 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoptic Neural Fields: A Semantic Object-Aware Neural Scene Representation
May 09, 2022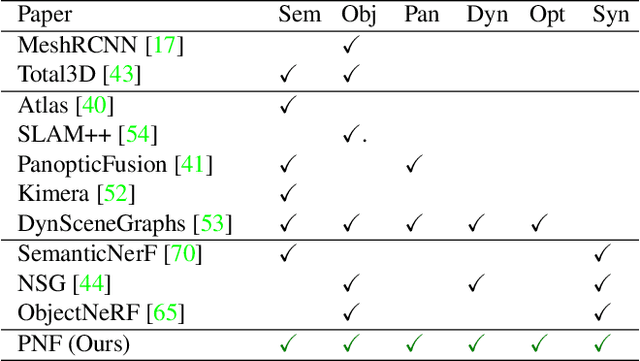
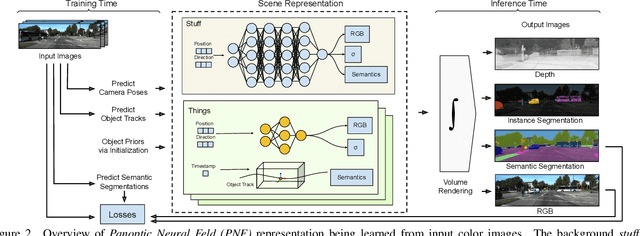
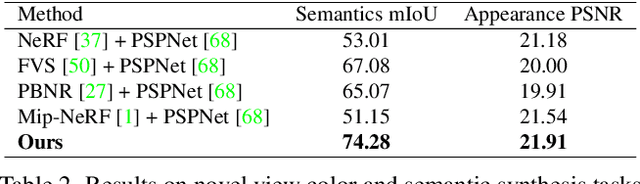
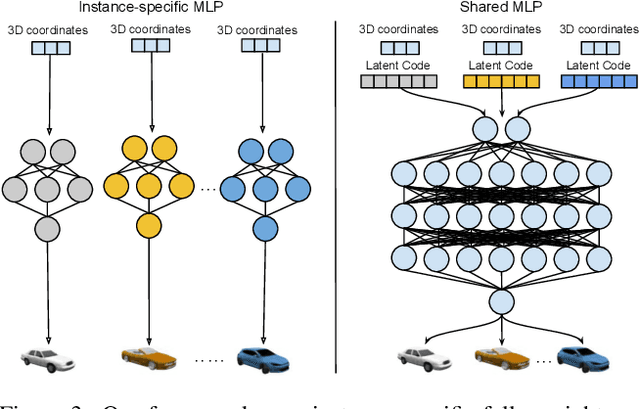
We present Panoptic Neural Fields (PNF), an object-aware neural scene representation that decomposes a scene into a set of objects (things) and background (stuff). Each object is represented by an oriented 3D bounding box and a multi-layer perceptron (MLP) that takes position, direction, and time and outputs density and radiance. The background stuff is represented by a similar MLP that additionally outputs semantic labels. Each object MLPs are instance-specific and thus can be smaller and faster than previous object-aware approaches, while still leveraging category-specific priors incorporated via meta-learned initialization. Our model builds a panoptic radiance field representation of any scene from just color images. We use off-the-shelf algorithms to predict camera poses, object tracks, and 2D image semantic segmentations. Then we jointly optimize the MLP weights and bounding box parameters using analysis-by-synthesis with self-supervision from color images and pseudo-supervision from predicted semantic segmentations. During experiments with real-world dynamic scenes, we find that our model can be used effectively for several tasks like novel view synthesis, 2D panoptic segmentation, 3D scene editing, and multiview depth prediction.
