 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Object-Centric Learning from Video
Nov 24, 2021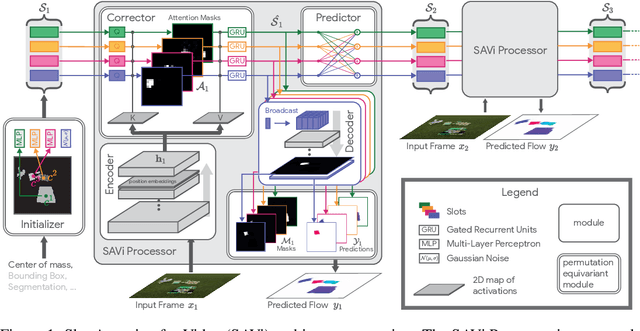

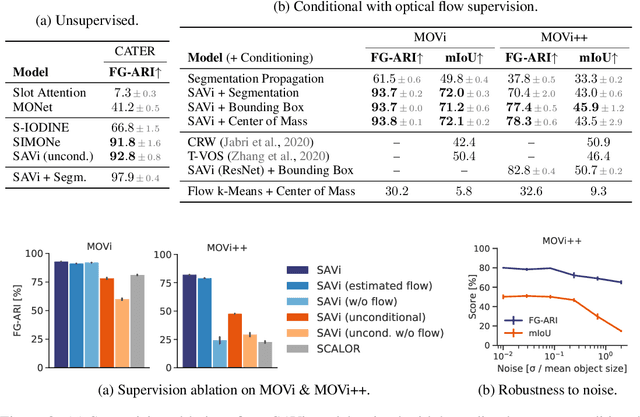

Object-centric representations are a promising path toward more systematic generalization by providing flexible abstractions upon which compositional world models can be built. Recent work on simple 2D and 3D datasets has shown that models with object-centric inductive biases can learn to segment and represent meaningful objects from the statistical structure of the data alone without the need for any supervision. However, such fully-unsupervised methods still fail to scale to diverse realistic data, despite the use of increasingly complex inductive biases such as priors for the size of objects or the 3D geometry of the scene. In this paper, we instead take a weakly-supervised approach and focus on how 1) using the temporal dynamics of video data in the form of optical flow and 2) conditioning the model on simple object location cues can be used to enable segmenting and tracking objects in significantly more realistic synthetic data. We introduce a sequential extension to Slot Attention which we train to predict optical flow for realistic looking synthetic scenes and show that conditioning the initial state of this model on a small set of hints, such as center of mass of objects in the first frame, is sufficient to significantly improve instance segmentation. These benefits generalize beyond the training distribution to novel objects, novel backgrounds, and to longer video sequences. We also find that such initial-state-conditioning can be used during inference as a flexible interface to query the model for specific objects or parts of objects, which could pave the way for a range of weakly-supervised approaches and allow more effective interaction with trained models.
SMURF: Self-Teaching Multi-Frame Unsupervised RAFT with Full-Image Warping
