 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKubric: A scalable dataset generator
Mar 07, 2022

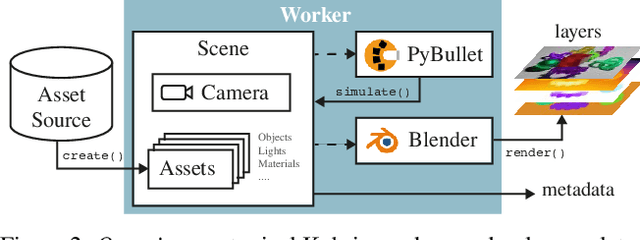
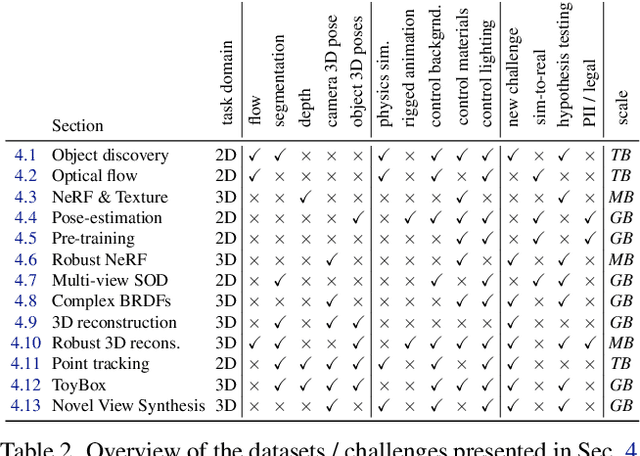
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Quantifying Long Range Dependence in Language and User Behavior to improve RNNs
May 23, 2019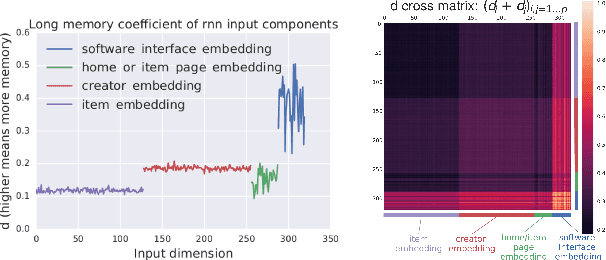
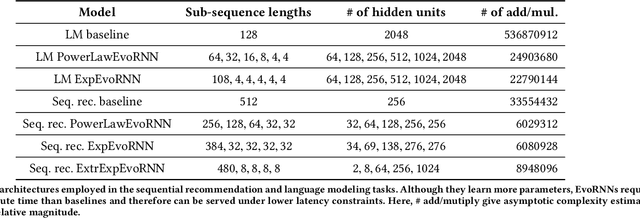
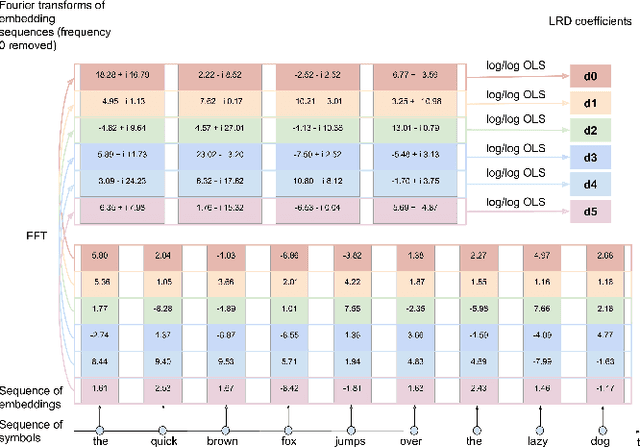

Characterizing temporal dependence patterns is a critical step in understanding the statistical properties of sequential data. Long Range Dependence (LRD) --- referring to long-range correlations decaying as a power law rather than exponentially w.r.t. distance --- demands a different set of tools for modeling the underlying dynamics of the sequential data. While it has been widely conjectured that LRD is present in language modeling and sequential recommendation, the amount of LRD in the corresponding sequential datasets has not yet been quantified in a scalable and model-independent manner. We propose a principled estimation procedure of LRD in sequential datasets based on established LRD theory for real-valued time series and apply it to sequences of symbols with million-item-scale dictionaries. In our measurements, the procedure estimates reliably the LRD in the behavior of users as they write Wikipedia articles and as they interact with YouTube. We further show that measuring LRD better informs modeling decisions in particular for RNNs whose ability to capture LRD is still an active area of research. The quantitative measure informs new Evolutive Recurrent Neural Networks (EvolutiveRNNs) designs, leading to state-of-the-art results on language understanding and sequential recommendation tasks at a fraction of the computational cost.