FILM: Frame Interpolation for Large Motion
Feb 12, 2022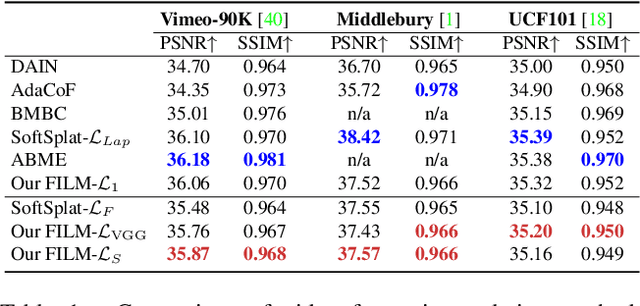
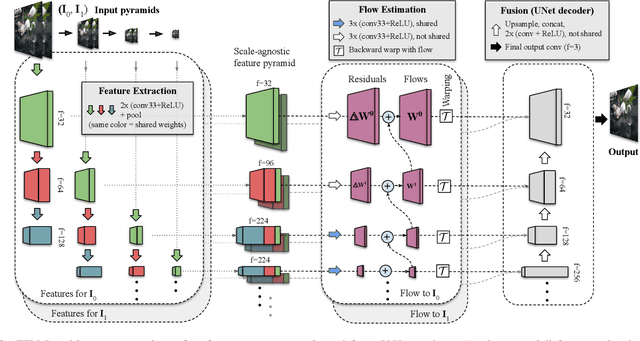
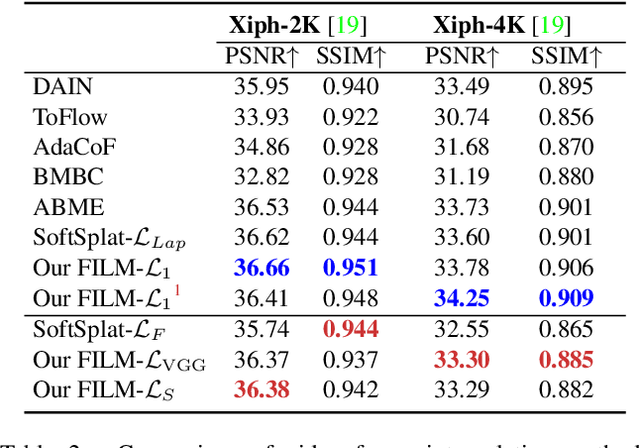
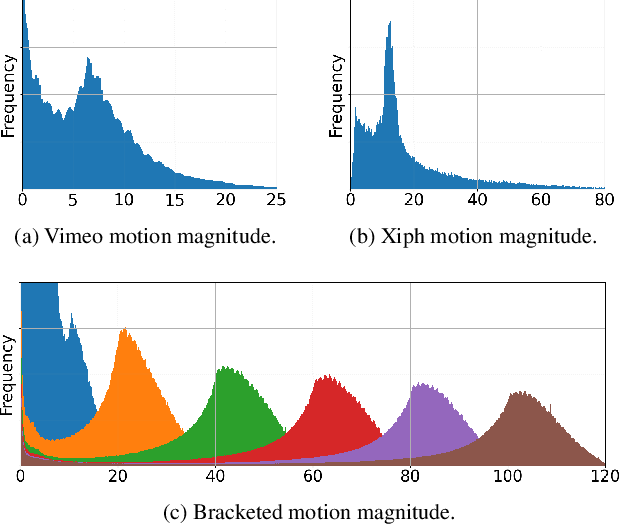
We present a frame interpolation algorithm that synthesizes multiple intermediate frames from two input images with large in-between motion. Recent methods use multiple networks to estimate optical flow or depth and a separate network dedicated to frame synthesis. This is often complex and requires scarce optical flow or depth ground-truth. In this work, we present a single unified network, distinguished by a multi-scale feature extractor that shares weights at all scales, and is trainable from frames alone. To synthesize crisp and pleasing frames, we propose to optimize our network with the Gram matrix loss that measures the correlation difference between feature maps. Our approach outperforms state-of-the-art methods on the Xiph large motion benchmark. We also achieve higher scores on Vimeo-90K, Middlebury and UCF101, when comparing to methods that use perceptual losses. We study the effect of weight sharing and of training with datasets of increasing motion range. Finally, we demonstrate our model's effectiveness in synthesizing high quality and temporally coherent videos on a challenging near-duplicate photos dataset. Codes and pre-trained models are available at https://github.com/google-research/frame-interpolation.