May 14, 2021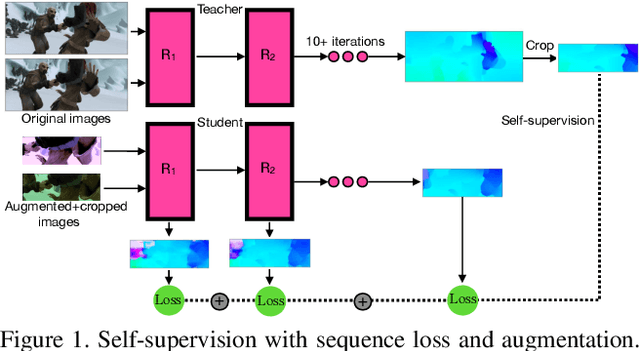
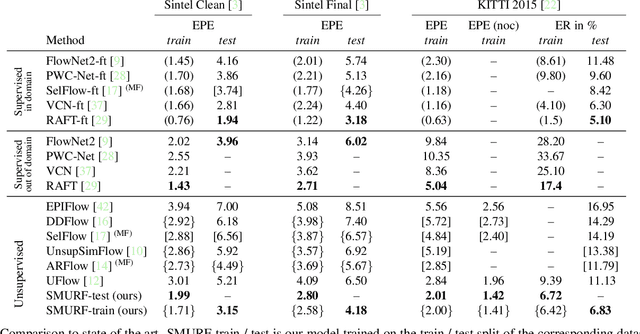
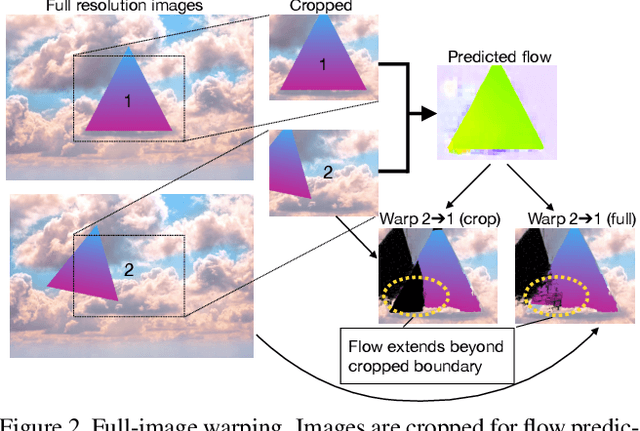
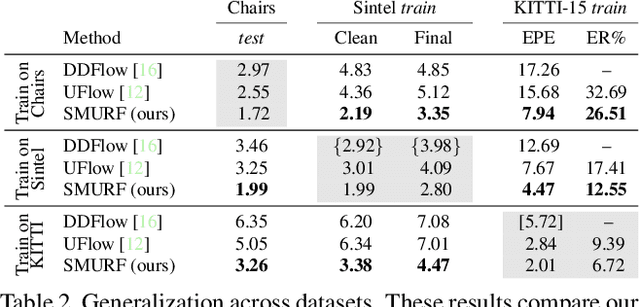
We present SMURF, a method for unsupervised learning of optical flow that improves state of the art on all benchmarks by $36\%$ to $40\%$ (over the prior best method UFlow) and even outperforms several supervised approaches such as PWC-Net and FlowNet2. Our method integrates architecture improvements from supervised optical flow, i.e. the RAFT model, with new ideas for unsupervised learning that include a sequence-aware self-supervision loss, a technique for handling out-of-frame motion, and an approach for learning effectively from multi-frame video data while still only requiring two frames for inference.
MT-Opt: Continuous Multi-Task Robotic Reinforcement Learning at Scale
Apr 27, 2021
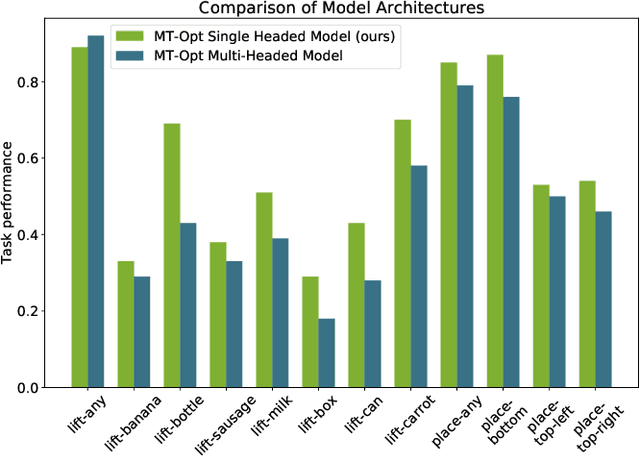
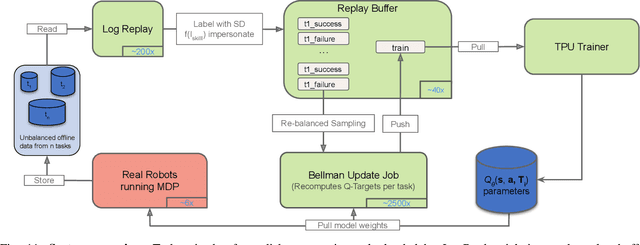
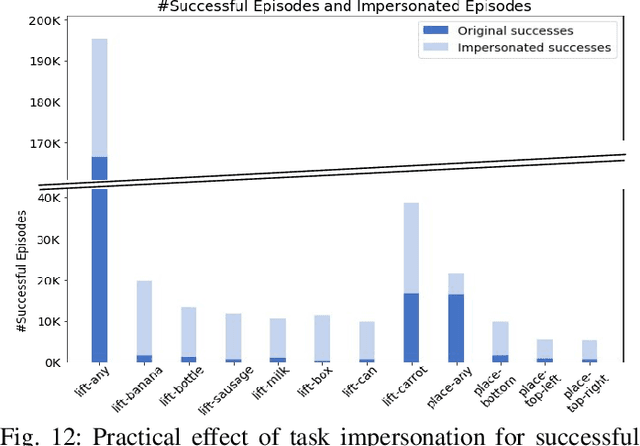
General-purpose robotic systems must master a large repertoire of diverse skills to be useful in a range of daily tasks. While reinforcement learning provides a powerful framework for acquiring individual behaviors, the time needed to acquire each skill makes the prospect of a generalist robot trained with RL daunting. In this paper, we study how a large-scale collective robotic learning system can acquire a repertoire of behaviors simultaneously, sharing exploration, experience, and representations across tasks. In this framework new tasks can be continuously instantiated from previously learned tasks improving overall performance and capabilities of the system. To instantiate this system, we develop a scalable and intuitive framework for specifying new tasks through user-provided examples of desired outcomes, devise a multi-robot collective learning system for data collection that simultaneously collects experience for multiple