 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUI-360$^\circ$: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 10, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
GUI-360: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 06, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
SheetBrain: A Neuro-Symbolic Agent for Accurate Reasoning over Complex and Large Spreadsheets
Oct 22, 2025Understanding and reasoning over complex spreadsheets remain fundamental challenges for large language models (LLMs), which often struggle with accurately capturing the complex structure of tables and ensuring reasoning correctness. In this work, we propose SheetBrain, a neuro-symbolic dual workflow agent framework designed for accurate reasoning over tabular data, supporting both spreadsheet question answering and manipulation tasks. SheetBrain comprises three core modules: an understanding module, which produces a comprehensive overview of the spreadsheet - including sheet summary and query-based problem insight to guide reasoning; an execution module, which integrates a Python sandbox with preloaded table-processing libraries and an Excel helper toolkit for effective multi-turn reasoning; and a validation module, which verifies the correctness of reasoning and answers, triggering re-execution when necessary. We evaluate SheetBrain on multiple public tabular QA and manipulation benchmarks, and introduce SheetBench, a new benchmark targeting large, multi-table, and structurally complex spreadsheets. Experimental results show that SheetBrain significantly improves accuracy on both existing benchmarks and the more challenging scenarios presented in SheetBench. Our code is publicly available at https://github.com/microsoft/SheetBrain.
Jupiter: Enhancing LLM Data Analysis Capabilities via Notebook and Inference-Time Value-Guided Search
Sep 11, 2025



Large language models (LLMs) have shown great promise in automating data science workflows, but existing models still struggle with multi-step reasoning and tool use, which limits their effectiveness on complex data analysis tasks. To address this, we propose a scalable pipeline that extracts high-quality, tool-based data analysis tasks and their executable multi-step solutions from real-world Jupyter notebooks and associated data files. Using this pipeline, we introduce NbQA, a large-scale dataset of standardized task-solution pairs that reflect authentic tool-use patterns in practical data science scenarios. To further enhance multi-step reasoning, we present Jupiter, a framework that formulates data analysis as a search problem and applies Monte Carlo Tree Search (MCTS) to generate diverse solution trajectories for value model learning. During inference, Jupiter combines the value model and node visit counts to efficiently collect executable multi-step plans with minimal search steps. Experimental results show that Qwen2.5-7B and 14B-Instruct models on NbQA solve 77.82% and 86.38% of tasks on InfiAgent-DABench, respectively-matching or surpassing GPT-4o and advanced agent frameworks. Further evaluations demonstrate improved generalization and stronger tool-use reasoning across diverse multi-step reasoning tasks.
SheetDesigner: MLLM-Powered Spreadsheet Layout Generation with Rule-Based and Vision-Based Reflection
Sep 09, 2025



Spreadsheets are critical to data-centric tasks, with rich, structured layouts that enable efficient information transmission. Given the time and expertise required for manual spreadsheet layout design, there is an urgent need for automated solutions. However, existing automated layout models are ill-suited to spreadsheets, as they often (1) treat components as axis-aligned rectangles with continuous coordinates, overlooking the inherently discrete, grid-based structure of spreadsheets; and (2) neglect interrelated semantics, such as data dependencies and contextual links, unique to spreadsheets. In this paper, we first formalize the spreadsheet layout generation task, supported by a seven-criterion evaluation protocol and a dataset of 3,326 spreadsheets. We then introduce SheetDesigner, a zero-shot and training-free framework using Multimodal Large Language Models (MLLMs) that combines rule and vision reflection for component placement and content population. SheetDesigner outperforms five baselines by at least 22.6\%. We further find that through vision modality, MLLMs handle overlap and balance well but struggle with alignment, necessitates hybrid rule and visual reflection strategies. Our codes and data is available at Github.
AdaptFlow: Adaptive Workflow Optimization via Meta-Learning
Aug 11, 2025Recent advances in large language models (LLMs) have sparked growing interest in agentic workflows, which are structured sequences of LLM invocations intended to solve complex tasks. However, existing approaches often rely on static templates or manually designed workflows, which limit adaptability to diverse tasks and hinder scalability. We propose AdaptFlow, a natural language-based meta-learning framework inspired by model-agnostic meta-learning (MAML). AdaptFlow learns a generalizable workflow initialization that enables rapid subtask-level adaptation. It employs a bi-level optimization scheme: the inner loop refines the workflow for a specific subtask using LLM-generated feedback, while the outer loop updates the shared initialization to perform well across tasks. This setup allows AdaptFlow to generalize effectively to unseen tasks by adapting the initialized workflow through language-guided modifications. Evaluated across question answering, code generation, and mathematical reasoning benchmarks, AdaptFlow consistently outperforms both manually crafted and automatically searched baselines, achieving state-of-the-art results with strong generalization across tasks and models. The source code and data are available at https://github.com/microsoft/DKI_LLM/tree/AdaptFlow/AdaptFlow.
