 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboVQA: Multimodal Long-Horizon Reasoning for Robotics
Nov 01, 2023



We present a scalable, bottom-up and intrinsically diverse data collection scheme that can be used for high-level reasoning with long and medium horizons and that has 2.2x higher throughput compared to traditional narrow top-down step-by-step collection. We collect realistic data by performing any user requests within the entirety of 3 office buildings and using multiple robot and human embodiments. With this data, we show that models trained on all embodiments perform better than ones trained on the robot data only, even when evaluated solely on robot episodes. We find that for a fixed collection budget it is beneficial to take advantage of cheaper human collection along with robot collection. We release a large and highly diverse (29,520 unique instructions) dataset dubbed RoboVQA containing 829,502 (video, text) pairs for robotics-focused visual question answering. We also demonstrate how evaluating real robot experiments with an intervention mechanism enables performing tasks to completion, making it deployable with human oversight even if imperfect while also providing a single performance metric. We demonstrate a single video-conditioned model named RoboVQA-VideoCoCa trained on our dataset that is capable of performing a variety of grounded high-level reasoning tasks in broad realistic settings with a cognitive intervention rate 46% lower than the zero-shot state of the art visual language model (VLM) baseline and is able to guide real robots through long-horizon tasks. The performance gap with zero-shot state-of-the-art models indicates that a lot of grounded data remains to be collected for real-world deployment, emphasizing the critical need for scalable data collection approaches. Finally, we show that video VLMs significantly outperform single-image VLMs with an average error rate reduction of 19% across all VQA tasks. Data and videos available at https://robovqa.github.io
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023



Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Get Back Here: Robust Imitation by Return-to-Distribution Planning
May 02, 2023We consider the Imitation Learning (IL) setup where expert data are not collected on the actual deployment environment but on a different version. To address the resulting distribution shift, we combine behavior cloning (BC) with a planner that is tasked to bring the agent back to states visited by the expert whenever the agent deviates from the demonstration distribution. The resulting algorithm, POIR, can be trained offline, and leverages online interactions to efficiently fine-tune its planner to improve performance over time. We test POIR on a variety of human-generated manipulation demonstrations in a realistic robotic manipulation simulator and show robustness of the learned policy to different initial state distributions and noisy dynamics.
Investigating the role of model-based learning in exploration and transfer
Feb 08, 2023State of the art reinforcement learning has enabled training agents on tasks of ever increasing complexity. However, the current paradigm tends to favor training agents from scratch on every new task or on collections of tasks with a view towards generalizing to novel task configurations. The former suffers from poor data efficiency while the latter is difficult when test tasks are out-of-distribution. Agents that can effectively transfer their knowledge about the world pose a potential solution to these issues. In this paper, we investigate transfer learning in the context of model-based agents. Specifically, we aim to understand when exactly environment models have an advantage and why. We find that a model-based approach outperforms controlled model-free baselines for transfer learning. Through ablations, we show that both the policy and dynamics model learnt through exploration matter for successful transfer. We demonstrate our results across three domains which vary in their requirements for transfer: in-distribution procedural (Crafter), in-distribution identical (RoboDesk), and out-of-distribution (Meta-World). Our results show that intrinsic exploration combined with environment models present a viable direction towards agents that are self-supervised and able to generalize to novel reward functions.
Learning Reward Functions for Robotic Manipulation by Observing Humans
Nov 16, 2022Observing a human demonstrator manipulate objects provides a rich, scalable and inexpensive source of data for learning robotic policies. However, transferring skills from human videos to a robotic manipulator poses several challenges, not least a difference in action and observation spaces. In this work, we use unlabeled videos of humans solving a wide range of manipulation tasks to learn a task-agnostic reward function for robotic manipulation policies. Thanks to the diversity of this training data, the learned reward function sufficiently generalizes to image observations from a previously unseen robot embodiment and environment to provide a meaningful prior for directed exploration in reinforcement learning. The learned rewards are based on distances to a goal in an embedding space learned using a time-contrastive objective. By conditioning the function on a goal image, we are able to reuse one model across a variety of tasks. Unlike prior work on leveraging human videos to teach robots, our method, Human Offline Learned Distances (HOLD) requires neither a priori data from the robot environment, nor a set of task-specific human demonstrations, nor a predefined notion of correspondence across morphologies, yet it is able to accelerate training of several manipulation tasks on a simulated robot arm compared to using only a sparse reward obtained from task completion.
C3PO: Learning to Achieve Arbitrary Goals via Massively Entropic Pretraining
Nov 07, 2022