tasks, and develop a scalable and generalizable multi-task deep reinforcement learning method, which we call MT-Opt. We demonstrate how MT-Opt can learn a wide range of skills, including semantic picking (i.e., picking an object from a particular category), placing into various fixtures (e.g., placing a food item onto a plate), covering, aligning, and rearranging. We train and evaluate our system on a set of 12 real-world tasks with data collected from 7 robots, and demonstrate the performance of our system both in terms of its ability to generalize to structurally similar new tasks, and acquire distinct new tasks more quickly by leveraging past experience. We recommend viewing the videos at https://karolhausman.github.io/mt-opt/
Adaptive Intermediate Representations for Video Understanding
Apr 14, 2021
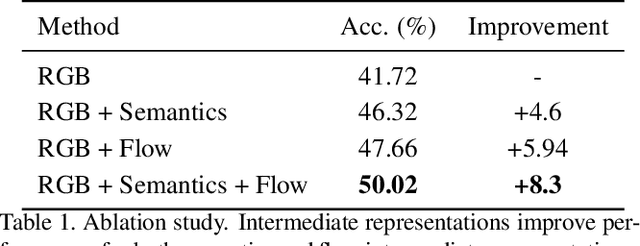
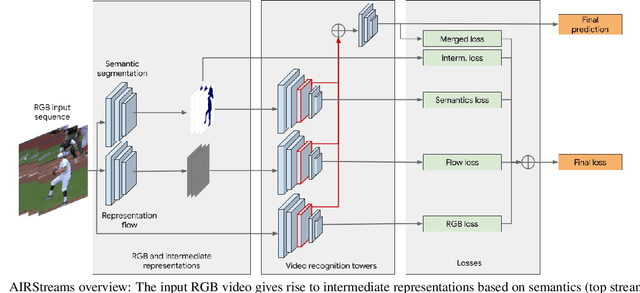
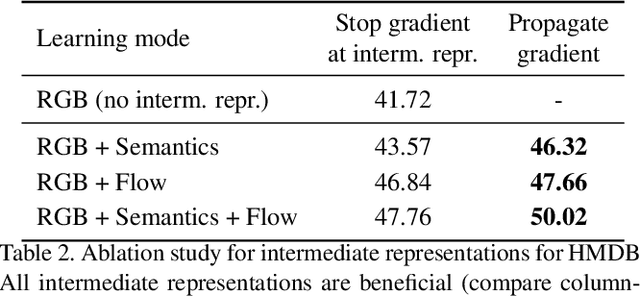
A common strategy to video understanding is to incorporate spatial and motion information by fusing features derived from RGB frames and optical flow. In this work, we introduce a new way to leverage semantic segmentation as an intermediate representation for video understanding and use it in a way that requires no additional labeling. Second, we propose a general framework which learns the intermediate representations (optical flow and semantic segmentation) jointly with the final video understanding task and allows the adaptation of the representations to the end goal. Despite the use of intermediate representations within the network, during inference, no additional data beyond RGB sequences is needed, enabling efficient recognition with a single network. Finally, we present a way to find the optimal learning configuration by searching the best loss weighting via evolution. We obtain more powerful visual representations for videos which lead to performance gains over the state-of-the-art.