Bingo: Boosting Efficient Reasoning of LLMs via Dynamic and Significance-based Reinforcement Learning
Jun 09, 2025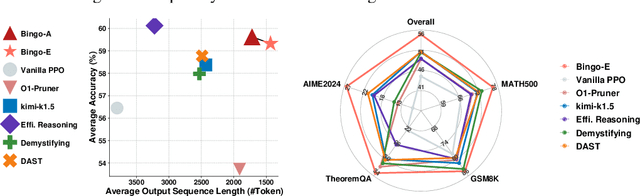
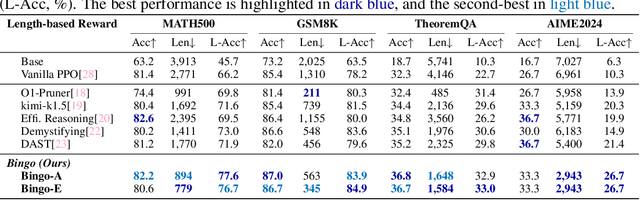
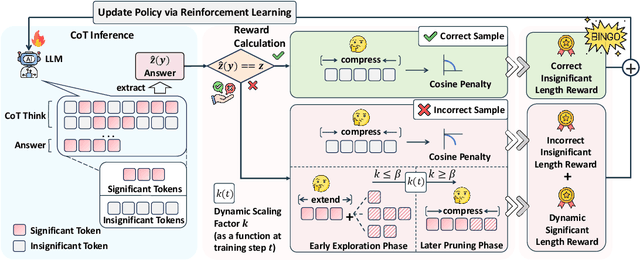
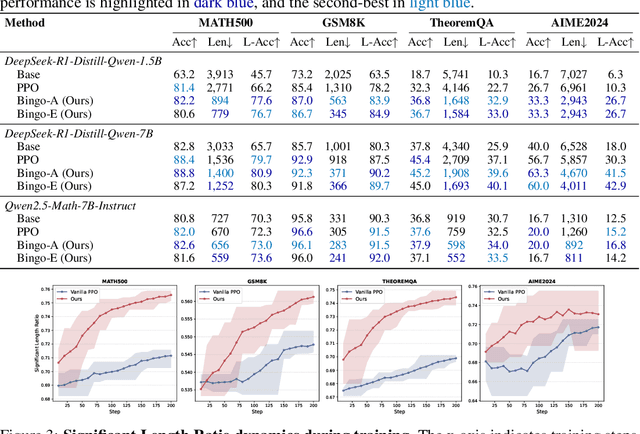
Large language models have demonstrated impressive reasoning capabilities, yet they often suffer from inefficiencies due to unnecessarily verbose or redundant outputs. While many works have explored reinforcement learning (RL) to enhance reasoning abilities, most primarily focus on improving accuracy, with limited attention to reasoning efficiency. Some existing approaches introduce direct length-based rewards to encourage brevity, but this often leads to noticeable drops in accuracy. In this paper, we propose Bingo, an RL framework that advances length-based reward design to boost efficient reasoning. Bingo incorporates two key mechanisms: a significance-aware length reward, which gradually guides the model to reduce only insignificant tokens, and a dynamic length reward, which initially encourages elaborate reasoning for hard questions but decays over time to improve overall efficiency. Experiments across multiple reasoning benchmarks show that Bingo improves both accuracy and efficiency. It outperforms the vanilla reward and several other length-based reward baselines in RL, achieving a favorable trade-off between accuracy and efficiency. These results underscore the potential of training LLMs explicitly for efficient reasoning.
MMTU: A Massive Multi-Task Table Understanding and Reasoning Benchmark
Jun 05, 2025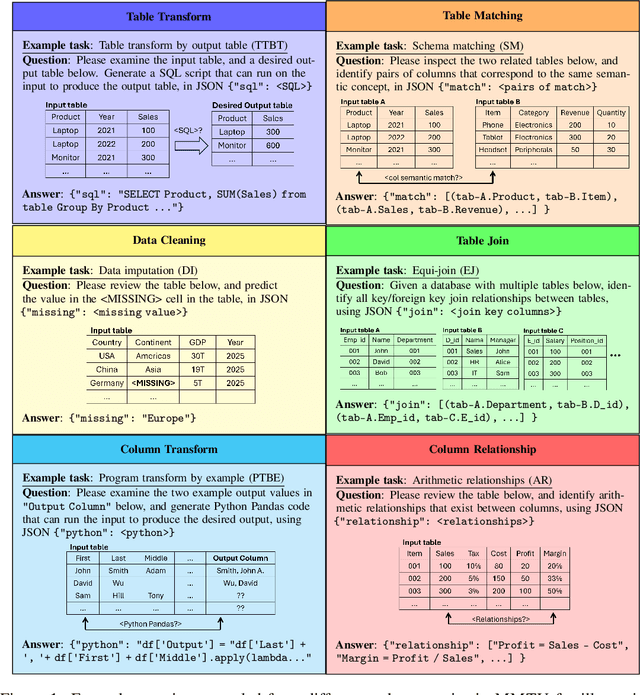


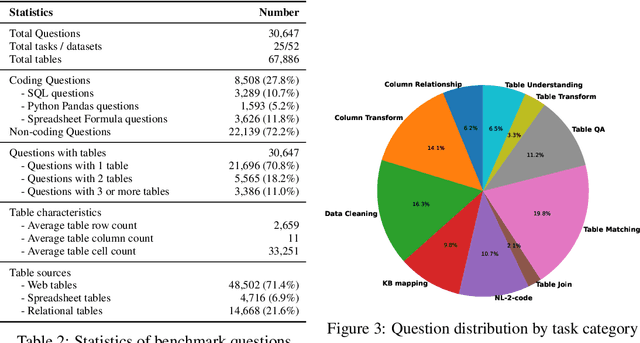
Tables and table-based use cases play a crucial role in many important real-world applications, such as spreadsheets, databases, and computational notebooks, which traditionally require expert-level users like data engineers, data analysts, and database administrators to operate. Although LLMs have shown remarkable progress in working with tables (e.g., in spreadsheet and database copilot scenarios), comprehensive benchmarking of such capabilities remains limited. In contrast to an extensive and growing list of NLP benchmarks, evaluations of table-related tasks are scarce, and narrowly focus on tasks like NL-to-SQL and Table-QA, overlooking the broader spectrum of real-world tasks that professional users face. This gap limits our understanding and model progress in this important area. In this work, we introduce MMTU, a large-scale benchmark with over 30K questions across 25 real-world table tasks, designed to comprehensively evaluate models ability to understand, reason, and manipulate real tables at the expert-level. These tasks are drawn from decades' worth of computer science research on tabular data, with a focus on complex table tasks faced by professional users. We show that MMTU require a combination of skills -- including table understanding, reasoning, and coding -- that remain challenging for today's frontier models, where even frontier reasoning models like OpenAI o4-mini and DeepSeek R1 score only around 60%, suggesting significant room for improvement. We highlight key findings in our evaluation using MMTU and hope that this benchmark drives further advances in understanding and developing foundation models for structured data processing and analysis. Our code and data are available at https://github.com/MMTU-Benchmark/MMTU and https://huggingface.co/datasets/MMTU-benchmark/MMTU.
