 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoshiRAG: Asynchronous Knowledge Retrieval for Full-Duplex Speech Language Models
Apr 14, 2026Speech-to-speech language models have recently emerged to enhance the naturalness of conversational AI. In particular, full-duplex models are distinguished by their real-time interactivity, including handling of pauses, interruptions, and backchannels. However, improving their factuality remains an open challenge. While scaling the model size could address this gap, it would make real-time inference prohibitively expensive. In this work, we propose MoshiRAG, a modular approach that combines a compact full-duplex interface with selective retrieval to access more powerful knowledge sources. Our asynchronous framework enables the model to identify knowledge-demanding queries and ground its responses in external information. By leveraging the natural temporal gap between response onset and the delivery of core information, the retrieval process can be completed while maintaining a natural conversation flow. With this approach, MoshiRAG achieves factuality comparable to the best publicly released non-duplex speech language models while preserving the interactivity inherent to full-duplex systems. Moreover, our flexible design supports plug-and-play retrieval methods without retraining and demonstrates strong performance on out-of-domain mathematical reasoning tasks.
Streaming Sequence-to-Sequence Learning with Delayed Streams Modeling
Sep 10, 2025We introduce Delayed Streams Modeling (DSM), a flexible formulation for streaming, multimodal sequence-to-sequence learning. Sequence-to-sequence generation is often cast in an offline manner, where the model consumes the complete input sequence before generating the first output timestep. Alternatively, streaming sequence-to-sequence rely on learning a policy for choosing when to advance on the input stream, or write to the output stream. DSM instead models already time-aligned streams with a decoder-only language model. By moving the alignment to a pre-processing step,and introducing appropriate delays between streams, DSM provides streaming inference of arbitrary output sequences, from any input combination, making it applicable to many sequence-to-sequence problems. In particular, given text and audio streams, automatic speech recognition (ASR) corresponds to the text stream being delayed, while the opposite gives a text-to-speech (TTS) model. We perform extensive experiments for these two major sequence-to-sequence tasks, showing that DSM provides state-of-the-art performance and latency while supporting arbitrary long sequences, being even competitive with offline baselines. Code, samples and demos are available at https://github.com/kyutai-labs/delayed-streams-modeling
Continuous Audio Language Models
Sep 09, 2025Audio Language Models (ALM) have emerged as the dominant paradigm for speech and music generation by representing audio as sequences of discrete tokens. Yet, unlike text tokens, which are invertible, audio tokens are extracted from lossy codecs with a limited bitrate. As a consequence, increasing audio quality requires generating more tokens, which imposes a trade-off between fidelity and computational cost. We address this issue by studying Continuous Audio Language Models (CALM). These models instantiate a large Transformer backbone that produces a contextual embedding at every timestep. This sequential information then conditions an MLP that generates the next continuous frame of an audio VAE through consistency modeling. By avoiding lossy compression, CALM achieves higher quality at lower computational cost than their discrete counterpart. Experiments on speech and music demonstrate improved efficiency and fidelity over state-of-the-art discrete audio language models, facilitating lightweight, high-quality audio generation. Samples are available at hf.co/spaces/kyutai/calm-samples
Live Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
C3PO: Learning to Achieve Arbitrary Goals via Massively Entropic Pretraining
Nov 07, 2022



Given a particular embodiment, we propose a novel method (C3PO) that learns policies able to achieve any arbitrary position and pose. Such a policy would allow for easier control, and would be re-useable as a key building block for downstream tasks. The method is two-fold: First, we introduce a novel exploration algorithm that optimizes for uniform coverage, is able to discover a set of achievable states, and investigates its abilities in attaining both high coverage, and hard-to-discover states; Second, we leverage this set of achievable states as training data for a universal goal-achievement policy, a goal-based SAC variant. We demonstrate the trained policy's performance in achieving a large number of novel states. Finally, we showcase the influence of massive unsupervised training of a goal-achievement policy with state-of-the-art pose-based control of the Hopper, Walker, Halfcheetah, Humanoid and Ant embodiments.
What Matters for Adversarial Imitation Learning?
Jun 01, 2021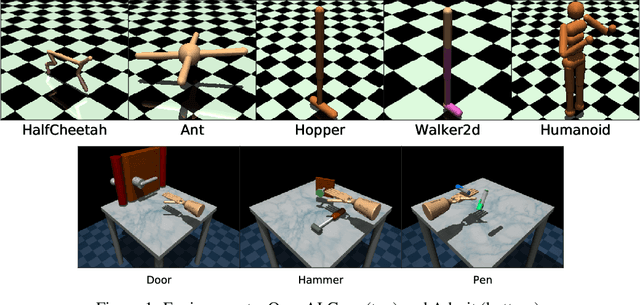