The Distracting Control Suite -- A Challenging Benchmark for Reinforcement Learning from Pixels
Jan 07, 2021
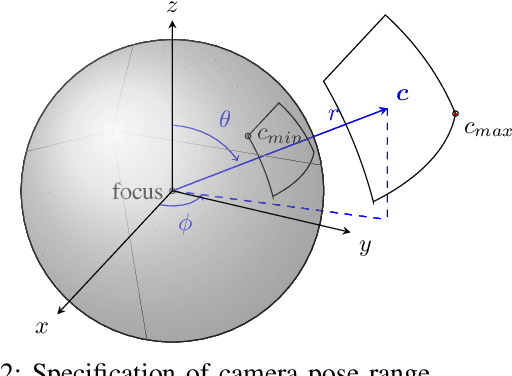
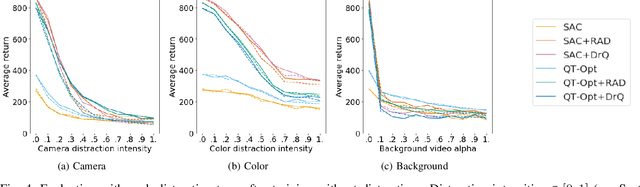
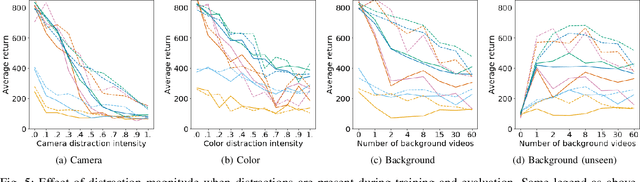
Robots have to face challenging perceptual settings, including changes in viewpoint, lighting, and background. Current simulated reinforcement learning (RL) benchmarks such as DM Control provide visual input without such complexity, which limits the transfer of well-performing methods to the real world. In this paper, we extend DM Control with three kinds of visual distractions (variations in background, color, and camera pose) to produce a new challenging benchmark for vision-based control, and we analyze state of the art RL algorithms in these settings. Our experiments show that current RL methods for vision-based control perform poorly under distractions, and that their performance decreases with increasing distraction complexity, showing that new methods are needed to cope with the visual complexities of the real world. We also find that combinations of multiple distraction types are more difficult than a mere combination of their individual effects.