Learning 3D Semantic Segmentation with only 2D Image Supervision
Oct 21, 2021
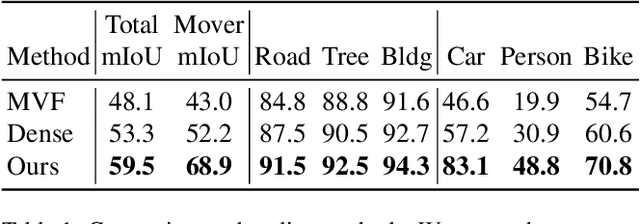
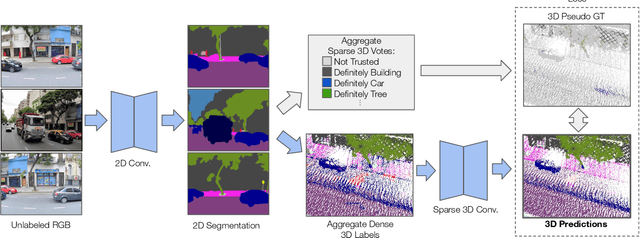
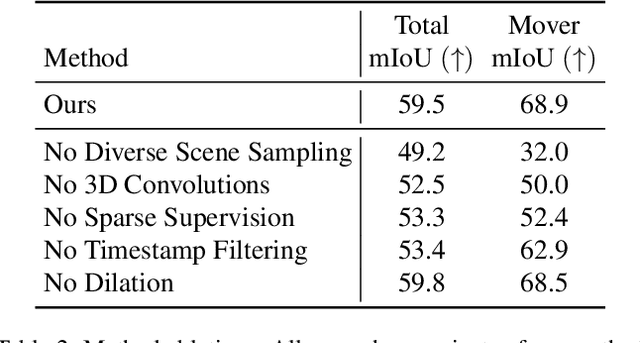
With the recent growth of urban mapping and autonomous driving efforts, there has been an explosion of raw 3D data collected from terrestrial platforms with lidar scanners and color cameras. However, due to high labeling costs, ground-truth 3D semantic segmentation annotations are limited in both quantity and geographic diversity, while also being difficult to transfer across sensors. In contrast, large image collections with ground-truth semantic segmentations are readily available for diverse sets of scenes. In this paper, we investigate how to use only those labeled 2D image collections to supervise training 3D semantic segmentation models. Our approach is to train a 3D model from pseudo-labels derived from 2D semantic image segmentations using multiview fusion. We address several novel issues with this approach, including how to select trusted pseudo-labels, how to sample 3D scenes with rare object categories, and how to decouple input features from 2D images from pseudo-labels during training. The proposed network architecture, 2D3DNet, achieves significantly better performance (+6.2-11.4 mIoU) than baselines during experiments on a new urban dataset with lidar and images captured in 20 cities across 5 continents.
A Step Toward More Inclusive People Annotations for Fairness
May 05, 2021
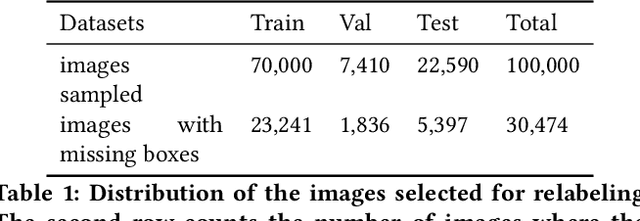
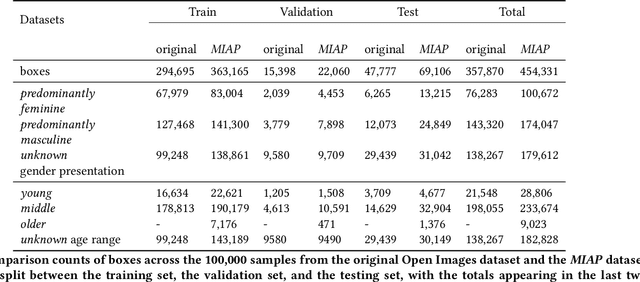
The Open Images Dataset contains approximately 9 million images and is a widely accepted dataset for computer vision research. As is common practice for large datasets, the annotations are not exhaustive, with bounding boxes and attribute labels for only a subset of the classes in each image. In this paper, we present a new set of annotations on a subset of the Open Images dataset called the MIAP (More Inclusive Annotations for People) subset, containing bounding boxes and attributes for all of the people visible in those images. The attributes and labeling methodology for the MIAP subset were designed to enable research into model fairness. In addition, we analyze the original annotation methodology for the person class and its subclasses, discussing the resulting patterns in order to inform future annotation efforts. By considering both the original and exhaustive annotation sets, researchers can also now study how systematic patterns in training annotations affect modeling.
