 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubstance or Style: What Does Your Image Embedding Know?
Jul 10, 2023Probes are small networks that predict properties of underlying data from embeddings, and they provide a targeted, effective way to illuminate the information contained in embeddings. While analysis through the use of probes has become standard in NLP, there has been much less exploration in vision. Image foundation models have primarily been evaluated for semantic content. Better understanding the non-semantic information in popular embeddings (e.g., MAE, SimCLR, or CLIP) will shed new light both on the training algorithms and on the uses for these foundation models. We design a systematic transformation prediction task and measure the visual content of embeddings along many axes, including image style, quality, and a range of natural and artificial transformations. Surprisingly, six embeddings (including SimCLR) encode enough non-semantic information to identify dozens of transformations. We also consider a generalization task, where we group similar transformations and hold out several for testing. We find that image-text models (CLIP and ALIGN) are better at recognizing new examples of style transfer than masking-based models (CAN and MAE). Overall, our results suggest that the choice of pre-training algorithm impacts the types of information in the embedding, and certain models are better than others for non-semantic downstream tasks.
The Surprising Effectiveness of Diffusion Models for Optical Flow and Monocular Depth Estimation
Jun 02, 2023Denoising diffusion probabilistic models have transformed image generation with their impressive fidelity and diversity. We show that they also excel in estimating optical flow and monocular depth, surprisingly, without task-specific architectures and loss functions that are predominant for these tasks. Compared to the point estimates of conventional regression-based methods, diffusion models also enable Monte Carlo inference, e.g., capturing uncertainty and ambiguity in flow and depth. With self-supervised pre-training, the combined use of synthetic and real data for supervised training, and technical innovations (infilling and step-unrolled denoising diffusion training) to handle noisy-incomplete training data, and a simple form of coarse-to-fine refinement, one can train state-of-the-art diffusion models for depth and optical flow estimation. Extensive experiments focus on quantitative performance against benchmarks, ablations, and the model's ability to capture uncertainty and multimodality, and impute missing values. Our model, DDVM (Denoising Diffusion Vision Model), obtains a state-of-the-art relative depth error of 0.074 on the indoor NYU benchmark and an Fl-all outlier rate of 3.26\% on the KITTI optical flow benchmark, about 25\% better than the best published method. For an overview see https://diffusion-vision.github.io.
A Tale of Two Features: Stable Diffusion Complements DINO for Zero-Shot Semantic Correspondence
May 24, 2023Text-to-image diffusion models have made significant advances in generating and editing high-quality images. As a result, numerous approaches have explored the ability of diffusion model features to understand and process single images for downstream tasks, e.g., classification, semantic segmentation, and stylization. However, significantly less is known about what these features reveal across multiple, different images and objects. In this work, we exploit Stable Diffusion (SD) features for semantic and dense correspondence and discover that with simple post-processing, SD features can perform quantitatively similar to SOTA representations. Interestingly, the qualitative analysis reveals that SD features have very different properties compared to existing representation learning features, such as the recently released DINOv2: while DINOv2 provides sparse but accurate matches, SD features provide high-quality spatial information but sometimes inaccurate semantic matches. We demonstrate that a simple fusion of these two features works surprisingly well, and a zero-shot evaluation using nearest neighbors on these fused features provides a significant performance gain over state-of-the-art methods on benchmark datasets, e.g., SPair-71k, PF-Pascal, and TSS. We also show that these correspondences can enable interesting applications such as instance swapping in two images.
ContactArt: Learning 3D Interaction Priors for Category-level Articulated Object and Hand Poses Estimation
May 02, 2023



