 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMENTO: Teaching LLMs to Manage Their Own Context
Apr 10, 2026Reasoning models think in long, unstructured streams with no mechanism for compressing or organizing their own intermediate state. We introduce MEMENTO: a method that teaches models to segment reasoning into blocks, compress each block into a memento, i.e., a dense state summary, and reason forward by attending only to mementos, reducing context, KV cache, and compute. To train MEMENTO models, we release OpenMementos, a public dataset of 228K reasoning traces derived from OpenThoughts-v3, segmented and annotated with intermediate summaries. We show that a two-stage SFT recipe on OpenMementos is effective across different model families (Qwen3, Phi-4, Olmo 3) and scales (8B--32B parameters). Trained models maintain strong accuracy on math, science, and coding benchmarks while achieving ${\sim}2.5\times$ peak KV cache reduction. We extend vLLM to support our inference method, achieving ${\sim}1.75\times$ throughput improvement while also enabling us to perform RL and further improve accuracy. Finally, we identify a dual information stream: information from each reasoning block is carried both by the memento text and by the corresponding KV states, which retain implicit information from the original block. Removing this channel drops accuracy by 15\,pp on AIME24.
The Price Reversal Phenomenon: When Cheaper Reasoning Models End Up Costing More
Mar 25, 2026Developers and consumers increasingly choose reasoning language models (RLMs) based on their listed API prices. However, how accurately do these prices reflect actual inference costs? We conduct the first systematic study of this question, evaluating 8 frontier RLMs across 9 diverse tasks covering competition math, science QA, code generation, and multi-domain reasoning. We uncover the pricing reversal phenomenon: in 21.8% of model-pair comparisons, the model with a lower listed price actually incurs a higher total cost, with reversal magnitude reaching up to 28x. For example, Gemini 3 Flash's listed price is 78% cheaper than GPT-5.2's, yet its actual cost across all tasks is 22% higher. We trace the root cause to vast heterogeneity in thinking token consumption: on the same query, one model may use 900% more thinking tokens than another. In fact, removing thinking token costs reduces ranking reversals by 70% and raises the rank correlation (Kendall's $τ$ ) between price and cost rankings from 0.563 to 0.873. We further show that per-query cost prediction is fundamentally difficult: repeated runs of the same query yield thinking token variation up to 9.7x, establishing an irreducible noise floor for any predictor. Our findings demonstrate that listed API pricing is an unreliable proxy for actual cost, calling for cost-aware model selection and transparent per-request cost monitoring.
ZEBRAARENA: A Diagnostic Simulation Environment for Studying Reasoning-Action Coupling in Tool-Augmented LLMs
Mar 19, 2026Tool-augmented large language models (LLMs) must tightly couple multi-step reasoning with external actions, yet existing benchmarks often confound this interplay with complex environment dynamics, memorized knowledge or dataset contamination. In this paper, we introduce ZebraArena, a procedurally generated diagnostic environment for studying reasoning-action coupling in tool-augmented LLMs, with controllable difficulty and a knowledge-minimal design, which limits gains from memorization or dataset contamination. Each task in ZebraArena requires a set of critical information which is available only through targeted tool use, yielding an interpretable interface between external information acquisition and deductive reasoning. This design provides deterministic evaluation via unique solutions, and a theoretical optimal query count for measuring efficient tool use. We show that ZebraArena requires a combination of in-depth reasoning and accurate external tool calling, which remains a challenge as frontier reasoning models such as GPT-5 and Gemini 2.5 Pro only achieves 60% accuracy on the hard instances. We also observe a persistent gaps between theoretical optimality and practical tool usage. For example, GPT-5 uses 70-270% more tool calls than the theoretical optimum. We highlight the key findings in our evaluation, and hope ZebraArena stimulates further research on the interplay between internal reasoning and external action.
