 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Neural Network Decoupling
Jun 04, 2019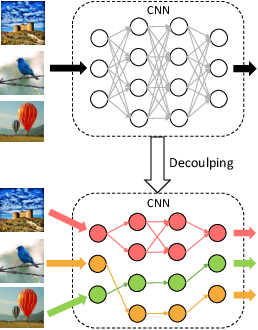
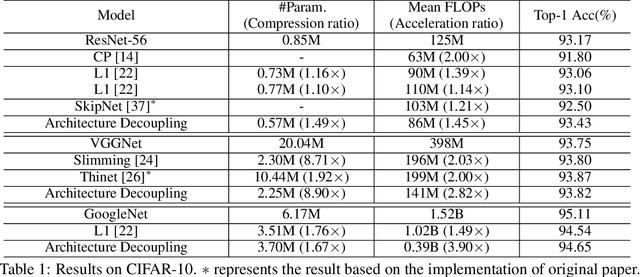
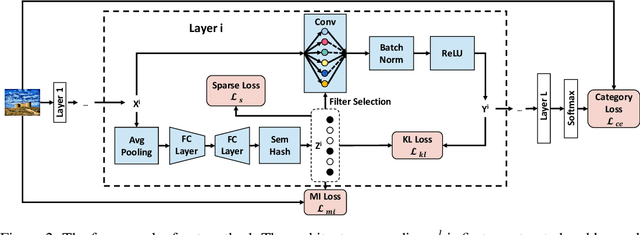
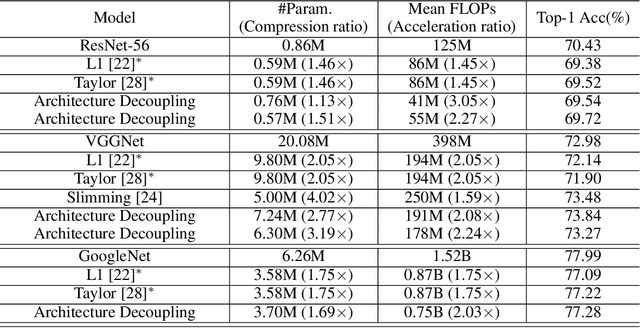
Convolutional neural networks (CNNs) have achieved a superior performance by taking advantages of the complex network architectures and huge numbers of parameters, which however become uninterpretable and challenge their full potential to practical applications. Towards better understand the rationale behind the network decisions, we propose a novel architecture decoupling method, which dynamically discovers the hierarchical path consisting of activated filters for each input image. In particular, architecture controlling module is introduced in each layer to encode the network architecture and identify the activated filters corresponding to the specific input. Then, mutual information between architecture encoding and the attribute of input image is maximized to decouple the network architecture, and subsequently disentangles the filters by limiting the outputs of filter during training. Extensive experiments show that several merits have been achieved based on the proposed architecture decoupling, i.e., interpretation, acceleration and adversarial attacking.
Supervised Online Hashing via Similarity Distribution Learning
May 31, 2019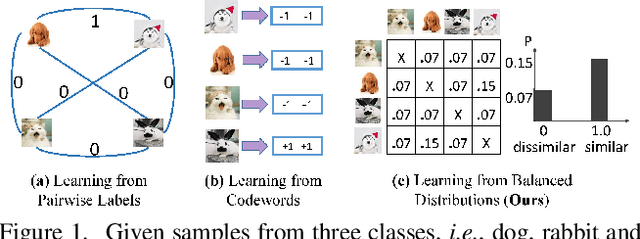
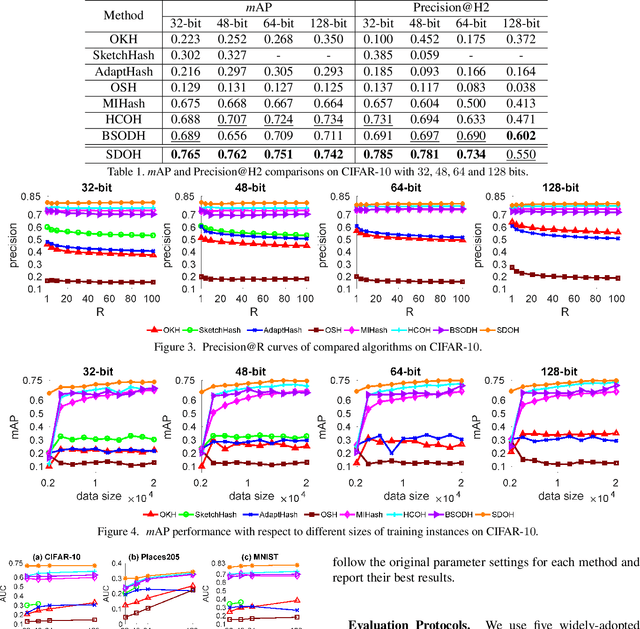
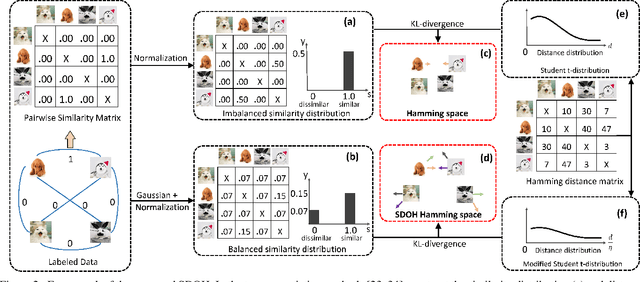
