 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flexible Plug-and-Play Module for Generating Variable-Length
Dec 12, 2024Deep supervised hashing has become a pivotal technique in large-scale image retrieval, offering significant benefits in terms of storage and search efficiency. However, existing deep supervised hashing models predominantly focus on generating fixed-length hash codes. This approach fails to address the inherent trade-off between efficiency and effectiveness when using hash codes of varying lengths. To determine the optimal hash code length for a specific task, multiple models must be trained for different lengths, leading to increased training time and computational overhead. Furthermore, the current paradigm overlooks the potential relationships between hash codes of different lengths, limiting the overall effectiveness of the models. To address these challenges, we propose the Nested Hash Layer (NHL), a plug-and-play module designed for existing deep supervised hashing models. The NHL framework introduces a novel mechanism to simultaneously generate hash codes of varying lengths in a nested manner. To tackle the optimization conflicts arising from the multiple learning objectives associated with different code lengths, we further propose an adaptive weights strategy that dynamically monitors and adjusts gradients during training. Additionally, recognizing that the structural information in longer hash codes can provide valuable guidance for shorter hash codes, we develop a long-short cascade self-distillation method within the NHL to enhance the overall quality of the generated hash codes. Extensive experiments demonstrate that NHL not only accelerates the training process but also achieves superior retrieval performance across various deep hashing models. Our code is publicly available at https://github.com/hly1998/NHL.
What Makes In-context Learning Effective for Mathematical Reasoning: A Theoretical Analysis
Dec 11, 2024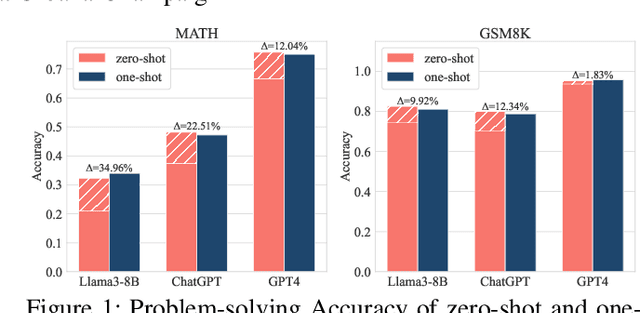



Owing to the capability of in-context learning, large language models (LLMs) have shown impressive performance across diverse mathematical reasoning benchmarks. However, we find that few-shot demonstrations can sometimes bring negative performance and their effectiveness on LLMs' reasoning abilities remains unreliable. To this end, in this paper, we aim to theoretically analyze the impact of in-context demonstrations on LLMs' reasoning performance. We prove that the reasoning efficacy (measured by empirical prediction loss) can be bounded by a LLM-oriented semantic similarity and an inference stability of demonstrations, which is general for both one-shot and few-shot scenarios. Based on this finding, we propose a straightforward, generalizable, and low-complexity demonstration selection method named LMS3. It can adaptively facilitate to select the most pertinent samples for different LLMs and includes a novel demonstration rejection mechanism to automatically filter out samples that are unsuitable for few-shot learning. Through experiments on three representative benchmarks, two LLM backbones, and multiple few-shot settings, we verify that our LMS3 has superiority and achieves consistent improvements on all datasets, which existing methods have been unable to accomplish.
Predictive Models in Sequential Recommendations: Bridging Performance Laws with Data Quality Insights
Dec 03, 2024



Sequential Recommendation (SR) plays a critical role in predicting users' sequential preferences. Despite its growing prominence in various industries, the increasing scale of SR models incurs substantial computational costs and unpredictability, challenging developers to manage resources efficiently. Under this predicament, Scaling Laws have achieved significant success by examining the loss as models scale up. However, there remains a disparity between loss and model performance, which is of greater concern in practical applications. Moreover, as data continues to expand, it incorporates repetitive and inefficient data. In response, we introduce the Performance Law for SR models, which aims to theoretically investigate and model the relationship between model performance and data quality. Specifically, we first fit the HR and NDCG metrics to transformer-based SR models. Subsequently, we propose Approximate Entropy (ApEn) to assess data quality, presenting a more nuanced approach compared to traditional data quantity metrics. Our method enables accurate predictions across various dataset scales and model sizes, demonstrating a strong correlation in large SR models and offering insights into achieving optimal performance for any given model configuration.
T2Vid: Translating Long Text into Multi-Image is the Catalyst for Video-LLMs
Dec 02, 2024



