 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHINTBench: Horizon-agent Intrinsic Non-attack Trajectory Benchmark
Apr 15, 2026Existing agent-safety evaluation has focused mainly on externally induced risks. Yet agents may still enter unsafe trajectories under benign conditions. We study this complementary but underexplored setting through the lens of \emph{intrinsic} risk, where intrinsic failures remain latent, propagate across long-horizon execution, and eventually lead to high-consequence outcomes. To evaluate this setting, we introduce \emph{non-attack intrinsic risk auditing} and present \textbf{HINTBench}, a benchmark of 629 agent trajectories (523 risky, 106 safe; 33 steps on average) supporting three tasks: risk detection, risk-step localization, and intrinsic failure-type identification. Its annotations are organized under a unified five-constraint taxonomy. Experiments reveal a substantial capability gap: strong LLMs perform well on trajectory-level risk detection, but their performance drops to below 35 Strict-F1 on risk-step localization, while fine-grained failure diagnosis proves even harder. Existing guard models transfer poorly to this setting. These findings establish intrinsic risk auditing as an open challenge for agent safety.
Safety-Utility Conflicts Are Not Global: Surgical Alignment via Head-Level Diagnosis
Jan 07, 2026Safety alignment in Large Language Models (LLMs) inherently presents a multi-objective optimization conflict, often accompanied by an unintended degradation of general capabilities. Existing mitigation strategies typically rely on global gradient geometry to resolve these conflicts, yet they overlook Modular Heterogeneity within Transformers, specifically that the functional sensitivity and degree of conflict vary substantially across different attention heads. Such global approaches impose uniform update rules across all parameters, often resulting in suboptimal trade-offs by indiscriminately updating utility sensitive heads that exhibit intense gradient conflicts. To address this limitation, we propose Conflict-Aware Sparse Tuning (CAST), a framework that integrates head-level diagnosis with sparse fine-tuning. CAST first constructs a pre-alignment conflict map by synthesizing Optimization Conflict and Functional Sensitivity, which then guides the selective update of parameters. Experiments reveal that alignment conflicts in LLMs are not uniformly distributed. We find that the drop in general capabilities mainly comes from updating a small group of ``high-conflict'' heads. By simply skipping these heads during training, we significantly reduce this loss without compromising safety, offering an interpretable and parameter-efficient approach to improving the safety-utility trade-off.
Token-Level Policy Optimization: Linking Group-Level Rewards to Token-Level Aggregation via Markov Likelihood
Oct 10, 2025



Group Relative Policy Optimization (GRPO) has significantly advanced the reasoning ability of large language models (LLMs), particularly by boosting their mathematical performance. However, GRPO and related entropy-regularization methods still face challenges rooted in the sparse token rewards inherent to chain-of-thought (CoT). Current approaches often rely on undifferentiated token-level entropy adjustments, which frequently lead to entropy collapse or model collapse. In this work, we propose TEPO, a novel token-level framework that incorporates Markov Likelihood (sequence likelihood) links group-level rewards with tokens via token-level aggregation. Experiments show that TEPO consistently outperforms existing baselines across key metrics (including @k and accuracy). It not only sets a new state of the art on mathematical reasoning tasks but also significantly enhances training stability.
Knowledgeable-r1: Policy Optimization for Knowledge Exploration in Retrieval-Augmented Generation
Jun 05, 2025

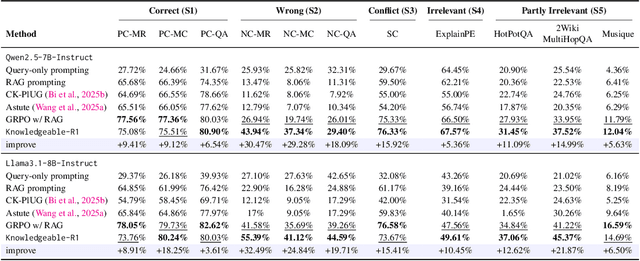

Retrieval-augmented generation (RAG) is a mainstream method for improving performance on knowledge-intensive tasks. However,current RAG systems often place too much emphasis on retrieved contexts. This can lead to reliance on inaccurate sources and overlook the model's inherent knowledge, especially when dealing with misleading or excessive information. To resolve this imbalance, we propose Knowledgeable-r1 that using joint sampling and define multi policy distributions in knowledge capability exploration to stimulate large language models'self-integrated utilization of parametric and contextual knowledge. Experiments show that Knowledgeable-r1 significantly enhances robustness and reasoning accuracy in both parameters and contextual conflict tasks and general RAG tasks, especially outperforming baselines by 17.07% in counterfactual scenarios and demonstrating consistent gains across RAG tasks. Our code are available at https://github.com/lcy80366872/ knowledgeable-r1.