 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Reward Models for Multi-Domain Test-Time Scaling
Oct 02, 2025The reliability of large language models (LLMs) during test-time scaling is often assessed with \emph{external verifiers} or \emph{reward models} that distinguish correct reasoning from flawed logic. Prior work generally assumes that process reward models (PRMs), which score every intermediate reasoning step, outperform outcome reward models (ORMs) that assess only the final answer. This view is based mainly on evidence from narrow, math-adjacent domains. We present the first unified evaluation of four reward model variants, discriminative ORM and PRM (\DisORM, \DisPRM) and generative ORM and PRM (\GenORM, \GenPRM), across 14 diverse domains. Contrary to conventional wisdom, we find that (i) \DisORM performs on par with \DisPRM, (ii) \GenPRM is not competitive, and (iii) overall, \GenORM is the most robust, yielding significant and consistent gains across every tested domain. We attribute this to PRM-style stepwise scoring, which inherits label noise from LLM auto-labeling and has difficulty evaluating long reasoning trajectories, including those involving self-correcting reasoning. Our theoretical analysis shows that step-wise aggregation compounds errors as reasoning length grows, and our empirical observations confirm this effect. These findings challenge the prevailing assumption that fine-grained supervision is always better and support generative outcome verification for multi-domain deployment. We publicly release our code, datasets, and checkpoints at \href{https://github.com/db-Lee/Multi-RM}{\underline{\small\texttt{https://github.com/db-Lee/Multi-RM}}} to facilitate future research in multi-domain settings.
Sample-efficient LLM Optimization with Reset Replay
Aug 08, 2025



Recent advancements in post-training Large Language Models (LLMs), particularly through Reinforcement Learning (RL) and preference optimization methods, are key drivers for enhancing their reasoning capabilities. However, these methods are often plagued by low sample efficiency and a susceptibility to primacy bias, where overfitting to initial experiences degrades policy quality and damages the learning process. To address these challenges, we introduce LLM optimization with Reset Replay (LoRR), a general and powerful plugin designed to enhance sample efficiency in any preference-based optimization framework. LoRR core mechanism enables training at a high replay number, maximizing the utility of each collected data batch. To counteract the risk of overfitting inherent in high-replay training, LoRR incorporates a periodic reset strategy with reusing initial data, which preserves network plasticity. Furthermore, it leverages a hybrid optimization objective, combining supervised fine-tuning (SFT) and preference-based losses to further bolster data exploitation. Our extensive experiments demonstrate that LoRR significantly boosts the performance of various preference optimization methods on both mathematical and general reasoning benchmarks. Notably, an iterative DPO approach augmented with LoRR achieves comparable performance on challenging math tasks, outperforming some complex and computationally intensive RL-based algorithms. These findings highlight that LoRR offers a practical, sample-efficient, and highly effective paradigm for LLM finetuning, unlocking greater performance from limited data.
Fortune: Formula-Driven Reinforcement Learning for Symbolic Table Reasoning in Language Models
May 29, 2025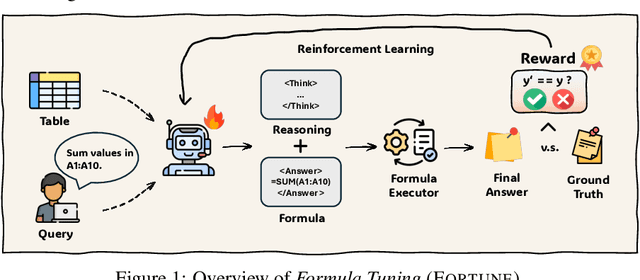