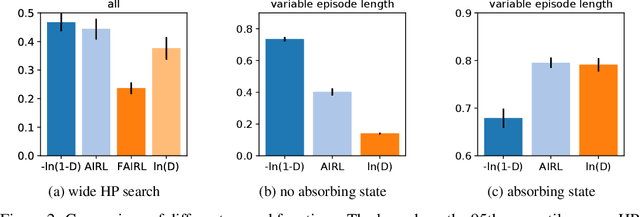

Adversarial imitation learning has become a popular framework for imitation in continuous control. Over the years, several variations of its components were proposed to enhance the performance of the learned policies as well as the sample complexity of the algorithm. In practice, these choices are rarely tested all together in rigorous empirical studies. It is therefore difficult to discuss and understand what choices, among the high-level algorithmic options as well as low-level implementation details, matter. To tackle this issue, we implement more than 50 of these choices in a generic adversarial imitation learning framework and investigate their impacts in a large-scale study (>500k trained agents) with both synthetic and human-generated demonstrations. While many of our findings confirm common practices, some of them are surprising or even contradict prior work. In particular, our results suggest that artificial demonstrations are not a good proxy for human data and that the very common practice of evaluating imitation algorithms only with synthetic demonstrations may lead to algorithms which perform poorly in the more realistic scenarios with human demonstrations.
Hyperparameter Selection for Imitation Learning
May 25, 2021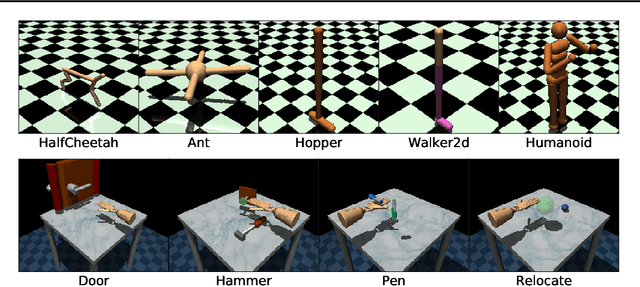
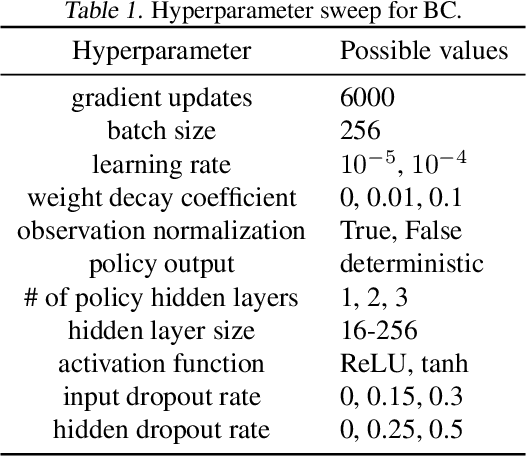
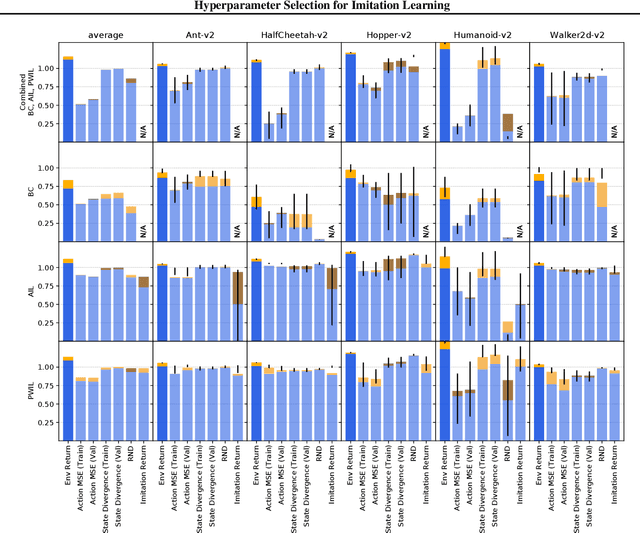
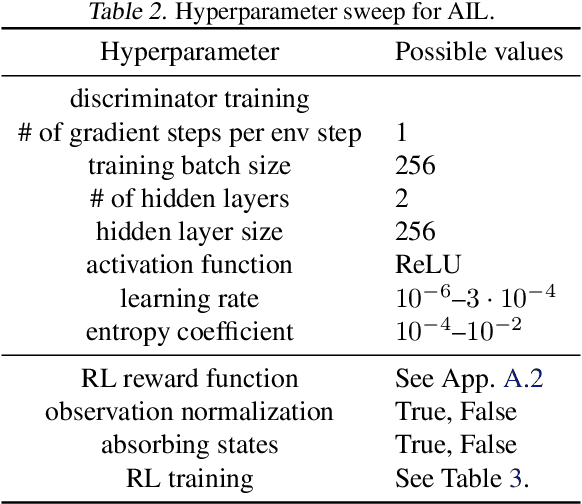
We address the issue of tuning hyperparameters (HPs) for imitation learning algorithms in the context of continuous-control, when the underlying reward function of the demonstrating expert cannot be observed at any time. The vast literature in imitation learning mostly considers this reward function to be