Learning Object-Centric Video Models by Contrasting Sets
Nov 20, 2020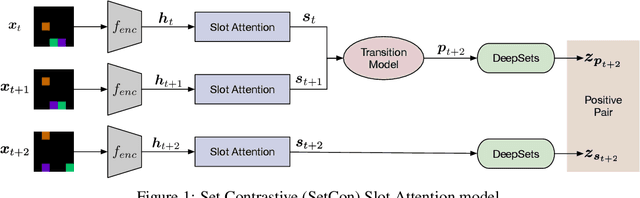
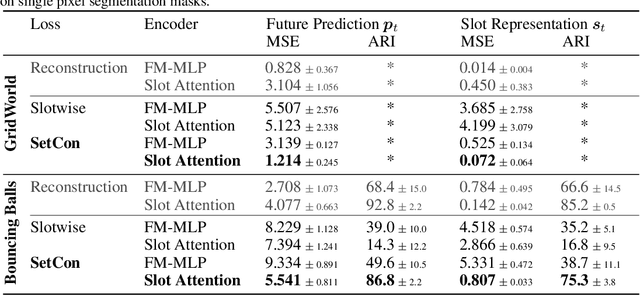
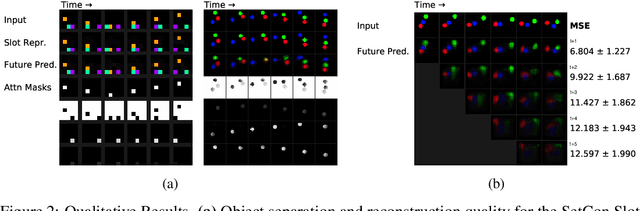
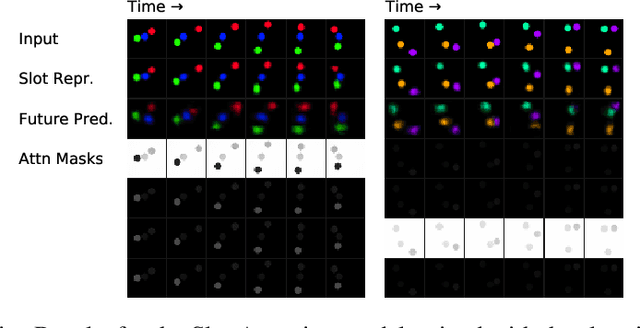
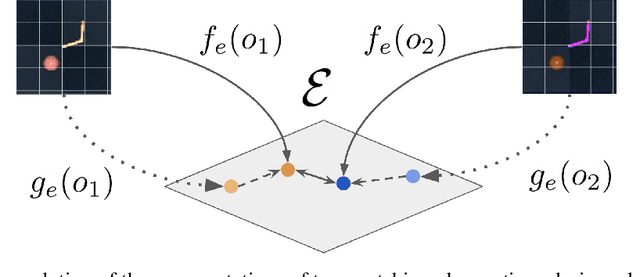
Contrastive, self-supervised learning of object representations recently emerged as an attractive alternative to reconstruction-based training. Prior approaches focus on contrasting individual object representations (slots) against one another. However, a fundamental problem with this approach is that the overall contrastive loss is the same for (i) representing a different object in each slot, as it is for (ii) (re-)representing the same object in all slots. Thus, this objective does not inherently push towards the emergence of object-centric representations in the slots. We address this problem by introducing a global, set-based contrastive loss: instead of contrasting individual slot representations against one another, we aggregate the representations and contrast the joined sets against one another. Additionally, we introduce attention-based encoders to this contrastive setup which simplifies training and provides interpretable object masks. Our results on two synthetic video datasets suggest that this approach compares favorably against previous contrastive methods in terms of reconstruction, future prediction and object separation performance.
A Geometric Perspective on Self-Supervised Policy Adaptation
Nov 14, 2020


One of the most challenging aspects of real-world reinforcement learning (RL) is the multitude of unpredictable and ever-changing distractions that could divert an agent from what was tasked to do in its training environment. While an agent could learn from reward signals to ignore them, the complexity of the real-world can make rewards hard to acquire, or, at best, extremely sparse. A recent class of self-supervised methods have shown promise that reward-free adaptation under challenging distractions is possible. However, previous work focused on a short one-episode adaptation setting. In this paper, we consider a long-term adaptation setup that is more akin to the specifics of the real-world and propose a geometric perspective on self-supervised adaptation. We empirically describe the processes that take place in the embedding space during this adaptation process, reveal some of its undesirable effects on performance and show how they can be eliminated. Moreover, we theoretically study how actor-based and actor-free agents can further generalise to the target environment by manipulating the geometry of the manifolds described by the actor and critic functions.
