 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseCraft: Tokenized 3D Body Landmark and Camera Conditioning for Photorealistic Human Image Synthesis
Feb 22, 2026Digitizing humans and synthesizing photorealistic avatars with explicit 3D pose and camera controls are central to VR, telepresence, and entertainment. Existing skinning-based workflows require laborious manual rigging or template-based fittings, while neural volumetric methods rely on canonical templates and re-optimization for each unseen pose. We present PoseCraft, a diffusion framework built around tokenized 3D interface: instead of relying only on rasterized geometry as 2D control images, we encode sparse 3D landmarks and camera extrinsics as discrete conditioning tokens and inject them into diffusion via cross-attention. Our approach preserves 3D semantics by avoiding 2D re-projection ambiguity under large pose and viewpoint changes, and produces photorealistic imagery that faithfully captures identity and appearance. To train and evaluate at scale, we also implement GenHumanRF, a data generation workflow that renders diverse supervision from volumetric reconstructions. Our experiments show that PoseCraft achieves significant perceptual quality improvement over diffusion-centric methods, and attains better or comparable metrics to latest volumetric rendering SOTA while better preserving fabric and hair details.
Learning-guided Kansa collocation for forward and inverse PDEs beyond linearity
Feb 08, 2026Partial Differential Equations are precise in modelling the physical, biological and graphical phenomena. However, the numerical methods suffer from the curse of dimensionality, high computation costs and domain-specific discretization. We aim to explore pros and cons of different PDE solvers, and apply them to specific scientific simulation problems, including forwarding solution, inverse problems and equations discovery. In particular, we extend the recent CNF (NeurIPS 2023) framework solver to multi-dependent-variable and non-linear settings, together with down-stream applications. The outcomes include implementation of selected methods, self-tuning techniques, evaluation on benchmark problems and a comprehensive survey of neural PDE solvers and scientific simulation applications.
Quartet of Diffusions: Structure-Aware Point Cloud Generation through Part and Symmetry Guidance
Jan 28, 2026We introduce the Quartet of Diffusions, a structure-aware point cloud generation framework that explicitly models part composition and symmetry. Unlike prior methods that treat shape generation as a holistic process or only support part composition, our approach leverages four coordinated diffusion models to learn distributions of global shape latents, symmetries, semantic parts, and their spatial assembly. This structured pipeline ensures guaranteed symmetry, coherent part placement, and diverse, high-quality outputs. By disentangling the generative process into interpretable components, our method supports fine-grained control over shape attributes, enabling targeted manipulation of individual parts while preserving global consistency. A central global latent further reinforces structural coherence across assembled parts. Our experiments show that the Quartet achieves state-of-the-art performance. To our best knowledge, this is the first 3D point cloud generation framework that fully integrates and enforces both symmetry and part priors throughout the generative process.
LiteReality: Graphics-Ready 3D Scene Reconstruction from RGB-D Scans
Jul 03, 2025
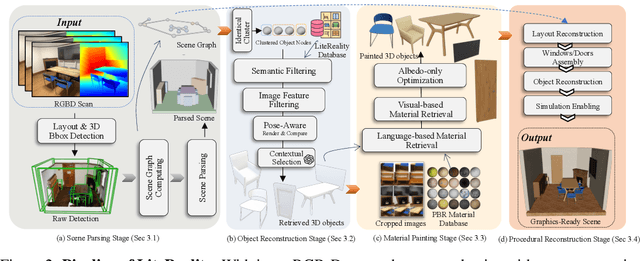
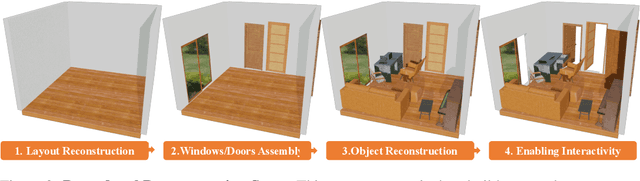
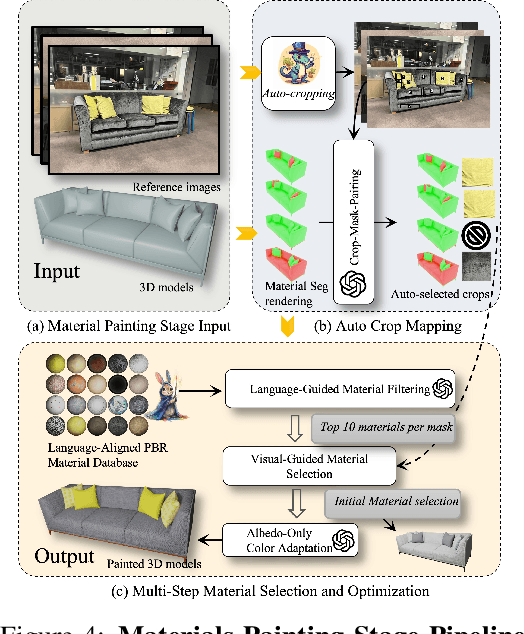
We propose LiteReality, a novel pipeline that converts RGB-D scans of indoor environments into compact, realistic, and interactive 3D virtual replicas. LiteReality not only reconstructs scenes that visually resemble reality but also supports key features essential for graphics pipelines -- such as object individuality, articulation, high-quality physically based rendering materials, and physically based interaction. At its core, LiteReality first performs scene understanding and parses the results into a coherent 3D layout and objects with the help of a structured scene graph. It then reconstructs the scene by retrieving the most visually similar 3D artist-crafted models from a curated asset database. Next, the Material Painting module enhances realism by recovering high-quality, spatially varying materials. Finally, the reconstructed scene is integrated into a simulation engine with basic physical properties to enable interactive behavior. The resulting scenes are compact, editable, and fully compatible with standard graphics pipelines, making them suitable for applications in AR/VR, gaming, robotics, and digital twins. In addition, LiteReality introduces a training-free object retrieval module that achieves state-of-the-art similarity performance on the Scan2CAD benchmark, along with a robust material painting module capable of transferring appearances from images of any style to 3D assets -- even under severe misalignment, occlusion, and poor lighting. We demonstrate the effectiveness of LiteReality on both real-life scans and public datasets. Project page: https://litereality.github.io; Video: https://www.youtube.com/watch?v=ecK9m3LXg2c