Scaling Up Collaborative Filtering Data Sets through Randomized Fractal Expansions
Apr 08, 2019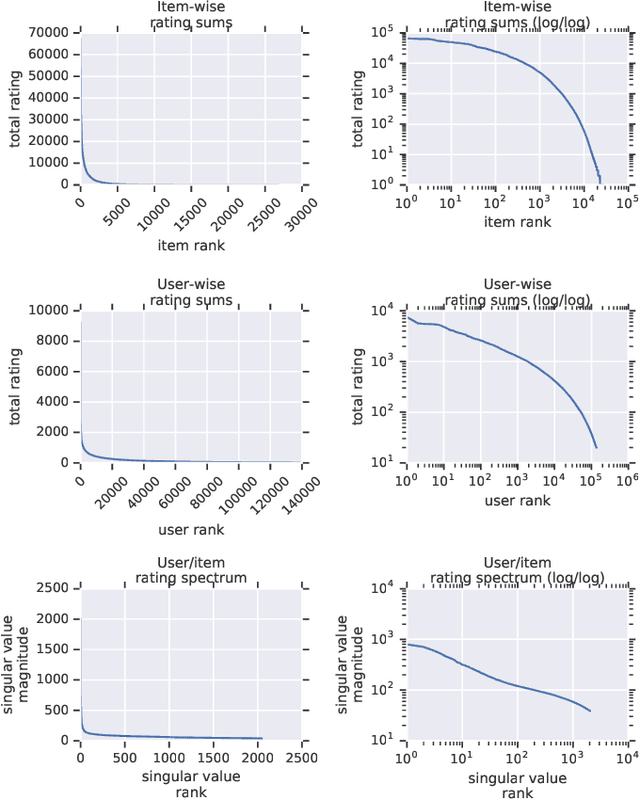
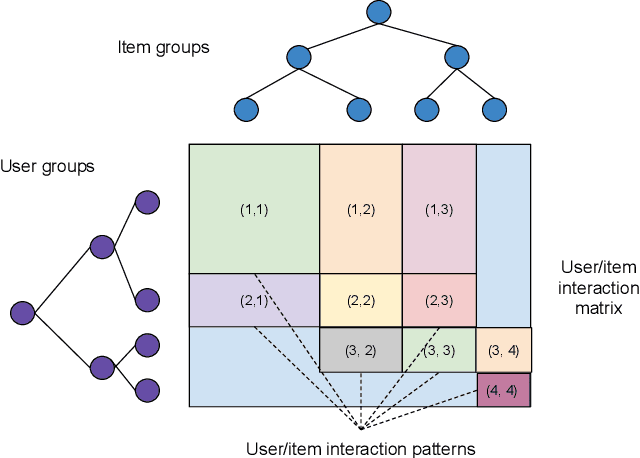
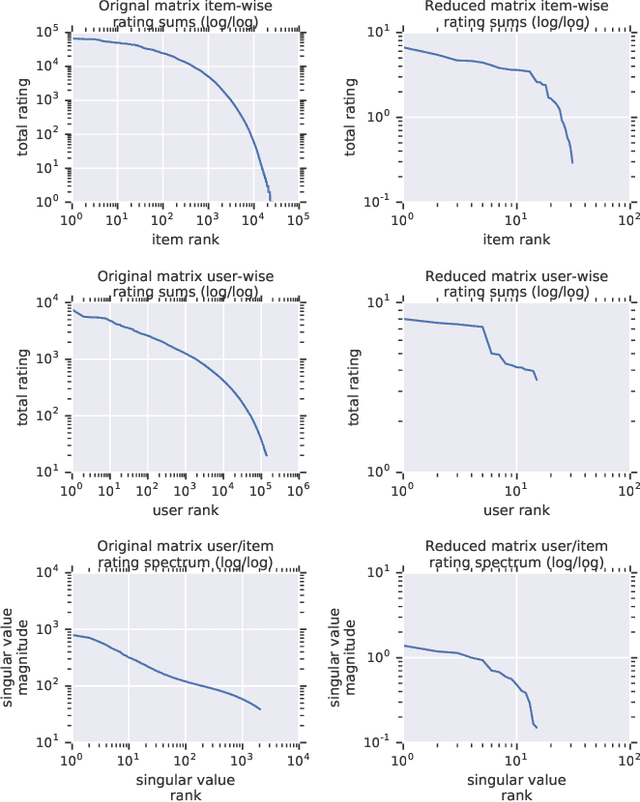
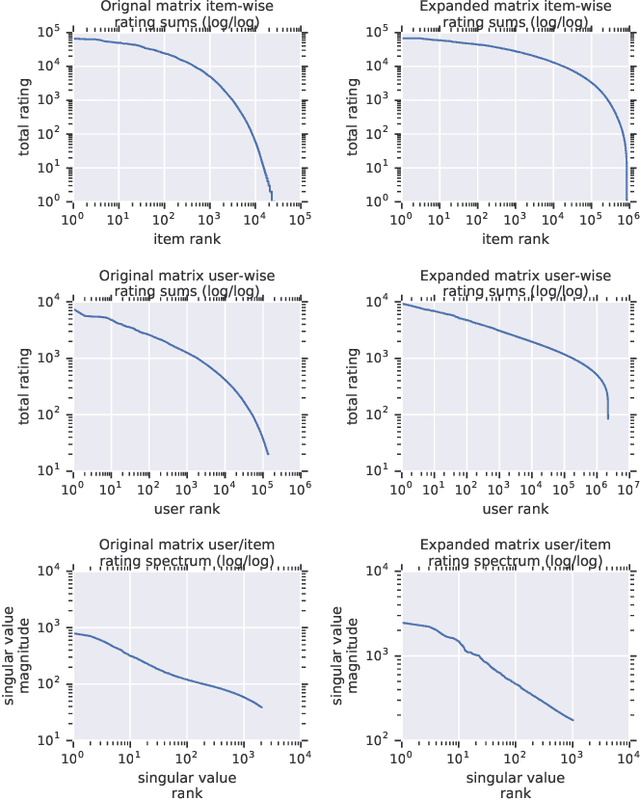
Recommender system research suffers from a disconnect between the size of academic data sets and the scale of industrial production systems. In order to bridge that gap, we propose to generate large-scale user/item interaction data sets by expanding pre-existing public data sets. Our key contribution is a technique that expands user/item incidence matrices matrices to large numbers of rows (users), columns (items), and non-zero values (interactions). The proposed method adapts Kronecker Graph Theory to preserve key higher order statistical properties such as the fat-tailed distribution of user engagements, item popularity, and singular value spectra of user/item interaction matrices. Preserving such properties is key to building large realistic synthetic data sets which in turn can be employed reliably to benchmark recommender systems and the systems employed to train them. We further apply our