What Matters in Unsupervised Optical Flow
Jun 08, 2020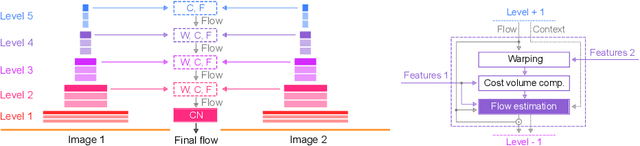
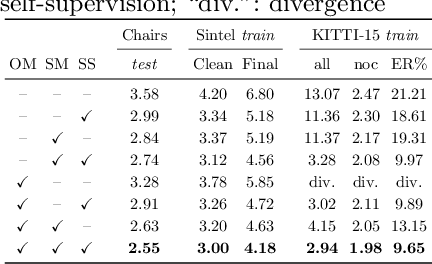

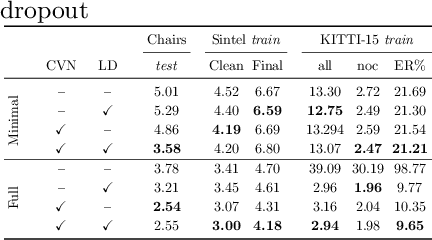
We systematically compare and analyze a set of key components in unsupervised optical flow to identify which photometric loss, occlusion handling, and smoothness regularization is most effective. Alongside this investigation we construct a number of novel improvements to unsupervised flow models, such as cost volume normalization, stopping the gradient at the occlusion mask, encouraging smoothness before upsampling the flow field, and continual self-supervision with image resizing. By combining the results of our investigation with our improved model components, we are able to present a new unsupervised flow technique that significantly outperforms the previous unsupervised state-of-the-art and performs on par with supervised FlowNet2 on the KITTI 2015 dataset, while also being significantly simpler than related approaches.
Differentiable Mapping Networks: Learning Structured Map Representations for Sparse Visual Localization
May 19, 2020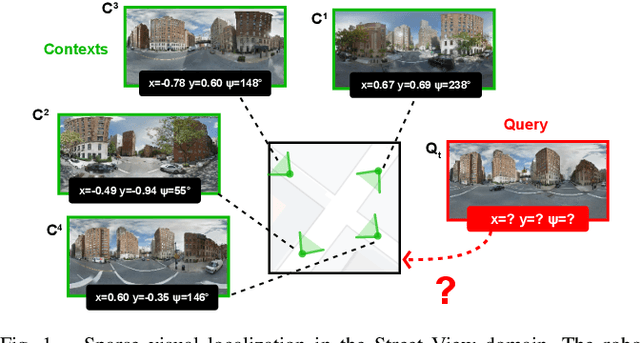
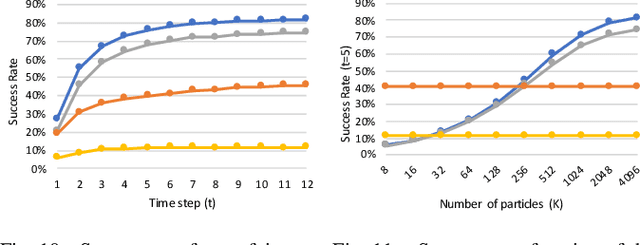
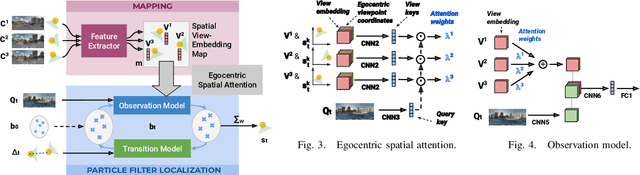
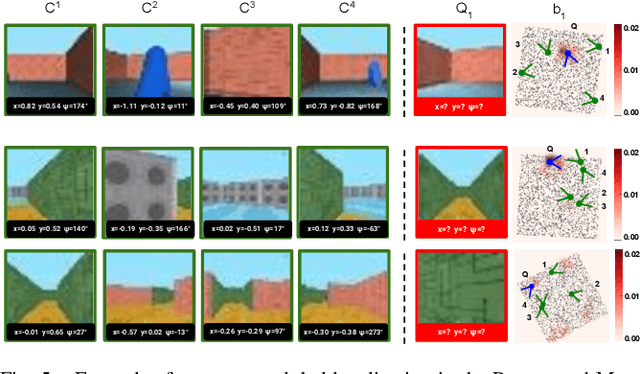
Mapping and localization, preferably from a small number of observations, are fundamental tasks in robotics. We address these tasks by combining spatial structure (differentiable mapping) and end-to-end learning in a novel neural network architecture: the Differentiable Mapping Network (DMN). The DMN constructs a spatially structured view-embedding map and uses it for subsequent visual localization with a particle filter. Since the DMN