MMTU: A Massive Multi-Task Table Understanding and Reasoning Benchmark
Jun 05, 2025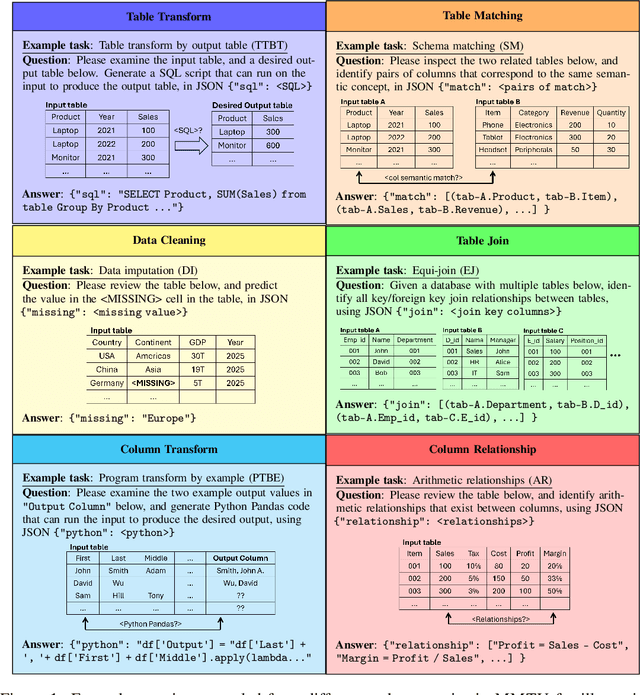


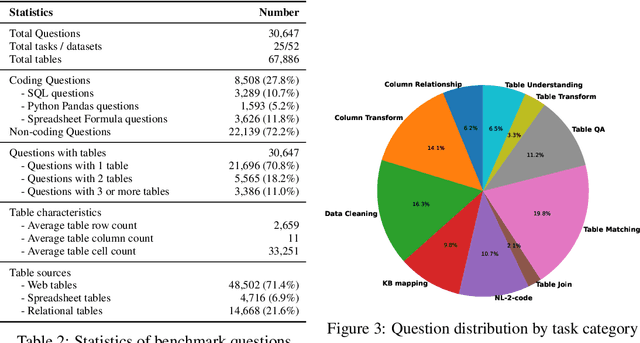
Tables and table-based use cases play a crucial role in many important real-world applications, such as spreadsheets, databases, and computational notebooks, which traditionally require expert-level users like data engineers, data analysts, and database administrators to operate. Although LLMs have shown remarkable progress in working with tables (e.g., in spreadsheet and database copilot scenarios), comprehensive benchmarking of such capabilities remains limited. In contrast to an extensive and growing list of NLP benchmarks, evaluations of table-related tasks are scarce, and narrowly focus on tasks like NL-to-SQL and Table-QA, overlooking the broader spectrum of real-world tasks that professional users face. This gap limits our understanding and model progress in this important area. In this work, we introduce MMTU, a large-scale benchmark with over 30K questions across 25 real-world table tasks, designed to comprehensively evaluate models ability to understand, reason, and manipulate real tables at the expert-level. These tasks are drawn from decades' worth of computer science research on tabular data, with a focus on complex table tasks faced by professional users. We show that MMTU require a combination of skills -- including table understanding, reasoning, and coding -- that remain challenging for today's frontier models, where even frontier reasoning models like OpenAI o4-mini and DeepSeek R1 score only around 60%, suggesting significant room for improvement. We highlight key findings in our evaluation using MMTU and hope that this benchmark drives further advances in understanding and developing foundation models for structured data processing and analysis. Our code and data are available at https://github.com/MMTU-Benchmark/MMTU and https://huggingface.co/datasets/MMTU-benchmark/MMTU.
Phi-4-reasoning Technical Report
Apr 30, 2025We introduce Phi-4-reasoning, a 14-billion parameter reasoning model that achieves strong performance on complex reasoning tasks. Trained via supervised fine-tuning of Phi-4 on carefully curated set of "teachable" prompts-selected for the right level of complexity and diversity-and reasoning demonstrations generated using o3-mini, Phi-4-reasoning generates detailed reasoning chains that effectively leverage inference-time compute. We further develop Phi-4-reasoning-plus, a variant enhanced through a short phase of outcome-based reinforcement learning that offers higher performance by generating longer reasoning traces. Across a wide range of reasoning tasks, both models outperform significantly larger open-weight models such as DeepSeek-R1-Distill-Llama-70B model and approach the performance levels of full DeepSeek-R1 model. Our comprehensive evaluations span benchmarks in math and scientific reasoning, coding, algorithmic problem solving, planning, and spatial understanding. Interestingly, we observe a non-trivial transfer of improvements to general-purpose benchmarks as well. In this report, we provide insights into our training data, our training methodologies, and our evaluations. We show that the benefit of careful data curation for supervised fine-tuning (SFT) extends to reasoning language models, and can be further amplified by reinforcement learning (RL). Finally, our evaluation points to opportunities for improving how we assess the performance and robustness of reasoning models.
Inference-Time Scaling for Complex Tasks: Where We Stand and What Lies Ahead
Mar 31, 2025Inference-time scaling can enhance the reasoning capabilities of large language models (LLMs) on complex problems that benefit from step-by-step problem solving. Although lengthening generated scratchpads has proven effective for mathematical tasks, the broader impact of this approach on other tasks remains less clear. In this work, we investigate the benefits and limitations of scaling methods across nine state-of-the-art models and eight challenging tasks, including math and STEM reasoning, calendar planning, NP-hard problems, navigation, and spatial reasoning. We compare conventional models (e.g., GPT-4o) with models fine-tuned for inference-time scaling (e.g., o1) through evaluation protocols that involve repeated model calls, either independently or sequentially with feedback. These evaluations approximate lower and upper performance bounds and potential for future performance improvements for each model, whether through enhanced training or multi-model inference systems. Our extensive empirical analysis reveals that the advantages of inference-time scaling vary across tasks and diminish as problem complexity increases. In addition, simply using more tokens does not necessarily translate to higher accuracy in these challenging regimes. Results from multiple independent runs with conventional models using perfect verifiers show that, for some tasks, these models can achieve performance close to the average performance of today's most advanced reasoning models. However, for other tasks, a significant performance gap remains, even in very high scaling regimes. Encouragingly, all models demonstrate significant gains when inference is further scaled with perfect verifiers or strong feedback, suggesting ample potential for future improvements.