Tables are a fundamental structure for organizing and analyzing data, making effective table understanding a critical capability for intelligent systems. While large language models (LMs) demonstrate strong general reasoning abilities, they continue to struggle with accurate numerical or symbolic reasoning over tabular data, especially in complex scenarios. Spreadsheet formulas provide a powerful and expressive medium for representing executable symbolic operations, encoding rich reasoning patterns that remain largely underutilized. In this paper, we propose Formula Tuning (Fortune), a reinforcement learning (RL) framework that trains LMs to generate executable spreadsheet formulas for question answering over general tabular data. Formula Tuning reduces the reliance on supervised formula annotations by using binary answer correctness as a reward signal, guiding the model to learn formula derivation through reasoning. We provide a theoretical analysis of its advantages and demonstrate its effectiveness through extensive experiments on seven table reasoning benchmarks. Formula Tuning substantially enhances LM performance, particularly on multi-step numerical and symbolic reasoning tasks, enabling a 7B model to outperform O1 on table understanding. This highlights the potential of formula-driven RL to advance symbolic table reasoning in LMs.
OMGM: Orchestrate Multiple Granularities and Modalities for Efficient Multimodal Retrieval
May 10, 2025



Vision-language retrieval-augmented generation (RAG) has become an effective approach for tackling Knowledge-Based Visual Question Answering (KB-VQA), which requires external knowledge beyond the visual content presented in images. The effectiveness of Vision-language RAG systems hinges on multimodal retrieval, which is inherently challenging due to the diverse modalities and knowledge granularities in both queries and knowledge bases. Existing methods have not fully tapped into the potential interplay between these elements. We propose a multimodal RAG system featuring a coarse-to-fine, multi-step retrieval that harmonizes multiple granularities and modalities to enhance efficacy. Our system begins with a broad initial search aligning knowledge granularity for cross-modal retrieval, followed by a multimodal fusion reranking to capture the nuanced multimodal information for top entity selection. A text reranker then filters out the most relevant fine-grained section for augmented generation. Extensive experiments on the InfoSeek and Encyclopedic-VQA benchmarks show our method achieves state-of-the-art retrieval performance and highly competitive answering results, underscoring its effectiveness in advancing KB-VQA systems.
PIKE-RAG: sPecIalized KnowledgE and Rationale Augmented Generation
Jan 20, 2025



Despite notable advancements in Retrieval-Augmented Generation (RAG) systems that expand large language model (LLM) capabilities through external retrieval, these systems often struggle to meet the complex and diverse needs of real-world industrial applications. The reliance on retrieval alone proves insufficient for extracting deep, domain-specific knowledge performing in logical reasoning from specialized corpora. To address this, we introduce sPecIalized KnowledgE and Rationale Augmentation Generation (PIKE-RAG), focusing on extracting, understanding, and applying specialized knowledge, while constructing coherent rationale to incrementally steer LLMs toward accurate responses. Recognizing the diverse challenges of industrial tasks, we introduce a new paradigm that classifies tasks based on their complexity in knowledge extraction and application, allowing for a systematic evaluation of RAG systems' problem-solving capabilities. This strategic approach offers a roadmap for the phased development and enhancement of RAG systems, tailored to meet the evolving demands of industrial applications. Furthermore, we propose knowledge atomizing and knowledge-aware task decomposition to effectively extract multifaceted knowledge from the data chunks and iteratively construct the rationale based on original query and the accumulated knowledge, respectively, showcasing exceptional performance across various benchmarks.
Enhancing Cross-domain Pre-Trained Decision Transformers with Adaptive Attention
Sep 11, 2024



Recently, the pre-training of decision transformers (DT) using a different domain, such as natural language text, has generated significant attention in offline reinforcement learning (Offline RL). Although this cross-domain pre-training approach achieves superior performance compared to training from scratch in environments required short-term planning ability, the mechanisms by which pre-training benefits the fine-tuning phase remain unclear. Furthermore, we point out that the cross-domain pre-training approach hinders the extraction of distant information in environments like PointMaze that require long-term planning ability, leading to performance that is much worse than training DT from scratch. This work first analyzes these issues and found that Markov Matrix, a component that exists in pre-trained attention heads, is the key to explain the significant performance disparity of pre-trained models in different planning abilities. Inspired by our analysis, we propose a general method GPT-DTMA, which equips a pre-trained DT with Mixture of Attention (MoA), to enable adaptive learning and accommodating diverse attention requirements during fine-tuning. Extensive experiments demonstrate that the effectiveness of GPT-DTMA: it achieves superior performance in short-term environments compared to baselines, and in long-term environments, it mitigates the negative impact caused by Markov Matrix, achieving results comparable to those of DT trained from scratch.
Neural Probabilistic Logic Learning for Knowledge Graph Reasoning
Jul 04, 2024