stochastic expansion algorithm to the binarized MovieLens 20M data set, which comprises 20M interactions between 27K movies and 138K users. The resulting expanded data set has 1.2B ratings, 2.2M users, and 855K items, which can be scaled up or down.
Towards Neural Mixture Recommender for Long Range Dependent User Sequences
Feb 22, 2019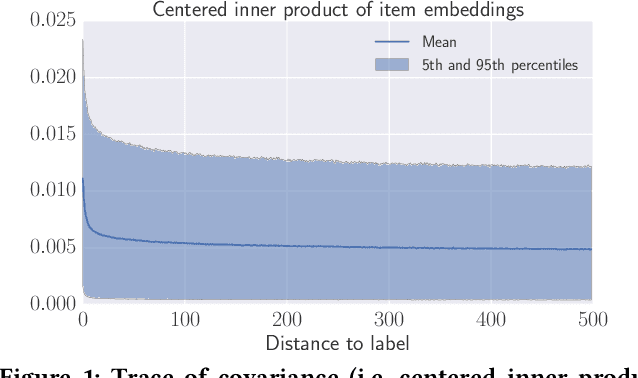

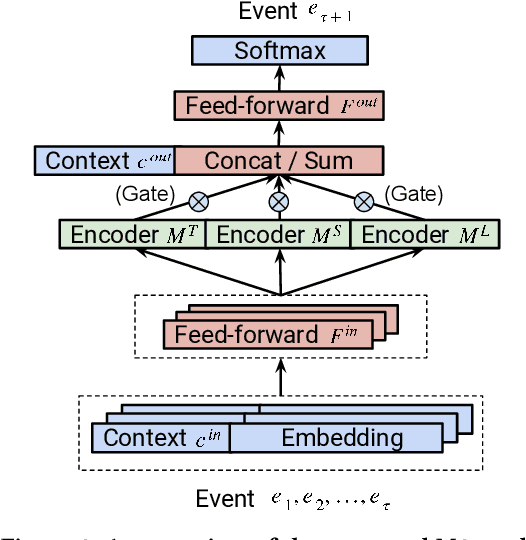
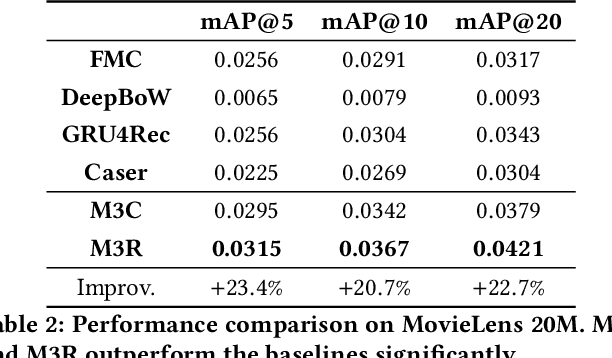
Understanding temporal dynamics has proved to be highly valuable for accurate recommendation. Sequential recommenders have been successful in modeling the dynamics of users and items over time. However, while different model architectures excel at capturing various temporal ranges or dynamics, distinct application contexts require adapting to diverse behaviors. In this paper we examine how to build a model that can make use of different temporal ranges and dynamics depending on the request context. We begin with the analysis of an anonymized Youtube dataset comprising millions of user sequences. We quantify the degree of long-range dependence in these sequences and demonstrate that both short-term