The success of Multimodal Large Language Models (MLLMs) in the image domain has garnered wide attention from the research community. Drawing on previous successful experiences, researchers have recently explored extending the success to the video understanding realms. Apart from training from scratch, an efficient way is to utilize the pre-trained image-LLMs, leading to two mainstream approaches, i.e. zero-shot inference and further fine-tuning with video data. In this work, our study of these approaches harvests an effective data augmentation method. We first make a deeper inspection of the zero-shot inference way and identify two limitations, i.e. limited generalization and lack of temporal understanding capabilities. Thus, we further investigate the fine-tuning approach and find a low learning efficiency when simply using all the video data samples, which can be attributed to a lack of instruction diversity. Aiming at this issue, we develop a method called T2Vid to synthesize video-like samples to enrich the instruction diversity in the training corpus. Integrating these data enables a simple and efficient training scheme, which achieves performance comparable to or even superior to using full video datasets by training with just 15% the sample size. Meanwhile, we find that the proposed scheme can boost the performance of long video understanding without training with long video samples. We hope our study will spark more thinking about using MLLMs for video understanding and curation of high-quality data. The code is released at https://github.com/xjtupanda/T2Vid.
Scaling New Frontiers: Insights into Large Recommendation Models
Dec 01, 2024



Recommendation systems are essential for filtering data and retrieving relevant information across various applications. Recent advancements have seen these systems incorporate increasingly large embedding tables, scaling up to tens of terabytes for industrial use. However, the expansion of network parameters in traditional recommendation models has plateaued at tens of millions, limiting further benefits from increased embedding parameters. Inspired by the success of large language models (LLMs), a new approach has emerged that scales network parameters using innovative structures, enabling continued performance improvements. A significant development in this area is Meta's generative recommendation model HSTU, which illustrates the scaling laws of recommendation systems by expanding parameters to thousands of billions. This new paradigm has achieved substantial performance gains in online experiments. In this paper, we aim to enhance the understanding of scaling laws by conducting comprehensive evaluations of large recommendation models. Firstly, we investigate the scaling laws across different backbone architectures of the large recommendation models. Secondly, we conduct comprehensive ablation studies to explore the origins of these scaling laws. We then further assess the performance of HSTU, as the representative of large recommendation models, on complex user behavior modeling tasks to evaluate its applicability. Notably, we also analyze its effectiveness in ranking tasks for the first time. Finally, we offer insights into future directions for large recommendation models. Supplementary materials for our research are available on GitHub at https://github.com/USTC-StarTeam/Large-Recommendation-Models.
ScalingNote: Scaling up Retrievers with Large Language Models for Real-World Dense Retrieval
Nov 24, 2024



Dense retrieval in most industries employs dual-tower architectures to retrieve query-relevant documents. Due to online deployment requirements, existing real-world dense retrieval systems mainly enhance performance by designing negative sampling strategies, overlooking the advantages of scaling up. Recently, Large Language Models (LLMs) have exhibited superior performance that can be leveraged for scaling up dense retrieval. However, scaling up retrieval models significantly increases online query latency. To address this challenge, we propose ScalingNote, a two-stage method to exploit the scaling potential of LLMs for retrieval while maintaining online query latency. The first stage is training dual towers, both initialized from the same LLM, to unlock the potential of LLMs for dense retrieval. Then, we distill only the query tower using mean squared error loss and cosine similarity to reduce online costs. Through theoretical analysis and comprehensive offline and online experiments, we show the effectiveness and efficiency of ScalingNote. Our two-stage scaling method outperforms end-to-end models and verifies the scaling law of dense retrieval with LLMs in industrial scenarios, enabling cost-effective scaling of dense retrieval systems. Our online method incorporating ScalingNote significantly enhances the relevance between retrieved documents and queries.
TableTime: Reformulating Time Series Classification as Zero-Shot Table Understanding via Large Language Models
Nov 24, 2024



Large language models (LLMs) have demonstrated their effectiveness in multivariate time series classification (MTSC). Effective adaptation of LLMs for MTSC necessitates informative data representations. Existing LLM-based methods directly encode embeddings for time series within the latent space of LLMs from scratch to align with semantic space of LLMs. Despite their effectiveness, we reveal that these methods conceal three inherent bottlenecks: (1) they struggle to encode temporal and channel-specific information in a lossless manner, both of which are critical components of multivariate time series; (2) it is much difficult to align the learned representation space with the semantic space of the LLMs; (3) they require task-specific retraining, which is both computationally expensive and labor-intensive. To bridge these gaps, we propose TableTime, which reformulates MTSC as a table understanding task. Specifically, TableTime introduces the following strategies: (1) convert multivariate time series into a tabular form, thus minimizing information loss to the greatest extent; (2) represent tabular time series in text format to achieve natural alignment with the semantic space of LLMs; (3) design a reasoning framework that integrates contextual text information, neighborhood assistance, multi-path inference and problem decomposition to enhance the reasoning ability of LLMs and realize zero-shot classification. Extensive experiments performed on 10 publicly representative datasets from UEA archive verify the superiorities of the TableTime.
Multi-granularity Interest Retrieval and Refinement Network for Long-Term User Behavior Modeling in CTR Prediction
Nov 22, 2024