Pillar-based Object Detection for Autonomous Driving
Jul 26, 2020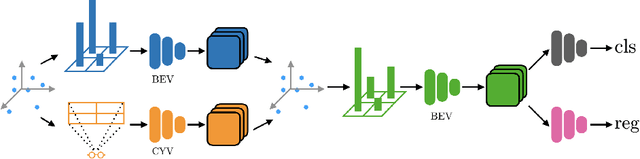
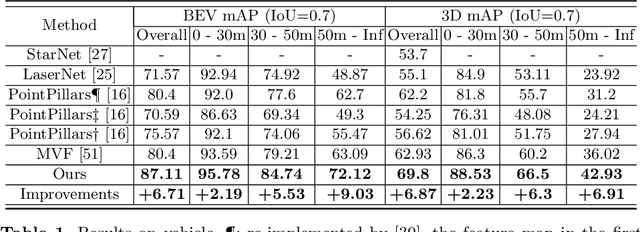
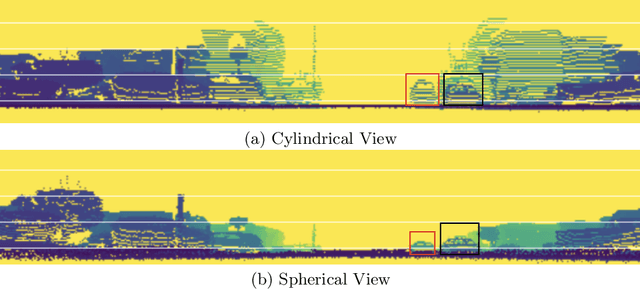

We present a simple and flexible object detection framework optimized for autonomous driving. Building on the observation that point clouds in this application are extremely sparse, we propose a practical pillar-based approach to fix the imbalance issue caused by anchors. In particular, our algorithm incorporates a cylindrical projection into multi-view feature learning, predicts bounding box parameters per pillar rather than per point or per anchor, and includes an aligned pillar-to-point projection module to improve the final prediction. Our anchor-free approach avoids hyperparameter search associated with past methods, simplifying 3D object detection while significantly improving upon state-of-the-art.
Virtual Multi-view Fusion for 3D Semantic Segmentation
Jul 26, 2020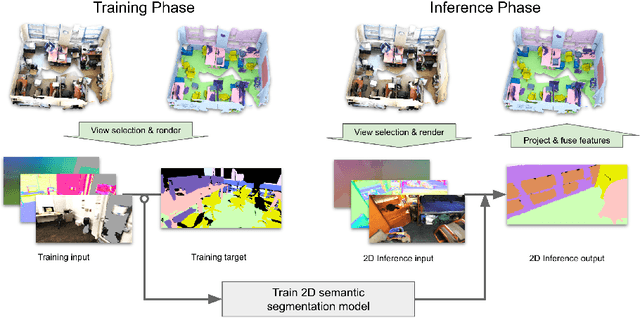
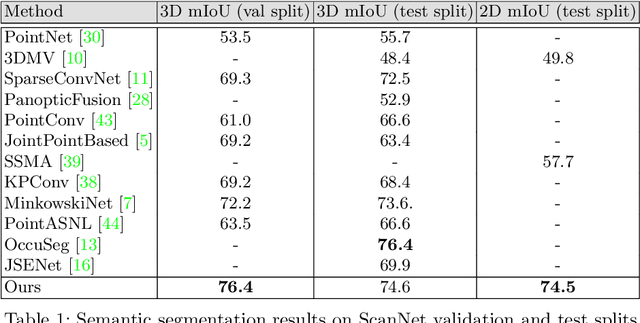
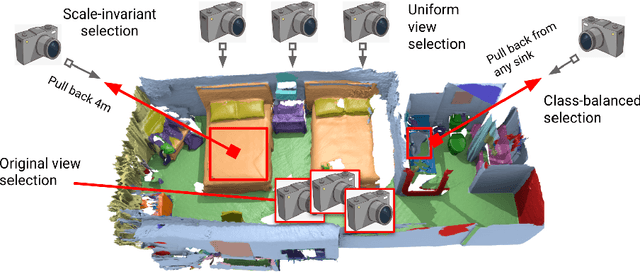
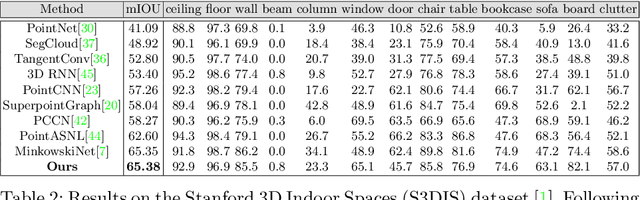
Semantic segmentation of 3D meshes is an important problem for 3D scene understanding. In this paper we revisit the classic multiview representation of 3D meshes and study several techniques that make them effective for 3D semantic segmentation of meshes. Given a 3D mesh reconstructed from RGBD sensors, our method effectively chooses different virtual views of the 3D mesh and renders multiple 2D channels for training an effective 2D semantic segmentation model. Features from multiple per view predictions are finally