 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical-Knowledge Driven Multiple Instance Learning for Classifying Severe Abdominal Anomalies on Prenatal Ultrasound
Jul 02, 2025



Fetal abdominal malformations are serious congenital anomalies that require accurate diagnosis to guide pregnancy management and reduce mortality. Although AI has demonstrated significant potential in medical diagnosis, its application to prenatal abdominal anomalies remains limited. Most existing studies focus on image-level classification and rely on standard plane localization, placing less emphasis on case-level diagnosis. In this paper, we develop a case-level multiple instance learning (MIL)-based method, free of standard plane localization, for classifying fetal abdominal anomalies in prenatal ultrasound. Our contribution is three-fold. First, we adopt a mixture-of-attention-experts module (MoAE) to weight different attention heads for various planes. Secondly, we propose a medical-knowledge-driven feature selection module (MFS) to align image features with medical knowledge, performing self-supervised image token selection at the case-level. Finally, we propose a prompt-based prototype learning (PPL) to enhance the MFS. Extensively validated on a large prenatal abdominal ultrasound dataset containing 2,419 cases, with a total of 24,748 images and 6 categories, our proposed method outperforms the state-of-the-art competitors. Codes are available at:https://github.com/LL-AC/AAcls.
Fortune: Formula-Driven Reinforcement Learning for Symbolic Table Reasoning in Language Models
May 29, 2025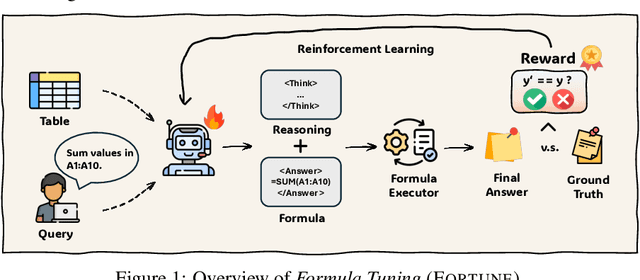



Tables are a fundamental structure for organizing and analyzing data, making effective table understanding a critical capability for intelligent systems. While large language models (LMs) demonstrate strong general reasoning abilities, they continue to struggle with accurate numerical or symbolic reasoning over tabular data, especially in complex scenarios. Spreadsheet formulas provide a powerful and expressive medium for representing executable symbolic operations, encoding rich reasoning patterns that remain largely underutilized. In this paper, we propose Formula Tuning (Fortune), a reinforcement learning (RL) framework that trains LMs to generate executable spreadsheet formulas for question answering over general tabular data. Formula Tuning reduces the reliance on supervised formula annotations by using binary answer correctness as a reward signal, guiding the model to learn formula derivation through reasoning. We provide a theoretical analysis of its advantages and demonstrate its effectiveness through extensive experiments on seven table reasoning benchmarks. Formula Tuning substantially enhances LM performance, particularly on multi-step numerical and symbolic reasoning tasks, enabling a 7B model to outperform O1 on table understanding. This highlights the potential of formula-driven RL to advance symbolic table reasoning in LMs.
TwT: Thinking without Tokens by Habitual Reasoning Distillation with Multi-Teachers' Guidance
Mar 31, 2025



Large Language Models (LLMs) have made significant strides in problem-solving by incorporating reasoning processes. However, this enhanced reasoning capability results in an increased number of output tokens during inference, leading to higher computational costs. To address this challenge, we propose TwT (Thinking without Tokens), a method that reduces inference-time costs through habitual reasoning distillation with multi-teachers' guidance, while maintaining high performance. Our approach introduces a Habitual Reasoning Distillation method, which internalizes explicit reasoning into the model's habitual behavior through a Teacher-Guided compression strategy inspired by human cognition. Additionally, we propose Dual-Criteria Rejection Sampling (DCRS), a technique that generates a high-quality and diverse distillation dataset using multiple teacher models, making our method suitable for unsupervised scenarios. Experimental results demonstrate that TwT effectively reduces inference costs while preserving superior performance, achieving up to a 13.6% improvement in accuracy with fewer output tokens compared to other distillation methods, offering a highly practical solution for efficient LLM deployment.