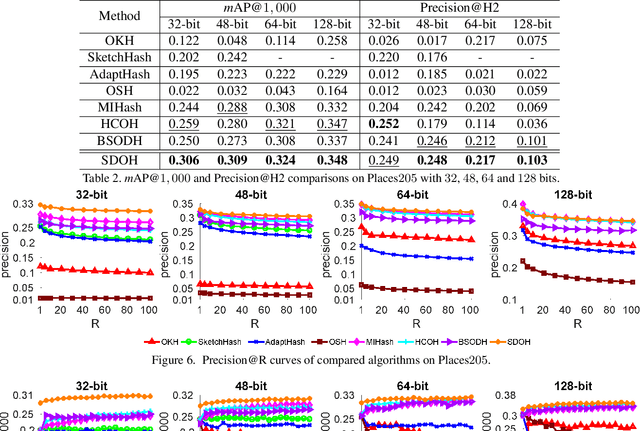
Online hashing has attracted extensive research attention when facing streaming data. Most online hashing methods, learning binary codes based on pairwise similarities of training instances, fail to capture the semantic relationship, and suffer from a poor generalization in large-scale applications due to large variations. In this paper, we propose to model the similarity distributions between the input data and the hashing codes, upon which a novel supervised online hashing method, dubbed as Similarity Distribution based Online Hashing (SDOH), is proposed, to keep the intrinsic semantic relationship in the produced Hamming space. Specifically, we first transform the discrete similarity matrix into a probability matrix via a Gaussian-based normalization to address the extremely imbalanced distribution issue. And then, we introduce a scaling Student t-distribution to solve the challenging initialization problem, and efficiently bridge the gap between the known and unknown distributions. Lastly, we align the two distributions via minimizing the Kullback-Leibler divergence (KL-diverence) with stochastic gradient descent (SGD), by which an intuitive similarity constraint is imposed to update hashing model on the new streaming data with a powerful generalizing ability to the past data. Extensive experiments on three widely-used benchmarks validate the superiority of the proposed SDOH over the state-of-the-art methods in the online retrieval task.