We propose a new dataset and a novel approach to learning hand-object interaction priors for hand and articulated object pose estimation. We first collect a dataset using visual teleoperation, where the human operator can directly play within a physical simulator to manipulate the articulated objects. We record the data and obtain free and accurate annotations on object poses and contact information from the simulator. Our system only requires an iPhone to record human hand motion, which can be easily scaled up and largely lower the costs of data and annotation collection. With this data, we learn 3D interaction priors including a discriminator (in a GAN) capturing the distribution of how object parts are arranged, and a diffusion model which generates the contact regions on articulated objects, guiding the hand pose estimation. Such structural and contact priors can easily transfer to real-world data with barely any domain gap. By using our data and learned priors, our method significantly improves the performance on joint hand and articulated object poses estimation over the existing state-of-the-art methods. The project is available at https://zehaozhu.github.io/ContactArt/ .
LOCATE: Localize and Transfer Object Parts for Weakly Supervised Affordance Grounding
Mar 16, 2023



Humans excel at acquiring knowledge through observation. For example, we can learn to use new tools by watching demonstrations. This skill is fundamental for intelligent systems to interact with the world. A key step to acquire this skill is to identify what part of the object affords each action, which is called affordance grounding. In this paper, we address this problem and propose a framework called LOCATE that can identify matching object parts across images, to transfer knowledge from images where an object is being used (exocentric images used for learning), to images where the object is inactive (egocentric ones used to test). To this end, we first find interaction areas and extract their feature embeddings. Then we learn to aggregate the embeddings into compact prototypes (human, object part, and background), and select the one representing the object part. Finally, we use the selected prototype to guide affordance grounding. We do this in a weakly supervised manner, learning only from image-level affordance and object labels. Extensive experiments demonstrate that our approach outperforms state-of-the-art methods by a large margin on both seen and unseen objects.
VQ3D: Learning a 3D-Aware Generative Model on ImageNet
Feb 14, 2023



Recent work has shown the possibility of training generative models of 3D content from 2D image collections on small datasets corresponding to a single object class, such as human faces, animal faces, or cars. However, these models struggle on larger, more complex datasets. To model diverse and unconstrained image collections such as ImageNet, we present VQ3D, which introduces a NeRF-based decoder into a two-stage vector-quantized autoencoder. Our Stage 1 allows for the reconstruction of an input image and the ability to change the camera position around the image, and our Stage 2 allows for the generation of new 3D scenes. VQ3D is capable of generating and reconstructing 3D-aware images from the 1000-class ImageNet dataset of 1.2 million training images. We achieve an ImageNet generation FID score of 16.8, compared to 69.8 for the next best baseline method.
Accidental Light Probes
Jan 12, 2023



Recovering lighting in a scene from a single image is a fundamental problem in computer vision. While a mirror ball light probe can capture omnidirectional lighting, light probes are generally unavailable in everyday images. In this work, we study recovering lighting from accidental light probes (ALPs) -- common, shiny objects like Coke cans, which often accidentally appear in daily scenes. We propose a physically-based approach to model ALPs and estimate lighting from their appearances in single images. The main idea is to model the appearance of ALPs by photogrammetrically principled shading and to invert this process via differentiable rendering to recover incidental illumination. We demonstrate that we can put an ALP into a scene to allow high-fidelity lighting estimation. Our model can also recover lighting for existing images that happen to contain an ALP.
Self-supervised AutoFlow
Dec 08, 2022



Recently, AutoFlow has shown promising results on learning a training set for optical flow, but requires ground truth labels in the target domain to compute its search metric. Observing a strong correlation between the ground truth search metric and self-supervised losses, we introduce self-supervised AutoFlow to handle real-world videos without ground truth labels. Using self-supervised loss as the search metric, our self-supervised AutoFlow performs on par with AutoFlow on Sintel and KITTI where ground truth is available, and performs better on the real-world DAVIS dataset. We further explore using self-supervised AutoFlow in the (semi-)supervised setting and obtain competitive results against the state of the art.
Face Deblurring using Dual Camera Fusion on Mobile Phones
Jul 23, 2022
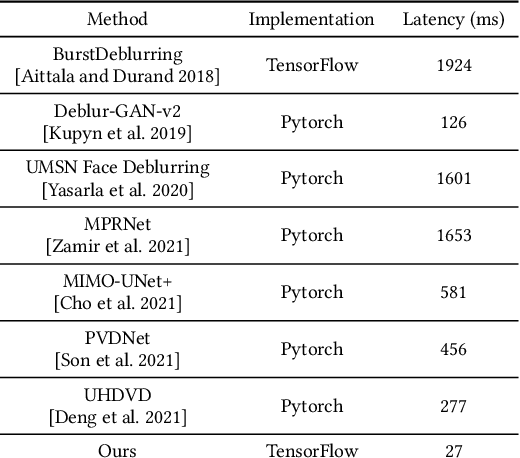