Knowledge graph (KG) reasoning is a task that aims to predict unknown facts based on known factual samples. Reasoning methods can be divided into two categories: rule-based methods and KG-embedding based methods. The former possesses precise reasoning capabilities but finds it challenging to reason efficiently over large-scale knowledge graphs. While gaining the ability to reason over large-scale knowledge graphs, the latter sacrifices reasoning accuracy. This paper aims to design a reasoning framework called Neural Probabilistic Logic Learning(NPLL) that achieves accurate reasoning on knowledge graphs. Our approach introduces a scoring module that effectively enhances the expressive power of embedding networks, striking a balance between model simplicity and reasoning capabilities. We improve the interpretability of the model by incorporating a Markov Logic Network based on variational inference. We empirically evaluate our approach on several benchmark datasets, and the experimental results validate that our method substantially enhances the accuracy and quality of the reasoning results.
Protecting Your LLMs with Information Bottleneck
Apr 22, 2024



The advent of large language models (LLMs) has revolutionized the field of natural language processing, yet they might be attacked to produce harmful content. Despite efforts to ethically align LLMs, these are often fragile and can be circumvented by jailbreaking attacks through optimized or manual adversarial prompts. To address this, we introduce the Information Bottleneck Protector (IBProtector), a defense mechanism grounded in the information bottleneck principle, and we modify the objective to avoid trivial solutions. The IBProtector selectively compresses and perturbs prompts, facilitated by a lightweight and trainable extractor, preserving only essential information for the target LLMs to respond with the expected answer. Moreover, we further consider a situation where the gradient is not visible to be compatible with any LLM. Our empirical evaluations show that IBProtector outperforms current defense methods in mitigating jailbreak attempts, without overly affecting response quality or inference speed. Its effectiveness and adaptability across various attack methods and target LLMs underscore the potential of IBProtector as a novel, transferable defense that bolsters the security of LLMs without requiring modifications to the underlying models.
Higher Replay Ratio Empowers Sample-Efficient Multi-Agent Reinforcement Learning
Apr 15, 2024



One of the notorious issues for Reinforcement Learning (RL) is poor sample efficiency. Compared to single agent RL, the sample efficiency for Multi-Agent Reinforcement Learning (MARL) is more challenging because of its inherent partial observability, non-stationary training, and enormous strategy space. Although much effort has been devoted to developing new methods and enhancing sample efficiency, we look at the widely used episodic training mechanism. In each training step, tens of frames are collected, but only one gradient step is made. We argue that this episodic training could be a source of poor sample efficiency. To better exploit the data already collected, we propose to increase the frequency of the gradient updates per environment interaction (a.k.a. Replay Ratio or Update-To-Data ratio). To show its generality, we evaluate $3$ MARL methods on $6$ SMAC tasks. The empirical results validate that a higher replay ratio significantly improves the sample efficiency for MARL algorithms. The codes to reimplement the results presented in this paper are open-sourced at https://anonymous.4open.science/r/rr_for_MARL-0D83/.
Mildly Constrained Evaluation Policy for Offline Reinforcement Learning
Jun 06, 2023



Offline reinforcement learning (RL) methodologies enforce constraints on the policy to adhere closely to the behavior policy, thereby stabilizing value learning and mitigating the selection of out-of-distribution (OOD) actions during test time. Conventional approaches apply identical constraints for both value learning and test time inference. However, our findings indicate that the constraints suitable for value estimation may in fact be excessively restrictive for action selection during test time. To address this issue, we propose a Mildly Constrained Evaluation Policy (MCEP) for test time inference with a more constrained target policy for value estimation. Since the target policy has been adopted in various prior approaches, MCEP can be seamlessly integrated with them as a plug-in. We instantiate MCEP based on TD3-BC [Fujimoto and Gu, 2021] and AWAC [Nair et al., 2020] algorithms. The empirical results on MuJoCo locomotion tasks show that the MCEP significantly outperforms the target policy and achieves competitive results to state-of-the-art offline RL methods. The codes are open-sourced at https://github.com/egg-west/MCEP.git.