Anti-Confusing: Region-Aware Network for Human Pose Estimation
May 27, 2019
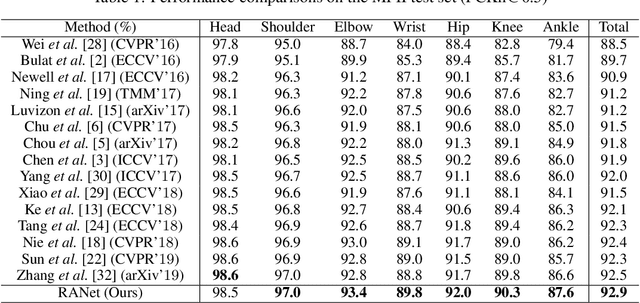
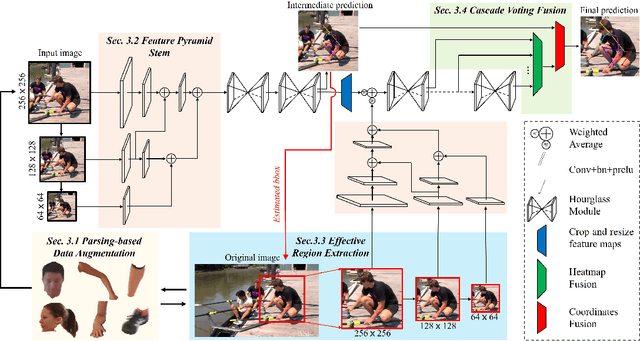
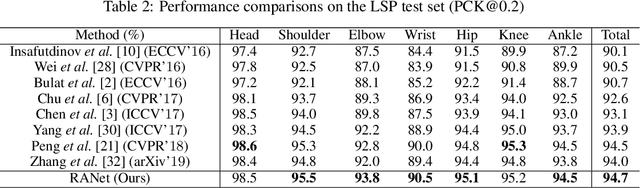
In this work, we propose a novel framework named Region-Aware Network (RANet), which learns the ability of anti-confusing in case of heavy occlusion, nearby person and symmetric appearance, for human pose estimation. Specifically, the proposed method addresses three key aspects, i.e., data augmentation, feature learning and prediction fusion, respectively. First, we propose Parsing-based Data Augmentation (PDA) to generate abundant data that synthesizes confusing textures. Second, we not only propose a Feature Pyramid Stem (FPS) to learn stronger low-level features in lower stage; but also incorporate an Effective Region Extraction (ERE) module to excavate better target-specific features. Third, we introduce Cascade Voting Fusion (CVF) to explicitly exclude the inferior predictions and fuse the rest effective predictions for the final pose estimation. Extensive experimental results on two popular benchmarks, i.e. MPII and LSP, demonstrate the effectiveness of our method against the state-of-the-art competitors. Especially on easily-confusable joints, our method makes significant improvement.
LGM-Net: Learning to Generate Matching Networks for Few-Shot Learning
May 15, 2019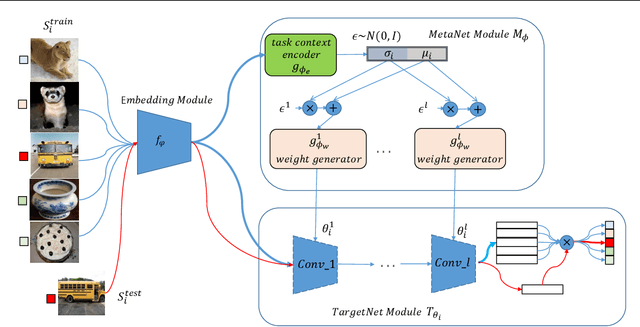
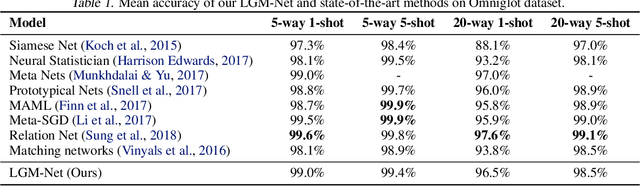
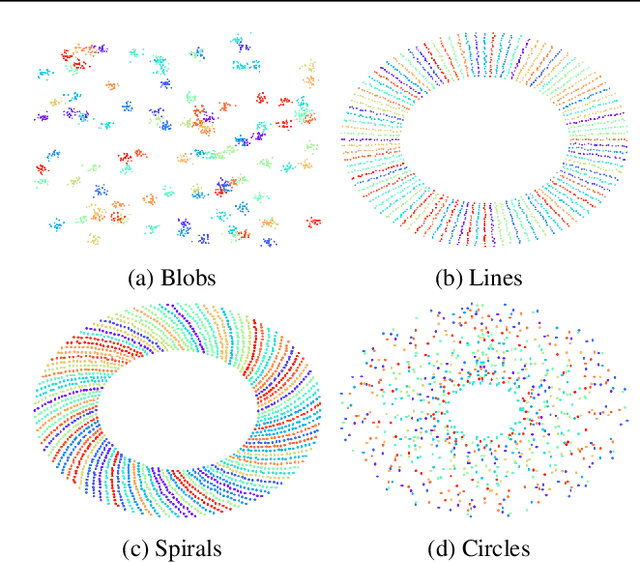
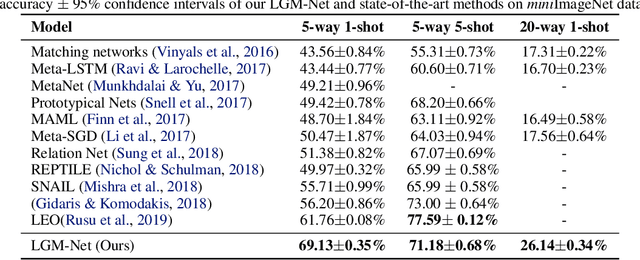
In this work, we propose a novel meta-learning approach for few-shot classification, which learns transferable prior knowledge across tasks and directly produces network parameters for similar unseen tasks with training samples. Our approach, called LGM-Net, includes two key modules, namely, TargetNet and MetaNet. The TargetNet module is a neural network for solving a specific task and the MetaNet module aims at learning to generate functional weights for TargetNet by observing training samples. We also present an intertask normalization strategy for the training process to leverage common information shared across different tasks. The