fused on 3D mesh vertices to predict mesh semantic segmentation labels. Using the large scale indoor 3D semantic segmentation benchmark of ScanNet, we show that our virtual views enable more effective training of 2D semantic segmentation networks than previous multiview approaches. When the 2D per pixel predictions are aggregated on 3D surfaces, our virtual multiview fusion method is able to achieve significantly better 3D semantic segmentation results compared to all prior multiview approaches and competitive with recent 3D convolution approaches.
An LSTM Approach to Temporal 3D Object Detection in LiDAR Point Clouds
Jul 24, 2020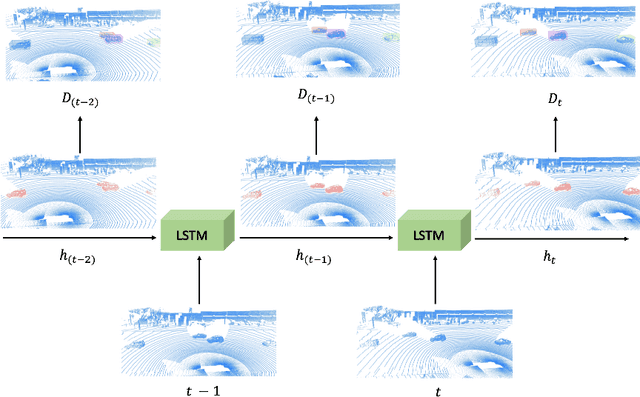
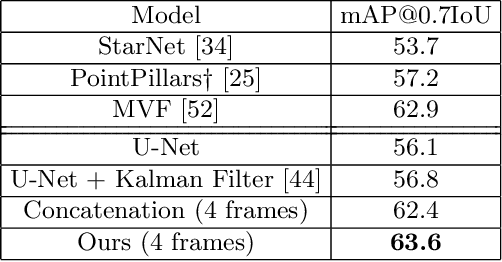
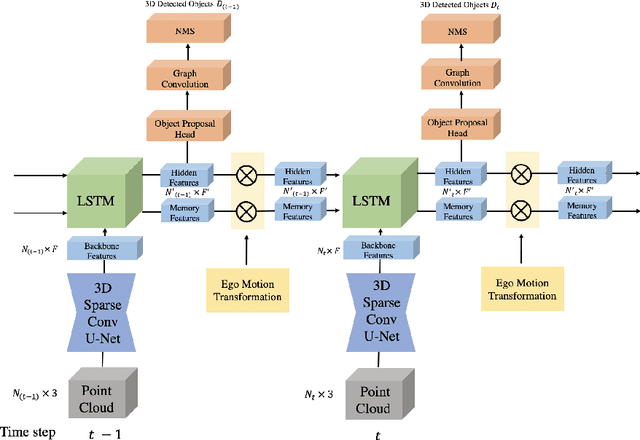
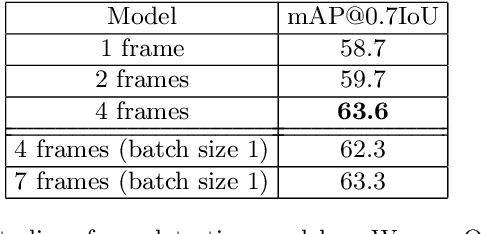
Detecting objects in 3D LiDAR data is a core technology for autonomous driving and other robotics applications. Although LiDAR data is acquired over time, most of the 3D object detection algorithms propose object bounding boxes independently for each frame and neglect the useful information available in the temporal domain. To address this problem, in this paper we propose a sparse LSTM-based multi-frame 3d object detection algorithm. We use a U-Net style 3D sparse convolution network to extract features for each frame's LiDAR point-cloud. These features are fed to the LSTM module together with the hidden and memory features from last frame to predict the 3d objects in the current frame as well as hidden and memory features that are passed to the next frame. Experiments on the Waymo Open Dataset show that our algorithm outperforms the