Fortune: Formula-Driven Reinforcement Learning for Symbolic Table Reasoning in Language Models
May 29, 2025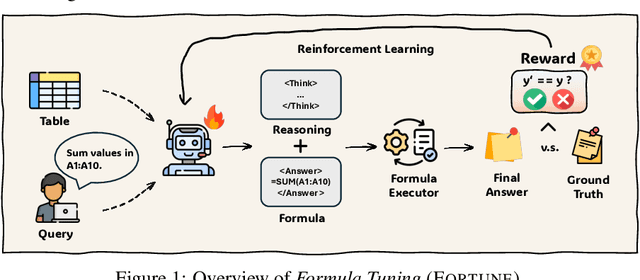



Tables are a fundamental structure for organizing and analyzing data, making effective table understanding a critical capability for intelligent systems. While large language models (LMs) demonstrate strong general reasoning abilities, they continue to struggle with accurate numerical or symbolic reasoning over tabular data, especially in complex scenarios. Spreadsheet formulas provide a powerful and expressive medium for representing executable symbolic operations, encoding rich reasoning patterns that remain largely underutilized. In this paper, we propose Formula Tuning (Fortune), a reinforcement learning (RL) framework that trains LMs to generate executable spreadsheet formulas for question answering over general tabular data. Formula Tuning reduces the reliance on supervised formula annotations by using binary answer correctness as a reward signal, guiding the model to learn formula derivation through reasoning. We provide a theoretical analysis of its advantages and demonstrate its effectiveness through extensive experiments on seven table reasoning benchmarks. Formula Tuning substantially enhances LM performance, particularly on multi-step numerical and symbolic reasoning tasks, enabling a 7B model to outperform O1 on table understanding. This highlights the potential of formula-driven RL to advance symbolic table reasoning in LMs.
SWE-bench Goes Live!
May 29, 2025The issue-resolving task, where a model generates patches to fix real-world bugs, has emerged as a critical benchmark for evaluating the capabilities of large language models (LLMs). While SWE-bench and its variants have become standard in this domain, they suffer from key limitations: they have not been updated since their initial releases, cover a narrow set of repositories, and depend heavily on manual effort for instance construction and environment setup. These factors hinder scalability and introduce risks of overfitting and data contamination. In this work, we present \textbf{SWE-bench-Live}, a \textit{live-updatable} benchmark designed to overcome these challenges. Our initial release consists of 1,319 tasks derived from real GitHub issues created since 2024, spanning 93 repositories. Each task is accompanied by a dedicated Docker image to ensure reproducible execution. Central to our benchmark is \method, an automated curation pipeline that streamlines the entire process from instance creation to environment setup, removing manual bottlenecks and enabling scalability and continuous updates. We evaluate a range of state-of-the-art agent frameworks and LLMs on SWE-bench-Live, revealing a substantial performance gap compared to static benchmarks like SWE-bench, even under controlled evaluation conditions. To better understand this discrepancy, we perform detailed analyses across repository origin, issue recency, and task difficulty. By providing a fresh, diverse, and executable benchmark grounded in live repository activity, SWE-bench-Live facilitates rigorous, contamination-resistant evaluation of LLMs and agents in dynamic, real-world software development settings.