experimental results on Omniglot and miniImageNet datasets demonstrate that LGM-Net can effectively adapt to similar unseen tasks and achieve competitive performance, and the results on synthetic datasets show that transferable prior knowledge is learned by the MetaNet module via mapping training data to functional weights. LGM-Net enables fast learning and adaptation since no further tuning steps are required compared to other meta-learning approaches.
Towards Optimal Structured CNN Pruning via Generative Adversarial Learning
Mar 22, 2019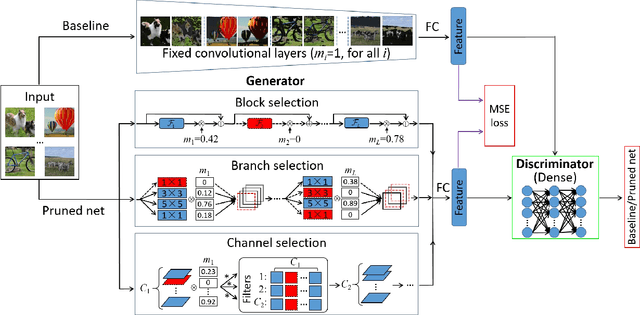
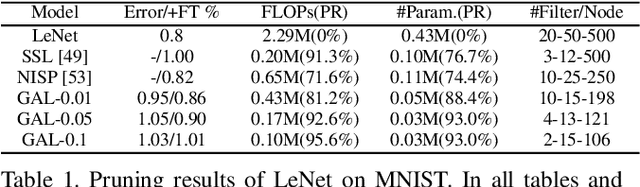
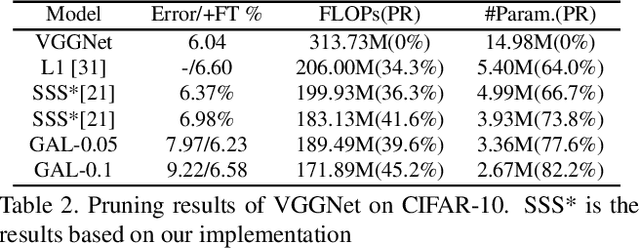
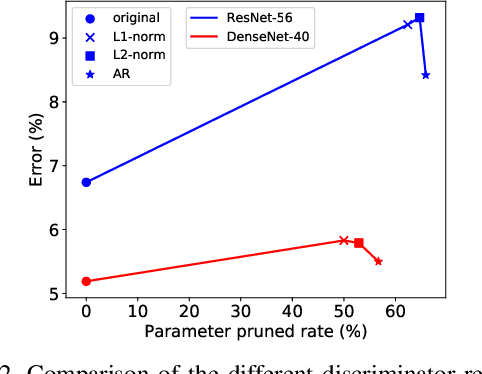
Structured pruning of filters or neurons has received increased focus for compressing convolutional neural networks. Most existing methods rely on multi-stage optimizations in a layer-wise manner for iteratively pruning and retraining which may not be optimal and may be computation intensive. Besides, these methods are designed for pruning a specific structure, such as filter or block structures without jointly pruning heterogeneous structures. In this paper, we propose an effective structured pruning approach that jointly prunes filters as well as other structures in an end-to-end manner. To accomplish this, we first introduce a soft mask to scale the output of these structures by defining a new objective function with sparsity regularization to align the output of baseline and network with this mask. We then effectively solve the optimization problem by generative adversarial learning (GAL), which learns a sparse soft mask in a label-free and an end-to-end manner. By forcing more scaling factors in the soft mask to zero, the fast iterative shrinkage-thresholding algorithm (FISTA) can be leveraged to fast and reliably remove the corresponding structures. Extensive experiments demonstrate the effectiveness of GAL on different datasets, including MNIST, CIFAR-10 and ImageNet ILSVRC 2012. For example, on ImageNet ILSVRC 2012, the pruned ResNet-50 achieves 10.88\% Top-5 error and results in a factor of 3.7x speedup. This significantly outperforms state-of-the-art methods.
