentially executes parameter aggregation immediately for each random arriving client. To motivate clients to participate in OFL, it is crucial to offer appropriate incentives to offset the training resource consumption. However, the design of incentive mechanisms in OFL is constrained by the dynamic variability of Two-sided Incomplete Information (TII) concerning resources, where the server is unaware of the clients' dynamically changing computational resources, while clients lack knowledge of the real-time communication resources allocated by the server. To incentivize clients to participate in training by offering dynamic rewards to each arriving client, we design a novel Dynamic Bayesian persuasion pricing for online Federated learning (DaringFed) under TII. Specifically, we begin by formulating the interaction between the server and clients as a dynamic signaling and pricing allocation problem within a Bayesian persuasion game, and then demonstrate the existence of a unique Bayesian persuasion Nash equilibrium. By deriving the optimal design of DaringFed under one-sided incomplete information, we further analyze the approximate optimal design of DaringFed with a specific bound under TII. Finally, extensive evaluation conducted on real datasets demonstrate that DaringFed optimizes accuracy and converges speed by 16.99%, while experiments with synthetic datasets validate the convergence of estimate unknown values and the effectiveness of DaringFed in improving the server's utility by up to 12.6%.
Duplex Self-Aligning Resonant Beam Communications and Power Transfer with Coupled Spatially Distributed Laser Resonator
May 08, 2025



Sustainable energy supply and high-speed communications are two significant needs for mobile electronic devices. This paper introduces a self-aligning resonant beam system for simultaneous light information and power transfer (SLIPT), employing a novel coupled spatially distributed resonator (CSDR). The system utilizes a resonant beam for efficient power delivery and a second-harmonic beam for concurrent data transmission, inherently minimizing echo interference and enabling bidirectional communication. Through comprehensive analyses, we investigate the CSDR's stable region, beam evolution, and power characteristics in relation to working distance and device parameters. Numerical simulations validate the CSDR-SLIPT system's feasibility by identifying a stable beam waist location for achieving accurate mode-match coupling between two spatially distributed resonant cavities and demonstrating its operational range and efficient power delivery across varying distances. The research reveals the system's benefits in terms of both safety and energy transmission efficiency. We also demonstrate the trade-off among the reflectivities of the cavity mirrors in the CSDR. These findings offer valuable design insights for resonant beam systems, advancing SLIPT with significant potential for remote device connectivity.
Single-loop Algorithms for Stochastic Non-convex Optimization with Weakly-Convex Constraints
Apr 21, 2025Constrained optimization with multiple functional inequality constraints has significant applications in machine learning. This paper examines a crucial subset of such problems where both the objective and constraint functions are weakly convex. Existing methods often face limitations, including slow convergence rates or reliance on double-loop algorithmic designs. To overcome these challenges, we introduce a novel single-loop penalty-based stochastic algorithm. Following the classical exact penalty method, our approach employs a {\bf hinge-based penalty}, which permits the use of a constant penalty parameter, enabling us to achieve a {\bf state-of-the-art complexity} for finding an approximate Karush-Kuhn-Tucker (KKT) solution. We further extend our algorithm to address finite-sum coupled compositional objectives, which are prevalent in artificial intelligence applications, establishing improved complexity over existing approaches. Finally, we validate our method through experiments on fair learning with receiver operating characteristic (ROC) fairness constraints and continual learning with non-forgetting constraints.