and long-term dependent behavioral patterns co-exist. We then propose a neural Multi-temporal-range Mixture Model (M3) as a tailored solution to deal with both short-term and long-term dependencies. Our approach employs a mixture of models, each with a different temporal range. These models are combined by a learned gating mechanism capable of exerting different model combinations given different contextual information. In empirical evaluations on a public dataset and our own anonymized YouTube dataset, M3 consistently outperforms state-of-the-art sequential recommendation methods.
Scalable Realistic Recommendation Datasets through Fractal Expansions
Jan 23, 2019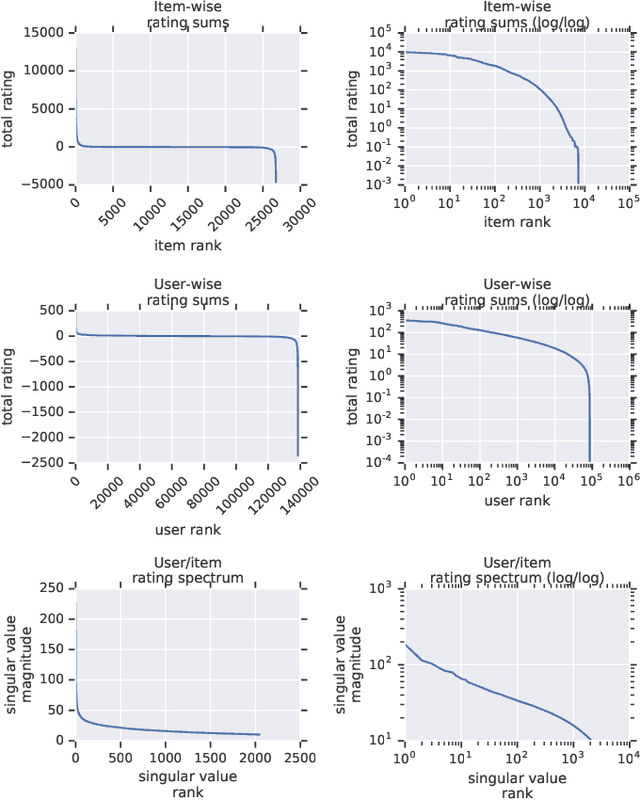
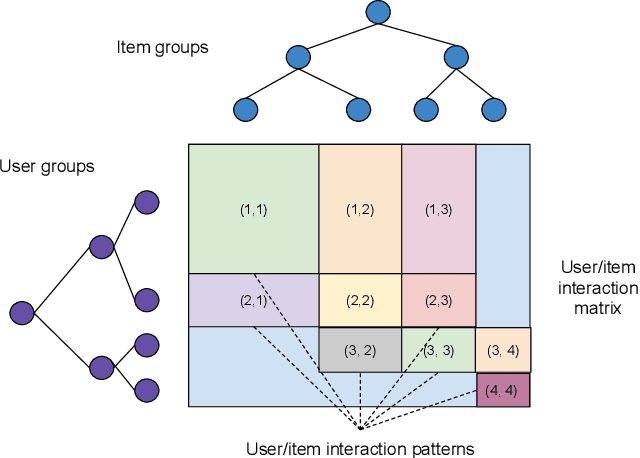
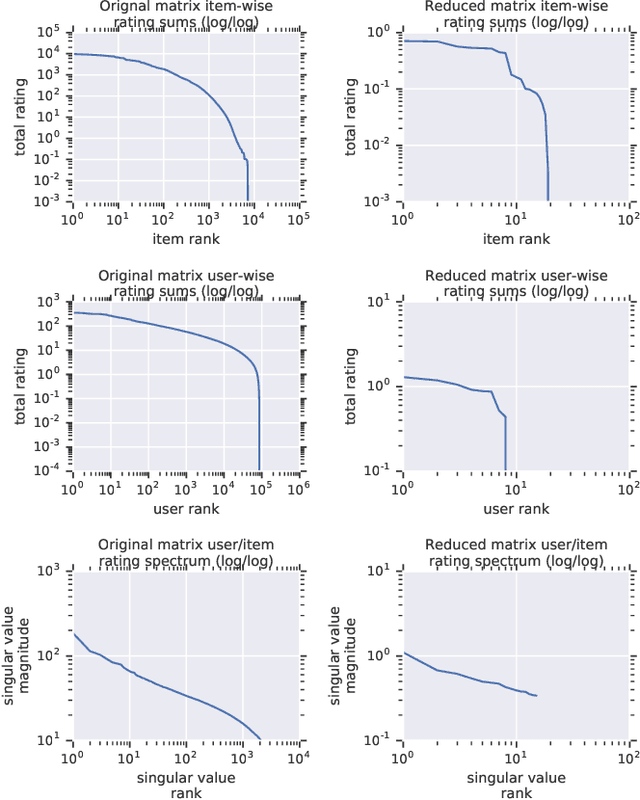
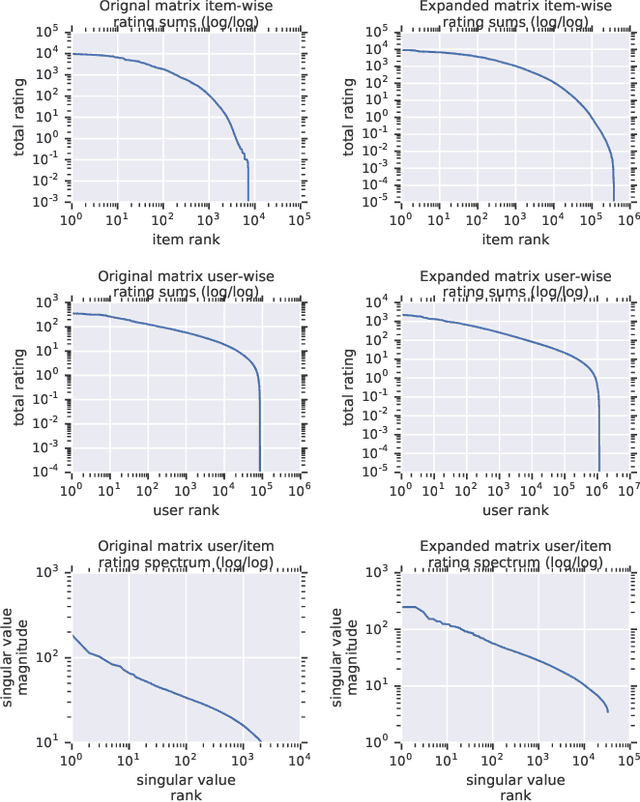
Recommender System research suffers currently from a disconnect between the size of academic data sets and the scale of industrial production systems. In order to bridge that gap we propose to generate more massive user/item interaction data sets by expanding pre-existing public data sets. User/item incidence matrices record interactions between users and items on a given platform as a large sparse matrix whose rows correspond to users and whose columns correspond to items. Our technique expands such matrices to larger numbers of rows (users), columns (items) and non zero values (interactions) while preserving key higher order statistical properties. We adapt the Kronecker Graph Theory to user/item incidence matrices and show that the corresponding fractal expansions preserve the fat-tailed distributions of user engagements, item popularity and singular value spectra of user/item interaction matrices. Preserving such properties is key to building large realistic synthetic data sets which in turn can be employed reliably to benchmark Recommender Systems and the systems employed to train them. We provide algorithms to produce such expansions and apply them to the MovieLens 20 million data set comprising 20 million ratings of 27K movies by 138K users. The resulting expanded data set has 10 billion ratings, 2 million items and 864K users in its smaller version and can be scaled up or down. A larger version features 655 billion ratings, 7 million items and 17 million users.