traditional frame by frame approach by 7.5% mAP@0.7 and other multi-frame approaches by 1.2% while using less memory and computation per frame. To the best of our knowledge, this is the first work to use an LSTM for 3D object detection in sparse point clouds.
DOPS: Learning to Detect 3D Objects and Predict their 3D Shapes
Apr 07, 2020
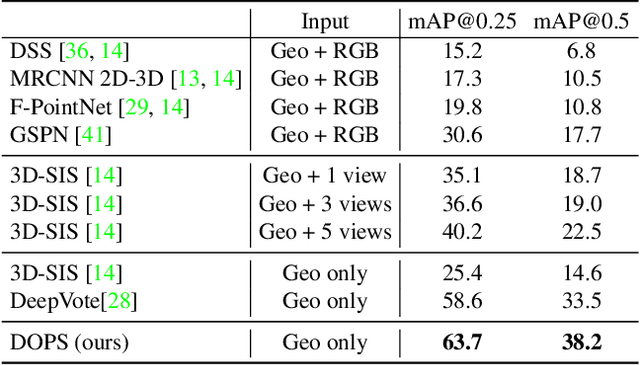
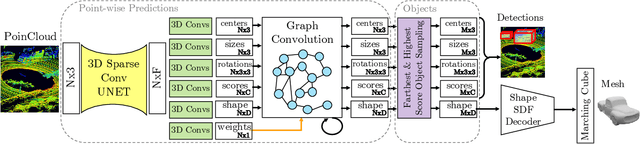
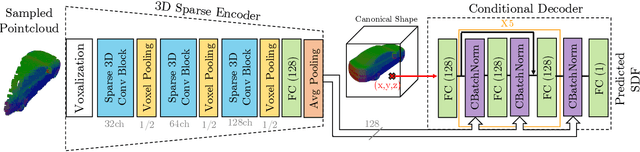
We propose DOPS, a fast single-stage 3D object detection method for LIDAR data. Previous methods often make domain-specific design decisions, for example projecting points into a bird-eye view image in autonomous driving scenarios. In contrast, we propose a general-purpose method that works on both indoor and outdoor scenes. The core novelty of our method is a fast, single-pass architecture that both detects objects in 3D and estimates their shapes. 3D bounding box parameters are estimated in one pass for every point, aggregated through graph convolutions, and fed into a branch of the network that predicts latent codes representing the shape of each detected object. The latent shape space and shape decoder are learned on a synthetic dataset and then used as supervision for the end-to-end training of the 3D object detection pipeline. Thus our model is able to extract shapes without access to ground-truth shape information in the target dataset. During experiments, we find that our proposed method achieves state-of-the-art results by ~5% on object detection in ScanNet scenes, and it gets top results by 3.4% in the Waymo Open Dataset, while reproducing the shapes of detected cars.