Aurora Guard: Real-Time Face Anti-Spoofing via Light Reflection
Feb 27, 2019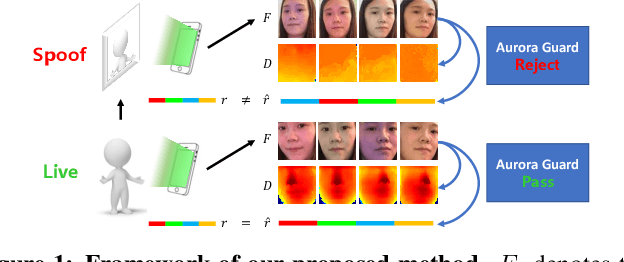
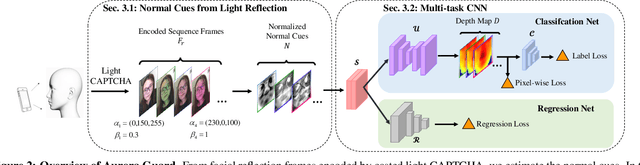
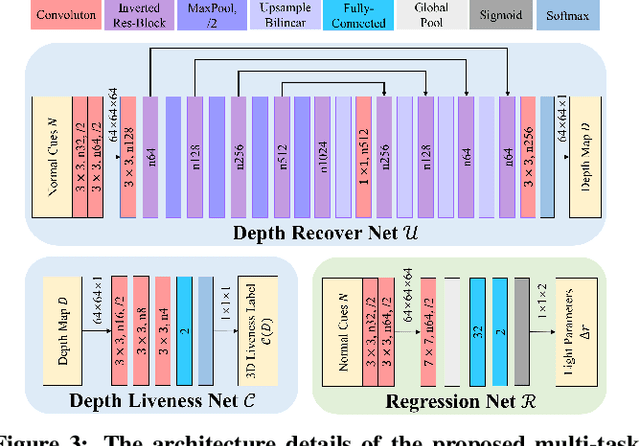
In this paper, we propose a light reflection based face anti-spoofing method named Aurora Guard (AG), which is fast, simple yet effective that has already been deployed in real-world systems serving for millions of users. Specifically, our method first extracts the normal cues via light reflection analysis, and then uses an end-to-end trainable multi-task Convolutional Neural Network (CNN) to not only recover subjects' depth maps to assist liveness classification, but also provide the light CAPTCHA checking mechanism in the regression branch to further improve the system reliability. Moreover, we further collect a large-scale dataset containing $12,000$ live and spoofing samples, which covers abundant imaging qualities and Presentation Attack Instruments (PAI). Extensive experiments on both public and our datasets demonstrate the superiority of our proposed method over the state of the arts.