Optimizing Model Selection for Compound AI Systems
Feb 20, 2025Compound AI systems that combine multiple LLM calls, such as self-refine and multi-agent-debate, achieve strong performance on many AI tasks. We address a core question in optimizing compound systems: for each LLM call or module in the system, how should one decide which LLM to use? We show that these LLM choices have a large effect on quality, but the search space is exponential. We propose LLMSelector, an efficient framework for model selection in compound systems, which leverages two key empirical insights: (i) end-to-end performance is often monotonic in how well each module performs, with all other modules held fixed, and (ii) per-module performance can be estimated accurately by an LLM. Building upon these insights, LLMSelector iteratively selects one module and allocates to it the model with the highest module-wise performance, as estimated by an LLM, until no further gain is possible. LLMSelector is applicable to any compound system with a bounded number of modules, and its number of API calls scales linearly with the number of modules, achieving high-quality model allocation both empirically and theoretically. Experiments with popular compound systems such as multi-agent debate and self-refine using LLMs such as GPT-4o, Claude 3.5 Sonnet and Gemini 1.5 show that LLMSelector confers 5%-70% accuracy gains compared to using the same LLM for all modules.
BARE: Combining Base and Instruction-Tuned Language Models for Better Synthetic Data Generation
Feb 03, 2025



As the demand for high-quality data in model training grows, researchers and developers are increasingly generating synthetic data to tune and train LLMs. A common assumption about synthetic data is that sampling from instruct-tuned models is sufficient; however, these models struggle to produce diverse outputs-a key requirement for generalization. Despite various prompting methods, in this work we show that achieving meaningful diversity from instruct-tuned models remains challenging. In contrast, we find base models without post-training exhibit greater diversity, but are less capable at instruction following and hence of lower quality. Leveraging this insight, we propose Base-Refine (BARE), a synthetic data generation method that combines the diversity of base models with the quality of instruct-tuned models through a two-stage process. With minimal few-shot examples and curation, BARE generates diverse and high-quality datasets, improving downstream task performance. We show that fine-tuning with as few as 1,000 BARE-generated samples can reach performance comparable to the best similarly sized models on LiveCodeBench tasks. Furthermore, fine-tuning with BARE-generated data achieves a 101% improvement over instruct-only data on GSM8K and a 18.4% improvement over SOTA methods on RAFT.
Networks of Networks: Complexity Class Principles Applied to Compound AI Systems Design
Jul 23, 2024



As practitioners seek to surpass the current reliability and quality frontier of monolithic models, Compound AI Systems consisting of many language model inference calls are increasingly employed. In this work, we construct systems, which we call Networks of Networks (NoNs) organized around the distinction between generating a proposed answer and verifying its correctness, a fundamental concept in complexity theory that we show empirically extends to Language Models (LMs). We introduce a verifier-based judge NoN with K generators, an instantiation of "best-of-K" or "judge-based" compound AI systems. Through experiments on synthetic tasks such as prime factorization, and core benchmarks such as the MMLU, we demonstrate notable performance gains. For instance, in factoring products of two 3-digit primes, a simple NoN improves accuracy from 3.7\% to 36.6\%. On MMLU, a verifier-based judge construction with only 3 generators boosts accuracy over individual GPT-4-Turbo calls by 2.8\%. Our analysis reveals that these gains are most pronounced in domains where verification is notably easier than generation--a characterization which we believe subsumes many reasoning and procedural knowledge tasks, but doesn't often hold for factual and declarative knowledge-based settings. For mathematical and formal logic reasoning-based subjects of MMLU, we observe a 5-8\% or higher gain, whilst no gain on others such as geography and religion. We provide key takeaways for ML practitioners, including the importance of considering verification complexity, the impact of witness format on verifiability, and a simple test to determine the potential benefit of this NoN approach for a given problem distribution. This work aims to inform future research and practice in the design of compound AI systems.
Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews
Mar 11, 2024



We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leverages expert-written and AI-generated reference texts to accurately and efficiently examine real-world LLM-use at the corpus level. We apply this approach to a case study of scientific peer review in AI conferences that took place after the release of ChatGPT: ICLR 2024, NeurIPS 2023, CoRL 2023 and EMNLP 2023. Our results suggest that between 6.5% and 16.9% of text submitted as peer reviews to these conferences could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates. The circumstances in which generated text occurs offer insight into user behavior: the estimated fraction of LLM-generated text is higher in reviews which report lower confidence, were submitted close to the deadline, and from reviewers who are less likely to respond to author rebuttals. We also observe corpus-level trends in generated text which may be too subtle to detect at the individual level, and discuss the implications of such trends on peer review. We call for future interdisciplinary work to examine how LLM use is changing our information and knowledge practices.