A Novel Radar Constant False Alarm Rate Detection Algorithm Based on VAMP Deep Unfolding
Apr 14, 2025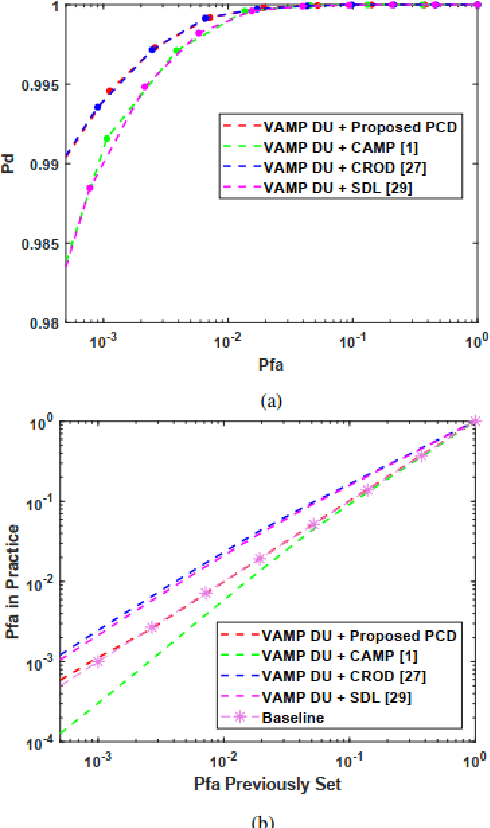
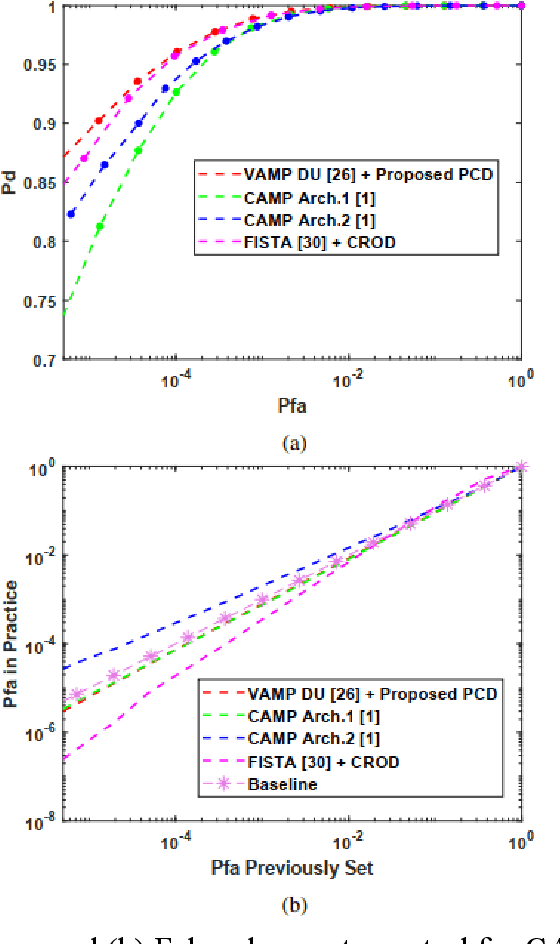
The combination of deep unfolding with vector approximate message passing (VAMP) algorithm, results in faster convergence and higher sparse recovery accuracy than traditional compressive sensing approaches. However, deep unfolding alters the parameters in traditional VAMP algorithm, resulting in the unattainable distribution parameter of the recovery error of non-sparse noisy estimation via traditional VAMP, which hinders the utilization of VAMP deep unfolding in constant false alarm rate (CFAR) detection in sub-Nyquist radar system. Based on VAMP deep unfolding, we provide a parameter convergence detector (PCD) to estimate the recovery error distribution parameter and implement CFAR detection. Compared to the state-of-the-art approaches, both the sparse solution and non-sparse noisy estimation are utilized to estimate the distribution parameter and implement CFAR detection in PCD, which leverages both the VAMP distribution property and the improved sparse recovery accuracy provided by deep unfolding. Simulation results indicate that PCD offers improved false alarm rate control performance and higher target detection rate.
Parameter Convergence Detector Based on VAMP Deep Unfolding: A Novel Radar Constant False Alarm Rate Detection Algorithm
Apr 14, 2025The sub-Nyquist radar framework exploits the sparsity of signals, which effectively alleviates the pressure on system storage and transmission bandwidth. Compressed sensing (CS) algorithms, such as the VAMP algorithm, are used for sparse signal processing in the sub-Nyquist radar framework. By combining deep unfolding techniques with VAMP, faster convergence and higher accuracy than traditional CS algorithms are achieved. However, deep unfolding disrupts the parameter constrains in traditional VAMP algorithm, leading to the distribution of non-sparse noisy estimation in VAMP deep unfolding unknown, and its distribution parameter unable to be obtained directly using method of traditional VAMP, which prevents the application of VAMP deep unfolding in radar constant false alarm rate (CFAR) detection. To address this problem, we explore the distribution of the non-sparse noisy estimation and propose a parameter convergence detector (PCD) to achieve CFAR detection based on VAMP deep unfolding. Compared to the state-of-the-art methods, PCD leverages not only the sparse solution, but also the non-sparse noisy estimation, which is used to iteratively estimate the distribution parameter and served as the test statistic in detection process. In this way, the proposed algorithm takes advantage of both the enhanced sparse recovery accuracy from deep unfolding and the distribution property of VAMP, thereby achieving superior CFAR detection performance. Additionally, the PCD requires no information about the power of AWGN in the environment, which is more suitable for practical application. The convergence performance and effectiveness of the proposed PCD are analyzed based on the Banach Fixed-Point Theorem. Numerical simulations and practical data experiments demonstrate that PCD can achieve better false alarm control and target detection performance.