AVA-ActiveSpeaker: An Audio-Visual Dataset for Active Speaker Detection
Jan 05, 2019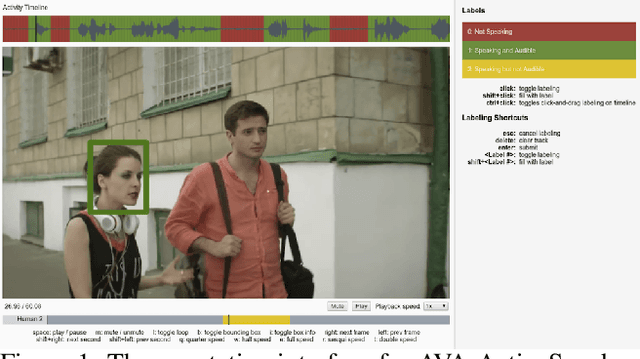
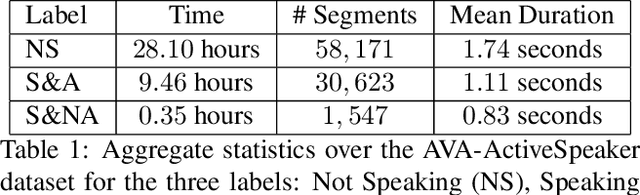

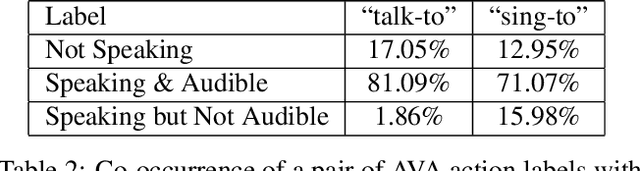
Active speaker detection is an important component in video analysis algorithms for applications such as speaker diarization, video re-targeting for meetings, speech enhancement, and human-robot interaction. The absence of a large, carefully labeled audio-visual dataset for this task has constrained algorithm evaluations with respect to data diversity, environments, and accuracy. This has made comparisons and improvements difficult. In this paper, we present the AVA Active Speaker detection dataset (AVA-ActiveSpeaker) that will be released publicly to facilitate algorithm development and enable comparisons. The dataset contains temporally labeled face tracks in video, where each face instance is labeled as speaking or not, and whether the speech is audible. This dataset contains about 3.65 million human labeled frames or about 38.5 hours of face tracks, and the corresponding audio. We also present a new audio-visual approach for active speaker detection, and analyze its performance, demonstrating both its strength and the contributions of the dataset.
AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
Apr 30, 2018


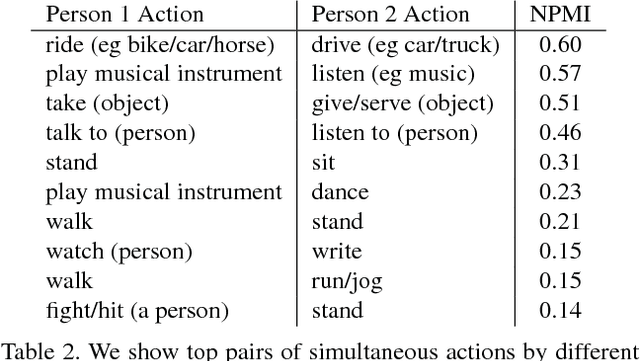
This paper introduces a video dataset of spatio-temporally localized Atomic Visual Actions (AVA). The AVA dataset densely annotates 80 atomic visual actions in 430 15-minute video clips, where actions are localized in space and time, resulting in 1.58M action labels with multiple labels per person occurring frequently. The key characteristics of our dataset are: (1) the definition of atomic visual actions, rather than composite actions; (2) precise spatio-temporal annotations with possibly multiple annotations for each person; (3) exhaustive annotation of these atomic actions over 15-minute video clips; (4) people temporally linked across consecutive segments; and (5) using movies to gather a varied set of action representations. This departs from existing datasets for spatio-temporal action recognition, which typically provide sparse annotations for composite actions in short video clips. We will release the dataset publicly. AVA, with its realistic scene and action complexity, exposes the intrinsic difficulty of action recognition. To benchmark this, we present a novel approach for action localization that builds upon the current state-of-the-art methods, and demonstrates better performance on JHMDB and UCF101-24 categories. While setting a new state of the art on existing datasets, the overall results on AVA are low at 15.6% mAP, underscoring the need for developing new approaches for video understanding.