Exploiting Kernel Sparsity and Entropy for Interpretable CNN Compression
Dec 11, 2018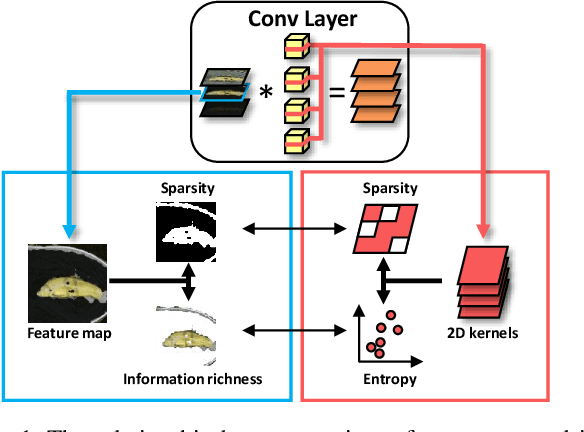
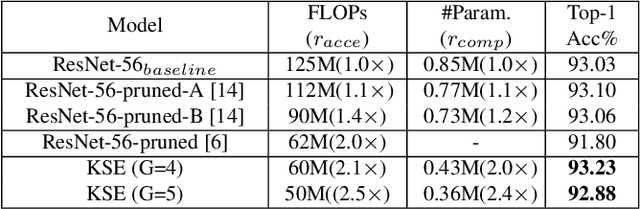
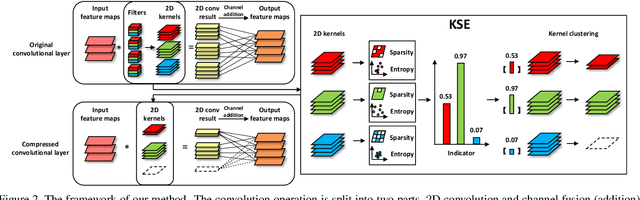
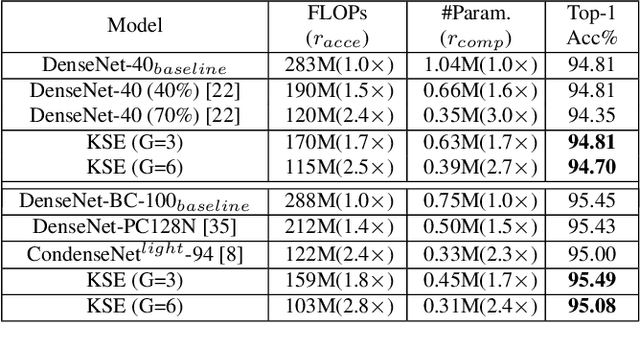
Compressing convolutional neural networks (CNNs) has received ever-increasing research focus. However, most existing CNN compression methods do not interpret their inherent structures to distinguish the implicit redundancy. In this paper, we investigate the problem of CNN compression from a novel interpretable perspective. The relationship between the input feature maps and 2D kernels is revealed in a theoretical framework, based on which a kernel sparsity and entropy (KSE) indicator is proposed to quantitate the feature map importance in a feature-agnostic manner to guide model compression. Kernel clustering is further conducted based on the KSE indicator to accomplish high-precision CNN compression. KSE is capable of simultaneously compressing each layer in an efficient way, which is significantly faster compared to previous data-driven feature map pruning methods. We comprehensively evaluate the compression and speedup of the proposed method on CIFAR-10, SVHN and ImageNet 2012. Our method demonstrates superior performance gains over previous ones. In particular, it achieves 4.7 \times FLOPs reduction and 2.9 \times compression on ResNet-50 with only a Top-5 accuracy drop of 0.35% on ImageNet 2012, which significantly outperforms state-of-the-art methods.