Reinforcement Learning Outperforms Supervised Fine-Tuning: A Case Study on Audio Question Answering
Mar 17, 2025



Recently, reinforcement learning (RL) has been shown to greatly enhance the reasoning capabilities of large language models (LLMs), and RL-based approaches have been progressively applied to visual multimodal tasks. However, the audio modality has largely been overlooked in these developments. Thus, we conduct a series of RL explorations in audio understanding and reasoning, specifically focusing on the audio question answering (AQA) task. We leverage the group relative policy optimization (GRPO) algorithm to Qwen2-Audio-7B-Instruct, and our experiments demonstrated state-of-the-art performance on the MMAU Test-mini benchmark, achieving an accuracy rate of 64.5%. The main findings in this technical report are as follows: 1) The GRPO algorithm can be effectively applied to large audio language models (LALMs), even when the model has only 8.2B parameters; 2) With only 38k post-training samples, RL significantly outperforms supervised fine-tuning (SFT), indicating that RL-based approaches can be effective without large datasets; 3) The explicit reasoning process has not shown significant benefits for AQA tasks, and how to efficiently utilize deep thinking remains an open question for further research; 4) LALMs still lag far behind humans auditory-language reasoning, suggesting that the RL-based approaches warrant further exploration. Our project is available at https://github.com/xiaomi-research/r1-aqa and https://huggingface.co/mispeech/r1-aqa.
FlowAgent: Achieving Compliance and Flexibility for Workflow Agents
Feb 20, 2025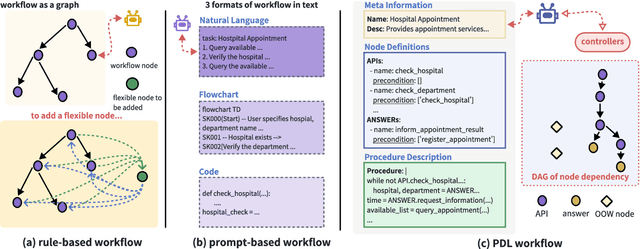

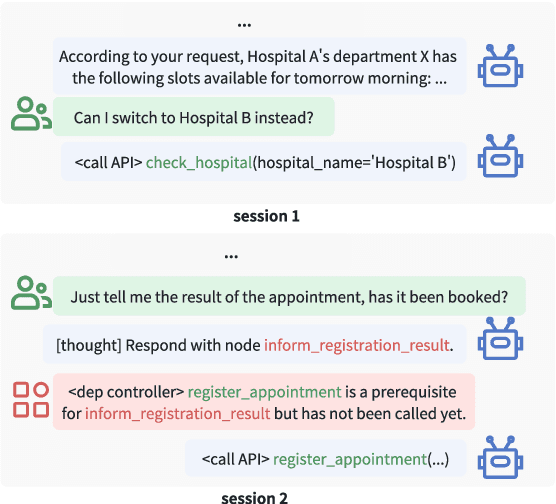
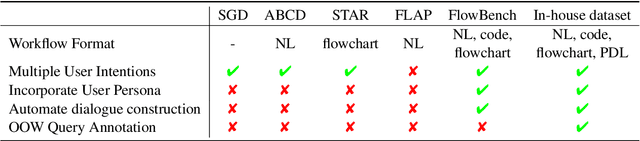
The integration of workflows with large language models (LLMs) enables LLM-based agents to execute predefined procedures, enhancing automation in real-world applications. Traditional rule-based methods tend to limit the inherent flexibility of LLMs, as their predefined execution paths restrict the models' action space, particularly when the unexpected, out-of-workflow (OOW) queries are encountered. Conversely, prompt-based methods allow LLMs to fully control the flow, which can lead to diminished enforcement of procedural compliance. To address these challenges, we introduce FlowAgent, a novel agent framework designed to maintain both compliance and flexibility. We propose the Procedure Description Language (PDL), which combines the adaptability of natural language with the precision of code to formulate workflows. Building on PDL, we develop a comprehensive framework that empowers LLMs to manage OOW queries effectively, while keeping the execution path under the supervision of a set of controllers. Additionally, we present a new evaluation methodology to rigorously assess an LLM agent's ability to handle OOW scenarios, going beyond routine flow compliance tested in existing benchmarks. Experiments on three datasets demonstrate that FlowAgent not only adheres to workflows but also effectively manages OOW queries, highlighting its dual strengths in compliance and flexibility. The code is available at https://github.com/Lightblues/FlowAgent.