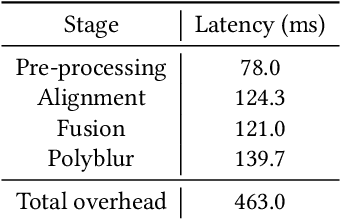
Motion blur of fast-moving subjects is a longstanding problem in photography and very common on mobile phones due to limited light collection efficiency, particularly in low-light conditions. While we have witnessed great progress in image deblurring in recent years, most methods require significant computational power and have limitations in processing high-resolution photos with severe local motions. To this end, we develop a novel face deblurring system based on the dual camera fusion technique for mobile phones. The system detects subject motion to dynamically enable a reference camera, e.g., ultrawide angle camera commonly available on recent premium phones, and captures an auxiliary photo with faster shutter settings. While the main shot is low noise but blurry, the reference shot is sharp but noisy. We learn ML models to align and fuse these two shots and output a clear photo without motion blur. Our algorithm runs efficiently on Google Pixel 6, which takes 463 ms overhead per shot. Our experiments demonstrate the advantage and robustness of our system against alternative single-image, multi-frame, face-specific, and video deblurring algorithms as well as commercial products. To the best of our knowledge, our work is the first mobile solution for face motion deblurring that works reliably and robustly over thousands of images in diverse motion and lighting conditions.
SAMURAI: Shape And Material from Unconstrained Real-world Arbitrary Image collections
May 31, 2022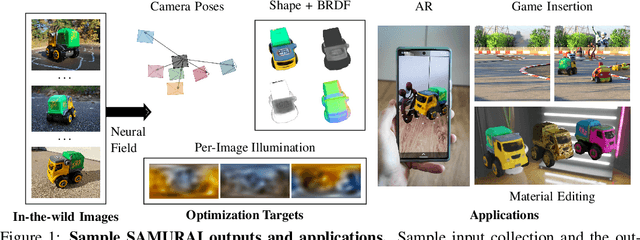

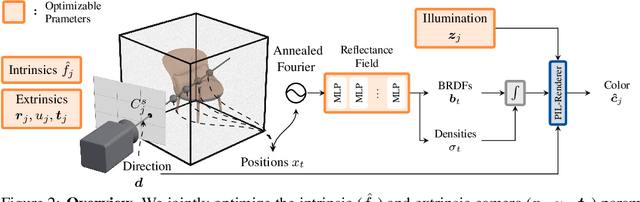

Inverse rendering of an object under entirely unknown capture conditions is a fundamental challenge in computer vision and graphics. Neural approaches such as NeRF have achieved photorealistic results on novel view synthesis, but they require known camera poses. Solving this problem with unknown camera poses is highly challenging as it requires joint optimization over shape, radiance, and pose. This problem is exacerbated when the input images are captured in the wild with varying backgrounds and illuminations. Standard pose estimation techniques fail in such image collections in the wild due to very few estimated correspondences across images. Furthermore, NeRF cannot relight a scene under any illumination, as it operates on radiance (the product of reflectance and illumination). We propose a joint optimization framework to estimate the shape, BRDF, and per-image camera pose and illumination. Our method works on in-the-wild online image collections of an object and produces relightable 3D assets for several use-cases such as AR/VR. To our knowledge, our method is the first to tackle this severely unconstrained task with minimal user interaction. Project page: https://markboss.me/publication/2022-samurai/ Video: https://youtu.be/LlYuGDjXp-8