Towards Highly Accurate and Stable Face Alignment for High-Resolution Videos
Nov 01, 2018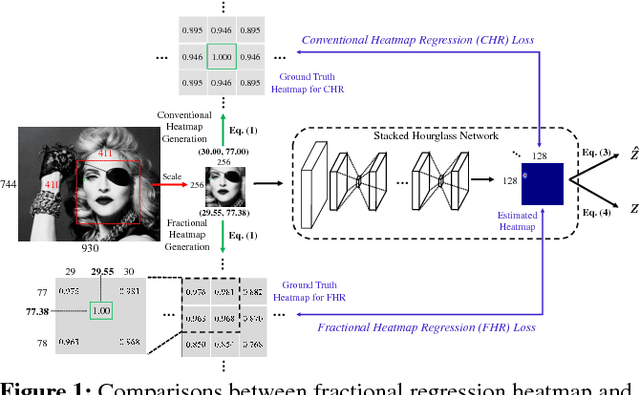
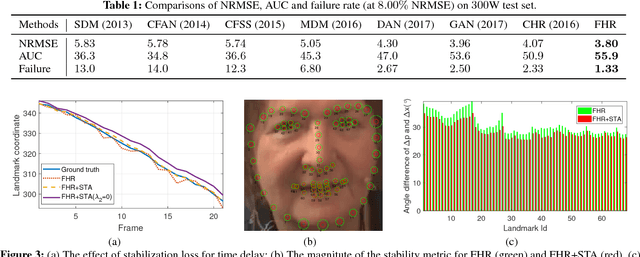
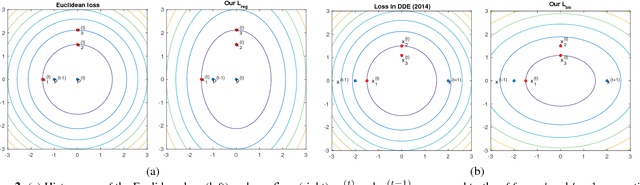
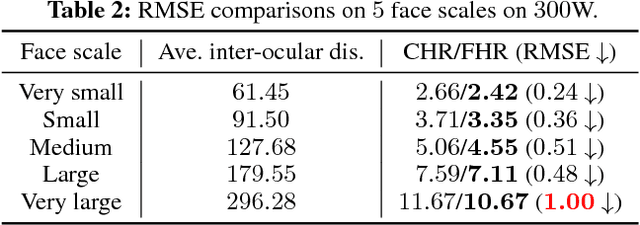
In recent years, heatmap regression based models have shown their effectiveness in face alignment and pose estimation. However, Conventional Heatmap Regression (CHR) is not accurate nor stable when dealing with high-resolution facial videos, since it finds the maximum activated location in heatmaps which are generated from rounding coordinates, and thus leads to quantization errors when scaling back to the original high-resolution space. In this paper, we propose a Fractional Heatmap Regression (FHR) for high-resolution video-based face alignment. The proposed FHR can accurately estimate the fractional part according to the 2D Gaussian function by sampling three points in heatmaps. To further stabilize the landmarks among continuous video frames while maintaining the precise at the same time, we propose a novel stabilization loss that contains two terms to address time delay and non-smooth issues, respectively. Experiments on 300W, 300-VW and Talking Face datasets clearly demonstrate that the proposed method is more accurate and stable than the state-of-the-art models.
A Coarse-to-fine Pyramidal Model for Person Re-identification via Multi-Loss Dynamic Training
Oct 30, 2018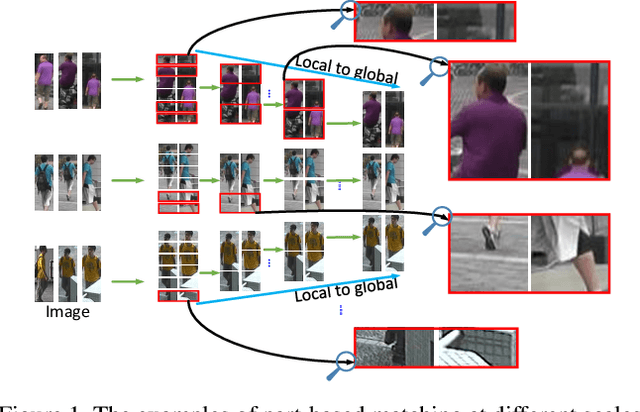
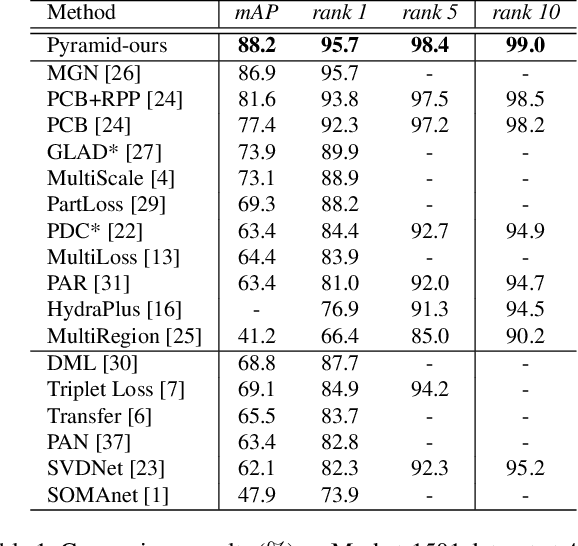
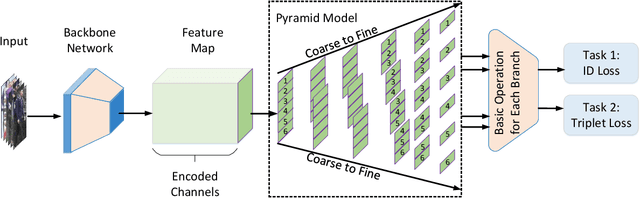
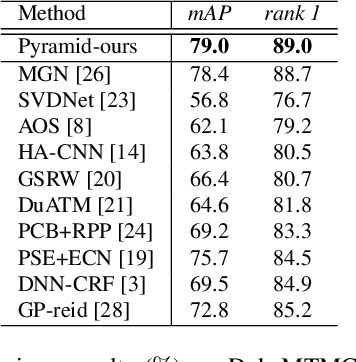
Most existing Re-IDentification (Re-ID) methods are highly dependent on precise bounding boxes that enable images to be aligned with each other. However, due to the inevitable challenging scenarios, current detection models often output inaccurate bounding boxes yet, which inevitably worsen the performance of these Re-ID algorithms. In this paper, to relax the requirement, we propose a novel coarse-to-fine pyramid model that