available for HP selection, but this is not a realistic setting. Indeed, would this reward function be available, it could then directly be used for policy training and imitation would not be necessary. To tackle this mostly ignored problem, we propose a number of possible proxies to the external reward. We evaluate them in an extensive empirical study (more than 10'000 agents across 9 environments) and make practical recommendations for selecting HPs. Our results show that while imitation learning algorithms are sensitive to HP choices, it is often possible to select good enough HPs through a proxy to the reward function.
What Matters In On-Policy Reinforcement Learning? A Large-Scale Empirical Study
Jun 10, 2020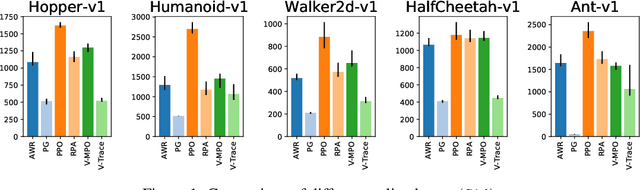

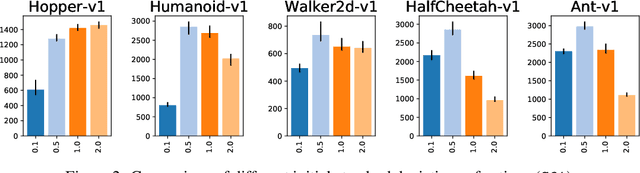

In recent years, on-policy reinforcement learning (RL) has been successfully applied to many different continuous control tasks. While RL algorithms are often conceptually simple, their state-of-the-art implementations take numerous low- and high-level design decisions that strongly affect the performance of the resulting agents. Those choices are usually not extensively discussed in the literature, leading to discrepancy between published descriptions of algorithms and their implementations. This makes it hard to attribute progress in RL and slows down overall progress [Engstrom'20]. As a step towards filling that gap, we implement >50 such ``choices'' in a unified on-policy RL framework, allowing us to investigate their impact in a large-scale empirical study. We train over 250'000 agents in five continuous control environments of different complexity and provide insights and practical recommendations for on-policy training of RL agents.