 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledgeable-r1: Policy Optimization for Knowledge Exploration in Retrieval-Augmented Generation
Jun 05, 2025

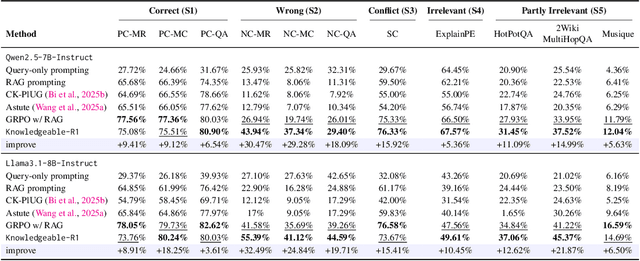

Retrieval-augmented generation (RAG) is a mainstream method for improving performance on knowledge-intensive tasks. However,current RAG systems often place too much emphasis on retrieved contexts. This can lead to reliance on inaccurate sources and overlook the model's inherent knowledge, especially when dealing with misleading or excessive information. To resolve this imbalance, we propose Knowledgeable-r1 that using joint sampling and define multi policy distributions in knowledge capability exploration to stimulate large language models'self-integrated utilization of parametric and contextual knowledge. Experiments show that Knowledgeable-r1 significantly enhances robustness and reasoning accuracy in both parameters and contextual conflict tasks and general RAG tasks, especially outperforming baselines by 17.07% in counterfactual scenarios and demonstrating consistent gains across RAG tasks. Our code are available at https://github.com/lcy80366872/ knowledgeable-r1.
Detecting Stealthy Backdoor Samples based on Intra-class Distance for Large Language Models
May 29, 2025



Fine-tuning LLMs with datasets containing stealthy backdoors from publishers poses security risks to downstream applications. Mainstream detection methods either identify poisoned samples by analyzing the prediction probability of poisoned classification models or rely on the rewriting model to eliminate the stealthy triggers. However, the former cannot be applied to generation tasks, while the latter may degrade generation performance and introduce new triggers. Therefore, efficiently eliminating stealthy poisoned samples for LLMs remains an urgent problem. We observe that after applying TF-IDF clustering to the sample response, there are notable differences in the intra-class distances between clean and poisoned samples. Poisoned samples tend to cluster closely because of their specific malicious outputs, whereas clean samples are more scattered due to their more varied responses. Thus, in this paper, we propose a stealthy backdoor sample detection method based on Reference-Filtration and Tfidf-Clustering mechanisms (RFTC). Specifically, we first compare the sample response with the reference model's outputs and consider the sample suspicious if there's a significant discrepancy. And then we perform TF-IDF clustering on these suspicious samples to identify the true poisoned samples based on the intra-class distance. Experiments on two machine translation datasets and one QA dataset demonstrate that RFTC outperforms baselines in backdoor detection and model performance. Further analysis of different reference models also confirms the effectiveness of our Reference-Filtration.
Too Consistent to Detect: A Study of Self-Consistent Errors in LLMs
May 23, 2025As large language models (LLMs) often generate plausible but incorrect content, error detection has become increasingly critical to ensure truthfulness. However, existing detection methods often overlook a critical problem we term as self-consistent error, where LLMs repeatly generate the same incorrect response across multiple stochastic samples. This work formally defines self-consistent errors and evaluates mainstream detection methods on them. Our investigation reveals two key findings: (1) Unlike inconsistent errors, whose frequency diminishes significantly as LLM scale increases, the frequency of self-consistent errors remains stable or even increases. (2) All four types of detection methshods significantly struggle to detect self-consistent errors. These findings reveal critical limitations in current detection methods and underscore the need for improved methods. Motivated by the observation that self-consistent errors often differ across LLMs, we propose a simple but effective cross-model probe method that fuses hidden state evidence from an external verifier LLM. Our method significantly enhances performance on self-consistent errors across three LLM families.
Reinforced Lifelong Editing for Language Models
Feb 09, 2025Large language models (LLMs) acquire information from pre-training corpora, but their stored knowledge can become inaccurate or outdated over time. Model editing addresses this challenge by modifying model parameters without retraining, and prevalent approaches leverage hypernetworks to generate these parameter updates. However, they face significant challenges in lifelong editing due to their incompatibility with LLM parameters that dynamically change during the editing process. To address this, we observed that hypernetwork-based lifelong editing aligns with reinforcement learning modeling and proposed RLEdit, an RL-based editing method. By treating editing losses as rewards and optimizing hypernetwork parameters at the full knowledge sequence level, we enable it to precisely capture LLM changes and generate appropriate parameter updates. Our extensive empirical evaluation across several LLMs demonstrates that RLEdit outperforms existing methods in lifelong editing with superior effectiveness and efficiency, achieving a 59.24% improvement while requiring only 2.11% of the time compared to most approaches. Our code is available at: https://github.com/zhrli324/RLEdit.
The 1st Workshop on Human-Centered Recommender Systems
Nov 22, 2024
Recommender systems are quintessential applications of human-computer interaction. Widely utilized in daily life, they offer significant convenience but also present numerous challenges, such as the information cocoon effect, privacy concerns, fairness issues, and more. Consequently, this workshop aims to provide a platform for researchers to explore the development of Human-Centered Recommender Systems~(HCRS). HCRS refers to the creation of recommender systems that prioritize human needs, values, and capabilities at the core of their design and operation. In this workshop, topics will include, but are not limited to, robustness, privacy, transparency, fairness, diversity, accountability, ethical considerations, and user-friendly design. We hope to engage in discussions on how to implement and enhance these properties in recommender systems. Additionally, participants will explore diverse evaluation methods, including innovative metrics that capture user satisfaction and trust. This workshop seeks to foster a collaborative environment for researchers to share insights and advance the field toward more ethical, user-centric, and socially responsible recommender systems.
Fact-Level Confidence Calibration and Self-Correction
Nov 20, 2024