Given a particular embodiment, we propose a novel method (C3PO) that learns policies able to achieve any arbitrary position and pose. Such a policy would allow for easier control, and would be re-useable as a key building block for downstream tasks. The method is two-fold: First, we introduce a novel exploration algorithm that optimizes for uniform coverage, is able to discover a set of achievable states, and investigates its abilities in attaining both high coverage, and hard-to-discover states; Second, we leverage this set of achievable states as training data for a universal goal-achievement policy, a goal-based SAC variant. We demonstrate the trained policy's performance in achieving a large number of novel states. Finally, we showcase the influence of massive unsupervised training of a goal-achievement policy with state-of-the-art pose-based control of the Hopper, Walker, Halfcheetah, Humanoid and Ant embodiments.
Learning Dynamics Models for Model Predictive Agents
Sep 29, 2021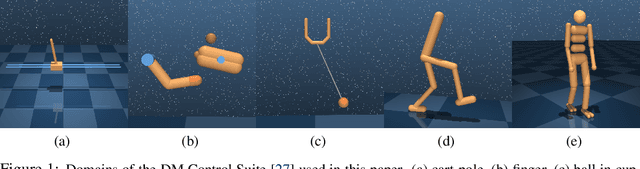
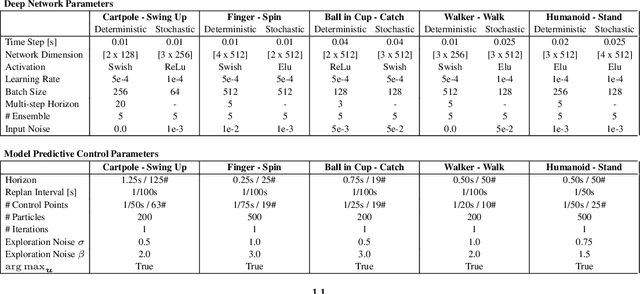
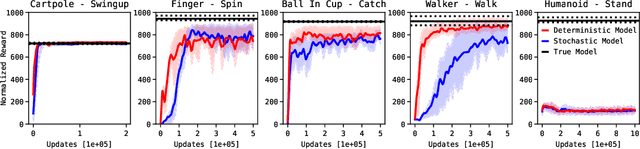
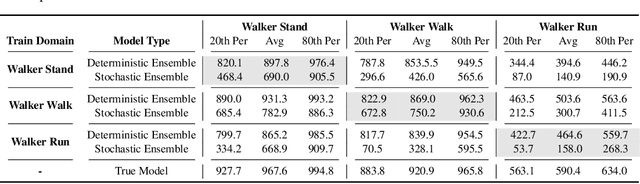
Model-Based Reinforcement Learning involves learning a \textit{dynamics model} from data, and then using this model to optimise behaviour, most often with an online \textit{planner}. Much of the recent research along these lines presents a particular set of design choices, involving problem definition, model learning and planning. Given the multiple contributions, it is difficult to evaluate the effects of each. This paper sets out to disambiguate the role of different design choices for learning dynamics models, by comparing their performance to planning with a ground-truth model -- the simulator. First, we collect a rich dataset from the training sequence of a model-free agent on 5 domains of the DeepMind Control Suite. Second, we train feed-forward dynamics models in a supervised fashion, and evaluate planner performance while varying and analysing different model design choices, including ensembling, stochasticity, multi-step training and timestep size. Besides the quantitative analysis, we describe a set of qualitative findings, rules of thumb, and future research directions for planning with learned dynamics models. Videos of the results are available at https://sites.google.com/view/learning-better-models.
Residual Reinforcement Learning from Demonstrations
Jun 15, 2021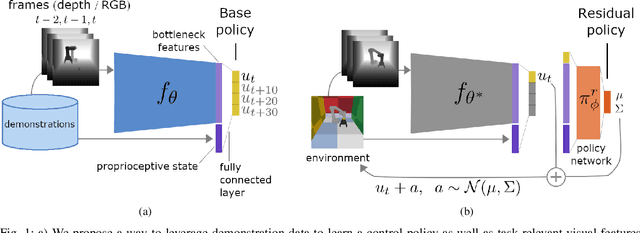