architecture is end-to-end differentiable, we can jointly learn the map representation and localization using gradient descent. We apply the DMN to sparse visual localization, where a robot needs to localize in a new environment with respect to a small number of images from known viewpoints. We evaluate the DMN using simulated environments and a challenging real-world Street View dataset. We find that the DMN learns effective map representations for visual localization. The benefit of spatial structure increases with larger environments, more viewpoints for mapping, and when training data is scarce. Project website: http://sites.google.com/view/differentiable-mapping
Towards Differentiable Resampling
Apr 24, 2020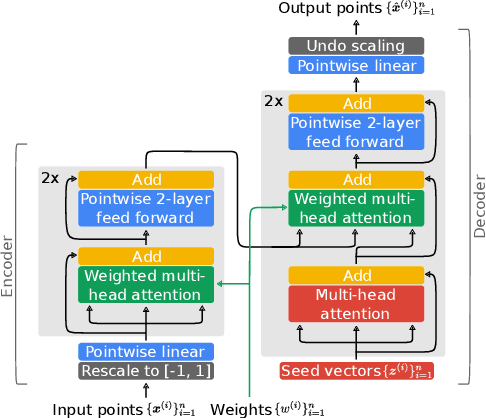
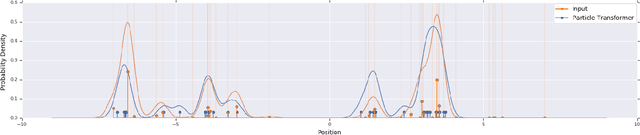
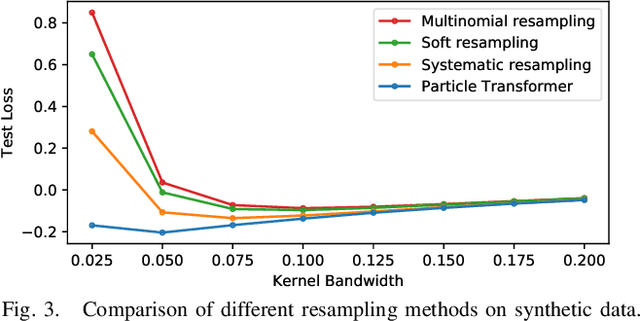
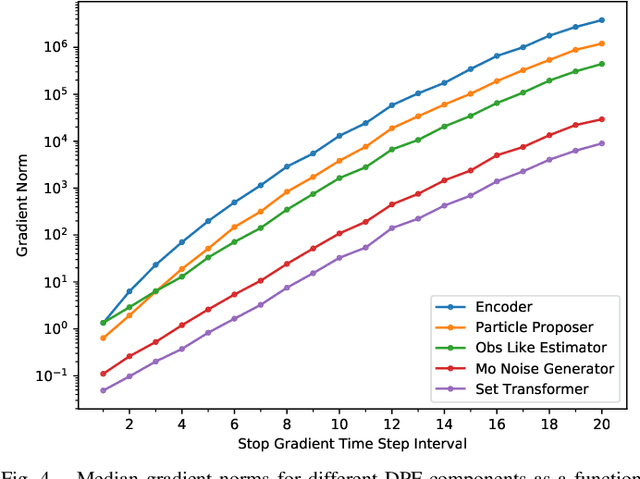
Resampling is a key component of sample-based recursive state estimation in particle filters. Recent work explores differentiable particle filters for end-to-end learning. However, resampling remains a challenge in these works, as it is inherently non-differentiable. We address this challenge by replacing traditional resampling with a learned neural network resampler. We present a novel network architecture, the particle transformer, and train it for particle resampling using a likelihood-based loss function over sets of particles. Incorporated into a differentiable particle filter, our model can be end-to-end optimized jointly with the other particle filter components via gradient descent. Our results show that our learned resampler outperforms traditional resampling techniques on synthetic data and in a simulated robot localization task.