Confidence calibration in LLMs, i.e., aligning their self-assessed confidence with the actual accuracy of their responses, enabling them to self-evaluate the correctness of their outputs. However, current calibration methods for LLMs typically estimate two scalars to represent overall response confidence and correctness, which is inadequate for long-form generation where the response includes multiple atomic facts and may be partially confident and correct. These methods also overlook the relevance of each fact to the query. To address these challenges, we propose a Fact-Level Calibration framework that operates at a finer granularity, calibrating confidence to relevance-weighted correctness at the fact level. Furthermore, comprehensive analysis under the framework inspired the development of Confidence-Guided Fact-level Self-Correction ($\textbf{ConFix}$), which uses high-confidence facts within a response as additional knowledge to improve low-confidence ones. Extensive experiments across four datasets and six models demonstrate that ConFix effectively mitigates hallucinations without requiring external knowledge sources such as retrieval systems.
Game-theoretic LLM: Agent Workflow for Negotiation Games
Nov 12, 2024



This paper investigates the rationality of large language models (LLMs) in strategic decision-making contexts, specifically within the framework of game theory. We evaluate several state-of-the-art LLMs across a spectrum of complete-information and incomplete-information games. Our findings reveal that LLMs frequently deviate from rational strategies, particularly as the complexity of the game increases with larger payoff matrices or deeper sequential trees. To address these limitations, we design multiple game-theoretic workflows that guide the reasoning and decision-making processes of LLMs. These workflows aim to enhance the models' ability to compute Nash Equilibria and make rational choices, even under conditions of uncertainty and incomplete information. Experimental results demonstrate that the adoption of these workflows significantly improves the rationality and robustness of LLMs in game-theoretic tasks. Specifically, with the workflow, LLMs exhibit marked improvements in identifying optimal strategies, achieving near-optimal allocations in negotiation scenarios, and reducing susceptibility to exploitation during negotiations. Furthermore, we explore the meta-strategic considerations of whether it is rational for agents to adopt such workflows, recognizing that the decision to use or forgo the workflow constitutes a game-theoretic issue in itself. Our research contributes to a deeper understanding of LLMs' decision-making capabilities in strategic contexts and provides insights into enhancing their rationality through structured workflows. The findings have implications for the development of more robust and strategically sound AI agents capable of navigating complex interactive environments. Code and data supporting this study are available at \url{https://github.com/Wenyueh/game_theory}.
KAN-AD: Time Series Anomaly Detection with Kolmogorov-Arnold Networks
Nov 01, 2024