Residual reinforcement learning (RL) has been proposed as a way to solve challenging robotic tasks by adapting control actions from a conventional feedback controller to maximize a reward signal. We extend the residual formulation to learn from visual inputs and sparse rewards using demonstrations. Learning from images, proprioceptive inputs and a sparse task-completion reward relaxes the requirement of accessing full state features, such as object and target positions. In addition, replacing the base controller with a policy learned from demonstrations removes the dependency on a hand-engineered controller in favour of a dataset of demonstrations, which can be provided by non-experts. Our experimental evaluation on simulated manipulation tasks on a 6-DoF UR5 arm and a 28-DoF dexterous hand demonstrates that residual RL from demonstrations is able to generalize to unseen environment conditions more flexibly than either behavioral cloning or RL fine-tuning, and is capable of solving high-dimensional, sparse-reward tasks out of reach for RL from scratch.
Learning to run a Power Network Challenge: a Retrospective Analysis
Mar 02, 2021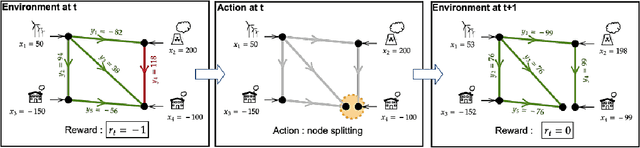
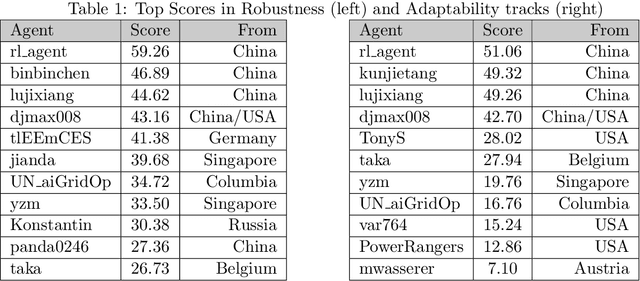
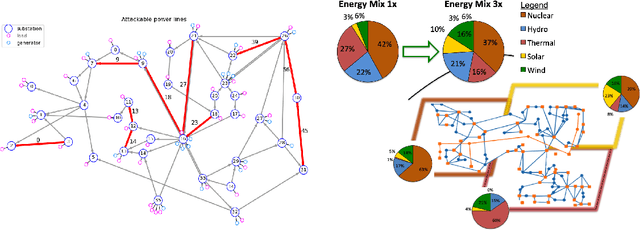

Power networks, responsible for transporting electricity across large geographical regions, are complex infrastructures on which modern life critically depend. Variations in demand and production profiles, with increasing renewable energy integration, as well as the high voltage network technology, constitute a real challenge for human operators when optimizing electricity transportation while avoiding blackouts. Motivated to investigate the potential of Artificial Intelligence methods in enabling adaptability in power network operation, we have designed a L2RPN challenge to encourage the development of reinforcement learning solutions to key problems present in the next-generation power networks. The NeurIPS 2020 competition was well received by the international community attracting over 300 participants worldwide. The main contribution of this challenge is our proposed comprehensive Grid2Op framework, and associated benchmark, which plays realistic sequential network operations scenarios. The framework is open-sourced and easily re-usable to define new environments with its companion GridAlive ecosystem. It relies on existing non-linear physical simulators and let us create a series of perturbations and challenges that are representative of two important problems: a) the uncertainty resulting from the increased use of unpredictable renewable energy sources, and b) the robustness required with contingent line disconnections. In this paper, we provide details about the competition highlights. We present the benchmark suite and analyse the winning solutions of the challenge, observing one super-human performance demonstration by the best agent. We propose our organizational insights for a successful competition and conclude on open research avenues. We expect our work will foster research to create more sustainable solutions for power network operations.
A Geometric Perspective on Self-Supervised Policy Adaptation
Nov 14, 2020

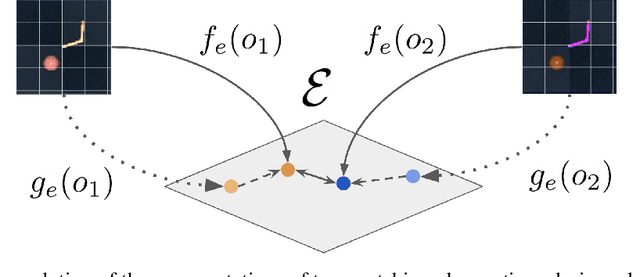

One of the most challenging aspects of real-world reinforcement learning (RL) is the multitude of unpredictable and ever-changing distractions that could divert an agent from what was tasked to do in its training environment. While an agent could learn from reward signals to ignore them, the complexity of the real-world can make rewards hard to acquire, or, at best, extremely sparse. A recent class of self-supervised methods have shown promise that reward-free adaptation under challenging distractions is possible. However, previous work focused on a short one-episode adaptation setting. In this paper, we consider a long-term adaptation setup that is more akin to the specifics of the real-world and propose a geometric perspective on self-supervised adaptation. We empirically describe the processes that take place in the embedding space during this adaptation process, reveal some of its undesirable effects on performance and show how they can be eliminated. Moreover, we theoretically study how actor-based and actor-free agents can further generalise to the target environment by manipulating the geometry of the manifolds described by the actor and critic functions.