Click-through Rate (CTR) prediction is crucial for online personalization platforms. Recent advancements have shown that modeling rich user behaviors can significantly improve the performance of CTR prediction. Current long-term user behavior modeling algorithms predominantly follow two cascading stages. The first stage retrieves subsequence related to the target item from the long-term behavior sequence, while the second stage models the relationship between the subsequence and the target item. Despite significant progress, these methods have two critical flaws. First, the retrieval query typically includes only target item information, limiting the ability to capture the user's diverse interests. Second, relational information, such as sequential and interactive information within the subsequence, is frequently overlooked. Therefore, it requires to be further mined to more accurately model user interests. To this end, we propose Multi-granularity Interest Retrieval and Refinement Network (MIRRN). Specifically, we first construct queries based on behaviors observed at different time scales to obtain subsequences, each capturing users' interest at various granularities. We then introduce an noval multi-head Fourier transformer to efficiently learn sequential and interactive information within the subsequences, leading to more accurate modeling of user interests. Finally, we employ multi-head target attention to adaptively assess the impact of these multi-granularity interests on the target item. Extensive experiments have demonstrated that MIRRN significantly outperforms state-of-the-art baselines. Furthermore, an A/B test shows that MIRRN increases the average number of listening songs by 1.32% and the average time of listening songs by 0.55% on a popular music streaming app. The implementation code is publicly available at https://github.com/psycho-demon/MIRRN.
Breaking Determinism: Fuzzy Modeling of Sequential Recommendation Using Discrete State Space Diffusion Model
Oct 31, 2024



Sequential recommendation (SR) aims to predict items that users may be interested in based on their historical behavior sequences. We revisit SR from a novel information-theoretic perspective and find that conventional sequential modeling methods fail to adequately capture the randomness and unpredictability of user behavior. Inspired by fuzzy information processing theory, this paper introduces the DDSR model, which uses fuzzy sets of interaction sequences to overcome the limitations and better capture the evolution of users' real interests. Formally based on diffusion transition processes in discrete state spaces, which is unlike common diffusion models such as DDPM that operate in continuous domains. It is better suited for discrete data, using structured transitions instead of arbitrary noise introduction to avoid information loss. Additionally, to address the inefficiency of matrix transformations due to the vast discrete space, we use semantic labels derived from quantization or RQ-VAE to replace item IDs, enhancing efficiency and improving cold start issues. Testing on three public benchmark datasets shows that DDSR outperforms existing state-of-the-art methods in various settings, demonstrating its potential and effectiveness in handling SR tasks.
DisenTS: Disentangled Channel Evolving Pattern Modeling for Multivariate Time Series Forecasting
Oct 30, 2024



Multivariate time series forecasting plays a crucial role in various real-world applications. Significant efforts have been made to integrate advanced network architectures and training strategies that enhance the capture of temporal dependencies, thereby improving forecasting accuracy. On the other hand, mainstream approaches typically utilize a single unified model with simplistic channel-mixing embedding or cross-channel attention operations to account for the critical intricate inter-channel dependencies. Moreover, some methods even trade capacity for robust prediction based on the channel-independent assumption. Nonetheless, as time series data may display distinct evolving patterns due to the unique characteristics of each channel (including multiple strong seasonalities and trend changes), the unified modeling methods could yield suboptimal results. To this end, we propose DisenTS, a tailored framework for modeling disentangled channel evolving patterns in general multivariate time series forecasting. The central idea of DisenTS is to model the potential diverse patterns within the multivariate time series data in a decoupled manner. Technically, the framework employs multiple distinct forecasting models, each tasked with uncovering a unique evolving pattern. To guide the learning process without supervision of pattern partition, we introduce a novel Forecaster Aware Gate (FAG) module that generates the routing signals adaptively according to both the forecasters' states and input series' characteristics. The forecasters' states are derived from the Linear Weight Approximation (LWA) strategy, which quantizes the complex deep neural networks into compact matrices. Additionally, the Similarity Constraint (SC) is further proposed to guide each model to specialize in an underlying pattern by minimizing the mutual information between the representations.