Time series anomaly detection (TSAD) has become an essential component of large-scale cloud services and web systems because it can promptly identify anomalies, providing early warnings to prevent greater losses. Deep learning-based forecasting methods have become very popular in TSAD due to their powerful learning capabilities. However, accurate predictions don't necessarily lead to better anomaly detection. Due to the common occurrence of noise, i.e., local peaks and drops in time series, existing black-box learning methods can easily learn these unintended patterns, significantly affecting anomaly detection performance. Kolmogorov-Arnold Networks (KAN) offers a potential solution by decomposing complex temporal sequences into a combination of multiple univariate functions, making the training process more controllable. However, KAN optimizes univariate functions using spline functions, which are also susceptible to the influence of local anomalies. To address this issue, we present KAN-AD, which leverages the Fourier series to emphasize global temporal patterns, thereby mitigating the influence of local peaks and drops. KAN-AD improves both effectiveness and efficiency by transforming the existing black-box learning approach into learning the weights preceding univariate functions. Experimental results show that, compared to the current state-of-the-art, we achieved an accuracy increase of 15% while boosting inference speed by 55 times.
Pruning Foundation Models for High Accuracy without Retraining
Oct 21, 2024


Despite the superior performance, it is challenging to deploy foundation models or large language models (LLMs) due to their massive parameters and computations. While pruning is a promising technique to reduce model size and accelerate the inference, the traditional pruning techniques can hardly be applied for LLMs as they need to finetune the model on the full dataset with multiple epochs consuming massive data and hardware resources. To deal with this problem, post-training pruning methods are proposed to prune LLMs in one-shot without retraining. However, their accuracy after pruning may suffer from certain performance degradation due to the lack of retraining with massive data. To address this issue, in this paper, we first formulate the post-training problem for layer-wise LLM compression to simultaneously prune multiple weights in LLMs. Next, we provide an optimal solution for this problem and design our post-training pruning algorithm for both unstructured and semi-structured sparsity. Our extensive experiments demonstrate the superior performance of the proposed methods in comparison to SOTA baselines across various LLM families including transformer-based LLMs and Mamba-based LLMs. Code link: https://github.com/piuzha/APT
MITA: Bridging the Gap between Model and Data for Test-time Adaptation
Oct 12, 2024



Test-Time Adaptation (TTA) has emerged as a promising paradigm for enhancing the generalizability of models. However, existing mainstream TTA methods, predominantly operating at batch level, often exhibit suboptimal performance in complex real-world scenarios, particularly when confronting outliers or mixed distributions. This phenomenon stems from a pronounced over-reliance on statistical patterns over the distinct characteristics of individual instances, resulting in a divergence between the distribution captured by the model and data characteristics. To address this challenge, we propose Meet-In-The-Middle based Test-Time Adaptation ($\textbf{MITA}$), which introduces energy-based optimization to encourage mutual adaptation of the model and data from opposing directions, thereby meeting in the middle. MITA pioneers a significant departure from traditional approaches that focus solely on aligning the model to the data, facilitating a more effective bridging of the gap between model's distribution and data characteristics. Comprehensive experiments with MITA across three distinct scenarios (Outlier, Mixture, and Pure) demonstrate its superior performance over SOTA methods, highlighting its potential to significantly enhance generalizability in practical applications.