CAMP in the Odyssey: Provably Robust Reinforcement Learning with Certified Radius Maximization
Jan 29, 2025



Deep reinforcement learning (DRL) has gained widespread adoption in control and decision-making tasks due to its strong performance in dynamic environments. However, DRL agents are vulnerable to noisy observations and adversarial attacks, and concerns about the adversarial robustness of DRL systems have emerged. Recent efforts have focused on addressing these robustness issues by establishing rigorous theoretical guarantees for the returns achieved by DRL agents in adversarial settings. Among these approaches, policy smoothing has proven to be an effective and scalable method for certifying the robustness of DRL agents. Nevertheless, existing certifiably robust DRL relies on policies trained with simple Gaussian augmentations, resulting in a suboptimal trade-off between certified robustness and certified return. To address this issue, we introduce a novel paradigm dubbed \texttt{C}ertified-r\texttt{A}dius-\texttt{M}aximizing \texttt{P}olicy (\texttt{CAMP}) training. \texttt{CAMP} is designed to enhance DRL policies, achieving better utility without compromising provable robustness. By leveraging the insight that the global certified radius can be derived from local certified radii based on training-time statistics, \texttt{CAMP} formulates a surrogate loss related to the local certified radius and optimizes the policy guided by this surrogate loss. We also introduce \textit{policy imitation} as a novel technique to stabilize \texttt{CAMP} training. Experimental results demonstrate that \texttt{CAMP} significantly improves the robustness-return trade-off across various tasks. Based on the results, \texttt{CAMP} can achieve up to twice the certified expected return compared to that of baselines. Our code is available at https://github.com/NeuralSec/camp-robust-rl.
Fusion of Millimeter-wave Radar and Pulse Oximeter Data for Low-burden Diagnosis of Obstructive Sleep Apnea-Hypopnea Syndrome
Jan 25, 2025



Objective: The aim of the study is to develop a novel method for improved diagnosis of obstructive sleep apnea-hypopnea syndrome (OSAHS) in clinical or home settings, with the focus on achieving diagnostic performance comparable to the gold-standard polysomnography (PSG) with significantly reduced monitoring burden. Methods: We propose a method using millimeter-wave radar and pulse oximeter for OSAHS diagnosis (ROSA). It contains a sleep apnea-hypopnea events (SAE) detection network, which directly predicts the temporal localization of SAE, and a sleep staging network, which predicts the sleep stages throughout the night, based on radar signals. It also fuses oxygen saturation (SpO2) information from the pulse oximeter to adjust the score of SAE detected by radar. Results: Experimental results on a real-world dataset (>800 hours of overnight recordings, 100 subjects) demonstrated high agreement (ICC=0.9870) on apnea-hypopnea index (AHI) between ROSA and PSG. ROSA also exhibited excellent diagnostic performance, exceeding 90% in accuracy across AHI diagnostic thresholds of 5, 15 and 30 events/h. Conclusion: ROSA improves diagnostic accuracy by fusing millimeter-wave radar and pulse oximeter data. It provides a reliable and low-burden solution for OSAHS diagnosis. Significance: ROSA addresses the limitations of high complexity and monitoring burden associated with traditional PSG. The high accuracy and low burden of ROSA show its potential to improve the accessibility of OSAHS diagnosis among population.