Top-K Off-Policy Correction for a REINFORCE Recommender System
Dec 06, 2018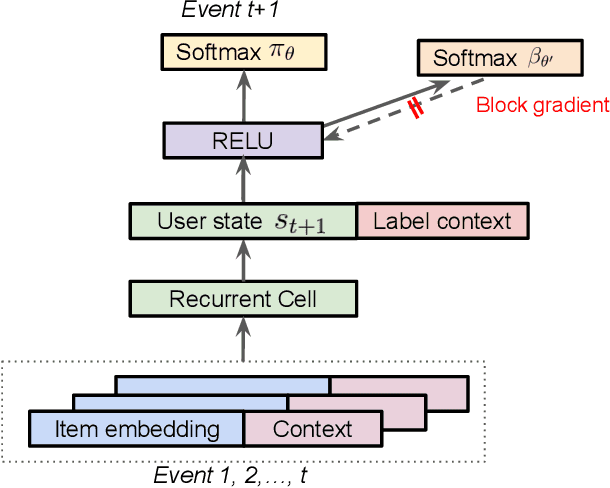
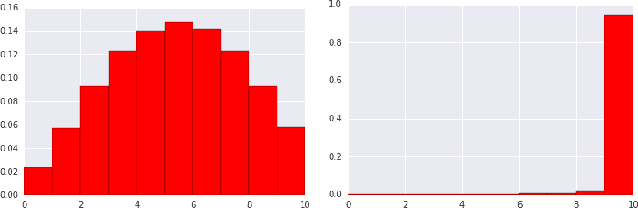
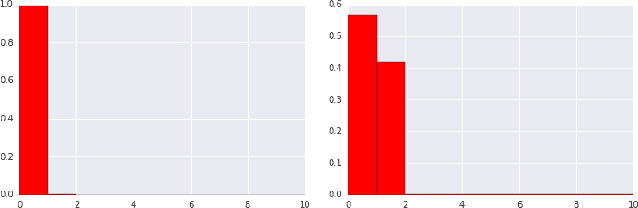
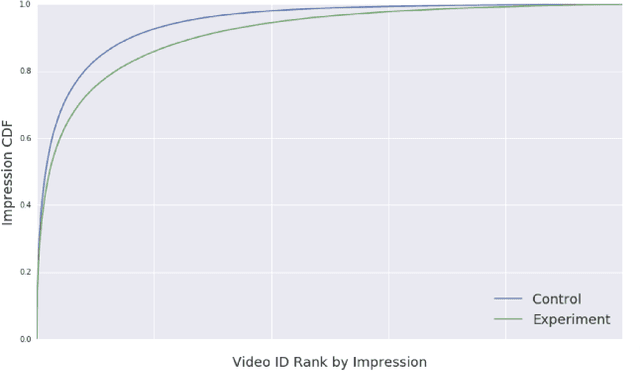
Industrial recommender systems deal with extremely large action spaces -- many millions of items to recommend. Moreover, they need to serve billions of users, who are unique at any point in time, making a complex user state space. Luckily, huge quantities of logged implicit feedback (e.g., user clicks, dwell time) are available for learning. Learning from the logged feedback is however subject to biases caused by only observing feedback on recommendations selected by the previous versions of the recommender. In this work, we present a general recipe of addressing such biases in a production top-K recommender system at Youtube, built with a policy-gradient-based algorithm, i.e. REINFORCE. The contributions of the paper are: (1) scaling REINFORCE to a production recommender system with an action space on the orders of millions; (2) applying off-policy correction to address data biases in learning from logged feedback collected from multiple behavior policies; (3) proposing a novel top-K off-policy correction to account for our policy recommending multiple items at a time; (4) showcasing the value of exploration. We demonstrate the efficacy of our approaches through a series of simulations and multiple live experiments on Youtube.