not only incorporates local and global information, but also integrates the gradual cues between them. The pyramid model is able to match the cues at different scales and then search for the correct image of the same identity even when the image pair are not aligned. In addition, in order to learn discriminative identity representation, we explore a dynamic training scheme to seamlessly unify two losses and extract appropriate shared information between them. Experimental results clearly demonstrate that the proposed method achieves the state-of-the-art results on three datasets and it is worth noting that our approach exceeds the current best method by 9.5% on the most challenging dataset CUHK03.
DSFD: Dual Shot Face Detector
Oct 24, 2018
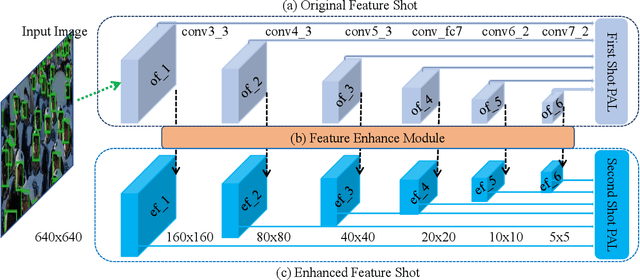

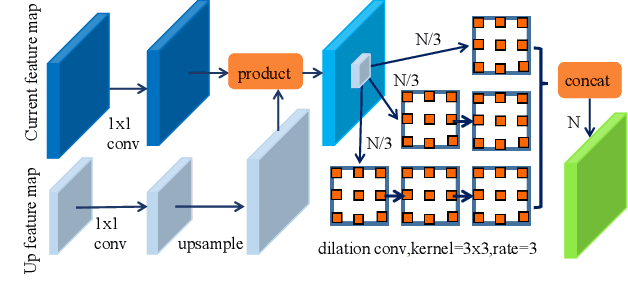
Recently, Convolutional Neural Network (CNN) has achieved great success in face detection. However, it remains a challenging problem for the current face detection methods owing to high degree of variability in scale, pose, occlusion, expression, appearance and illumination. In this paper, we propose a novel face detection network named Dual Shot face Detector(DSFD), which inherits the architecture of SSD and introduces a Feature Enhance Module (FEM) for transferring the original feature maps to extend the single shot detector to dual shot detector. Specially, Progressive Anchor Loss (PAL) computed by using two set of anchors is adopted to effectively facilitate the features. Additionally, we propose an Improved Anchor Matching (IAM) method by integrating novel data augmentation techniques and anchor design strategy in our DSFD to provide better initialization for the regressor. Extensive experiments on popular benchmarks: WIDER FACE (easy: $0.966$, medium: $0.957$, hard: $0.904$) and FDDB ( discontinuous: $0.991$, continuous: $0.862$) demonstrate the superiority of DSFD over the state-of-the-art face detectors (e.g., PyramidBox and SRN). Code will be made available upon publication.