 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMTU: A Massive Multi-Task Table Understanding and Reasoning Benchmark
Jun 05, 2025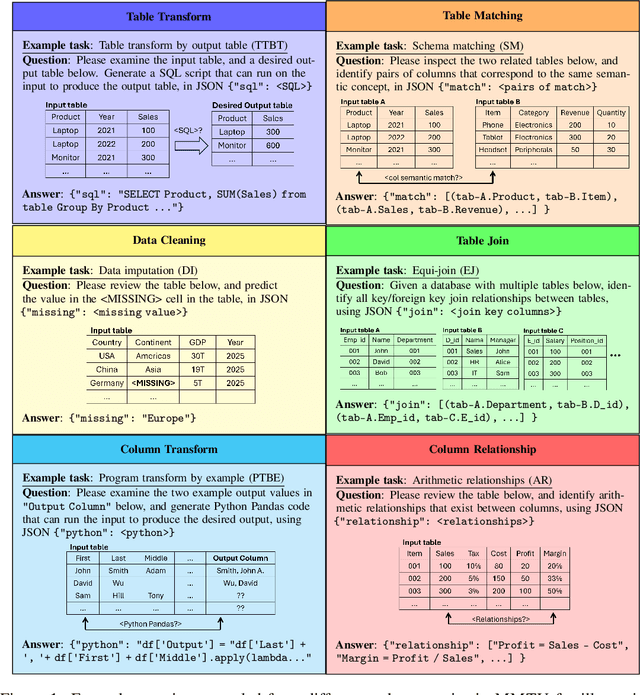


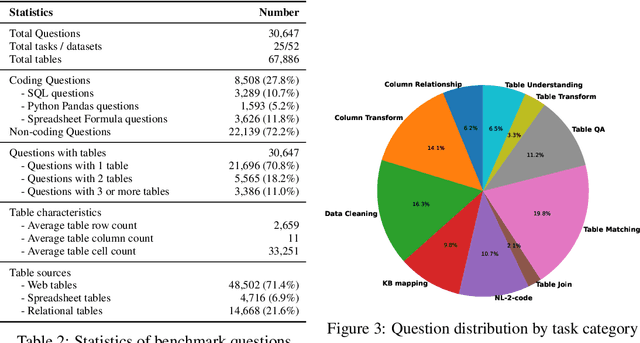
Tables and table-based use cases play a crucial role in many important real-world applications, such as spreadsheets, databases, and computational notebooks, which traditionally require expert-level users like data engineers, data analysts, and database administrators to operate. Although LLMs have shown remarkable progress in working with tables (e.g., in spreadsheet and database copilot scenarios), comprehensive benchmarking of such capabilities remains limited. In contrast to an extensive and growing list of NLP benchmarks, evaluations of table-related tasks are scarce, and narrowly focus on tasks like NL-to-SQL and Table-QA, overlooking the broader spectrum of real-world tasks that professional users face. This gap limits our understanding and model progress in this important area. In this work, we introduce MMTU, a large-scale benchmark with over 30K questions across 25 real-world table tasks, designed to comprehensively evaluate models ability to understand, reason, and manipulate real tables at the expert-level. These tasks are drawn from decades' worth of computer science research on tabular data, with a focus on complex table tasks faced by professional users. We show that MMTU require a combination of skills -- including table understanding, reasoning, and coding -- that remain challenging for today's frontier models, where even frontier reasoning models like OpenAI o4-mini and DeepSeek R1 score only around 60%, suggesting significant room for improvement. We highlight key findings in our evaluation using MMTU and hope that this benchmark drives further advances in understanding and developing foundation models for structured data processing and analysis. Our code and data are available at https://github.com/MMTU-Benchmark/MMTU and https://huggingface.co/datasets/MMTU-benchmark/MMTU.
Table-LLM-Specialist: Language Model Specialists for Tables using Iterative Generator-Validator Fine-tuning
Oct 16, 2024



In this work, we propose Table-LLM-Specialist, or Table-Specialist for short, as a new self-trained fine-tuning paradigm specifically designed for table tasks. Our insight is that for each table task, there often exist two dual versions of the same task, one generative and one classification in nature. Leveraging their duality, we propose a Generator-Validator paradigm, to iteratively generate-then-validate training data from language-models, to fine-tune stronger \sys models that can specialize in a given task, without requiring manually-labeled data. Our extensive evaluations suggest that our Table-Specialist has (1) \textit{strong performance} on diverse table tasks over vanilla language-models -- for example, Table-Specialist fine-tuned on GPT-3.5 not only outperforms vanilla GPT-3.5, but can often match or surpass GPT-4 level quality, (2) \textit{lower cost} to deploy, because when Table-Specialist fine-tuned on GPT-3.5 achieve GPT-4 level quality, it becomes possible to deploy smaller models with lower latency and inference cost, with comparable quality, and (3) \textit{better generalizability} when evaluated across multiple benchmarks, since \sys is fine-tuned on a broad range of training data systematically generated from diverse real tables. Our code and data will be available at https://github.com/microsoft/Table-LLM-Specialist.