Expert Level control of Ramp Metering based on Multi-task Deep Reinforcement Learning
Jan 30, 2017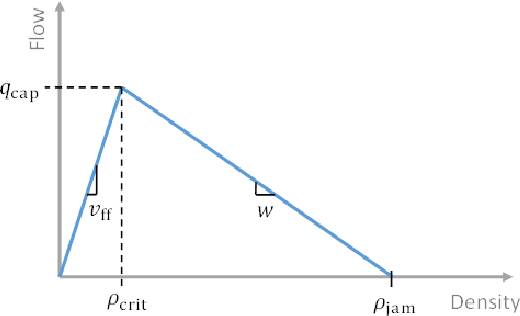
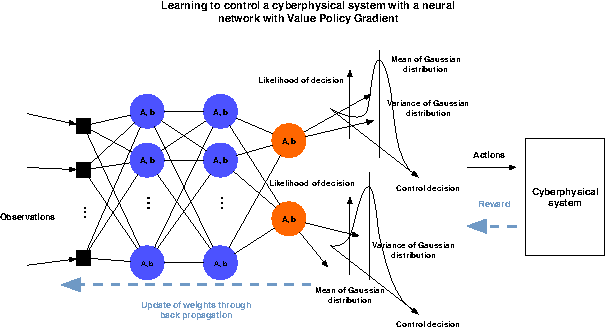
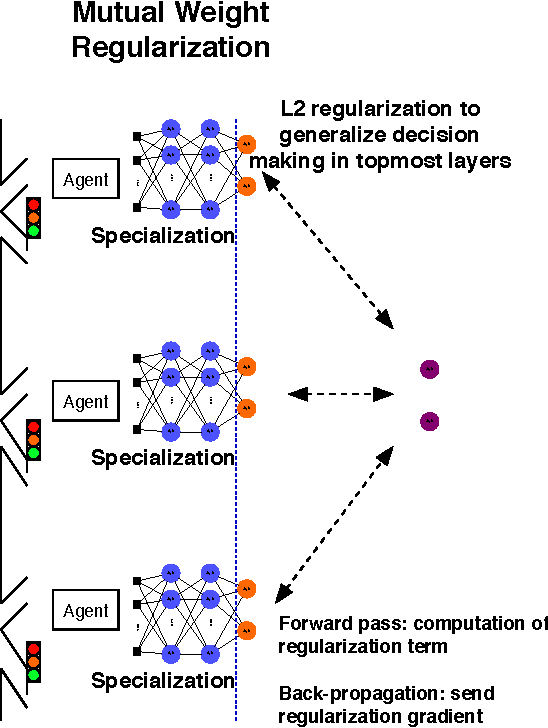
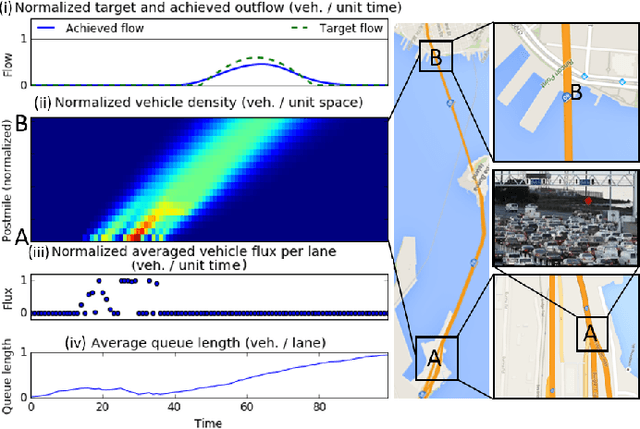
This article shows how the recent breakthroughs in Reinforcement Learning (RL) that have enabled robots to learn to play arcade video games, walk or assemble colored bricks, can be used to perform other tasks that are currently at the core of engineering cyberphysical systems. We present the first use of RL for the control of systems modeled by discretized non-linear Partial Differential Equations (PDEs) and devise a novel algorithm to use non-parametric control techniques for large multi-agent systems. We show how neural network based RL enables the control of discretized PDEs whose parameters are unknown, random, and time-varying. We introduce an algorithm of Mutual Weight Regularization (MWR) which alleviates the curse of dimensionality of multi-agent control schemes by sharing experience between agents while giving each agent the opportunity to specialize its action policy so as to tailor it to the local parameters of the part of the system it is located in.