CHOrD: Generation of Collision-Free, House-Scale, and Organized Digital Twins for 3D Indoor Scenes with Controllable Floor Plans and Optimal Layouts
Mar 15, 2025We introduce CHOrD, a novel framework for scalable synthesis of 3D indoor scenes, designed to create house-scale, collision-free, and hierarchically structured indoor digital twins. In contrast to existing methods that directly synthesize the scene layout as a scene graph or object list, CHOrD incorporates a 2D image-based intermediate layout representation, enabling effective prevention of collision artifacts by successfully capturing them as out-of-distribution (OOD) scenarios during generation. Furthermore, unlike existing methods, CHOrD is capable of generating scene layouts that adhere to complex floor plans with multi-modal controls, enabling the creation of coherent, house-wide layouts robust to both geometric and semantic variations in room structures. Additionally, we propose a novel dataset with expanded coverage of household items and room configurations, as well as significantly improved data quality. CHOrD demonstrates state-of-the-art performance on both the 3D-FRONT and our proposed datasets, delivering photorealistic, spatially coherent indoor scene synthesis adaptable to arbitrary floor plan variations.
Physically Based Neural Bidirectional Reflectance Distribution Function
Nov 04, 2024We introduce the physically based neural bidirectional reflectance distribution function (PBNBRDF), a novel, continuous representation for material appearance based on neural fields. Our model accurately reconstructs real-world materials while uniquely enforcing physical properties for realistic BRDFs, specifically Helmholtz reciprocity via reparametrization and energy passivity via efficient analytical integration. We conduct a systematic analysis demonstrating the benefits of adhering to these physical laws on the visual quality of reconstructed materials. Additionally, we enhance the color accuracy of neural BRDFs by introducing chromaticity enforcement supervising the norms of RGB channels. Through both qualitative and quantitative experiments on multiple databases of measured real-world BRDFs, we show that adhering to these physical constraints enables neural fields to more faithfully and stably represent the original data and achieve higher rendering quality.
SYM3D: Learning Symmetric Triplanes for Better 3D-Awareness of GANs
Jun 10, 2024



Despite the growing success of 3D-aware GANs, which can be trained on 2D images to generate high-quality 3D assets, they still rely on multi-view images with camera annotations to synthesize sufficient details from all viewing directions. However, the scarce availability of calibrated multi-view image datasets, especially in comparison to single-view images, has limited the potential of 3D GANs. Moreover, while bypassing camera pose annotations with a camera distribution constraint reduces dependence on exact camera parameters, it still struggles to generate a consistent orientation of 3D assets. To this end, we propose SYM3D, a novel 3D-aware GAN designed to leverage the prevalent reflectional symmetry structure found in natural and man-made objects, alongside a proposed view-aware spatial attention mechanism in learning the 3D representation. We evaluate SYM3D on both synthetic (ShapeNet Chairs, Cars, and Airplanes) and real-world datasets (ABO-Chair), demonstrating its superior performance in capturing detailed geometry and texture, even when trained on only single-view images. Finally, we demonstrate the effectiveness of incorporating symmetry regularization in helping reduce artifacts in the modeling of 3D assets in the text-to-3D task.
Gaussian Head & Shoulders: High Fidelity Neural Upper Body Avatars with Anchor Gaussian Guided Texture Warping
May 21, 2024



By equipping the most recent 3D Gaussian Splatting representation with head 3D morphable models (3DMM), existing methods manage to create head avatars with high fidelity. However, most existing methods only reconstruct a head without the body, substantially limiting their application scenarios. We found that naively applying Gaussians to model the clothed chest and shoulders tends to result in blurry reconstruction and noisy floaters under novel poses. This is because of the fundamental limitation of Gaussians and point clouds -- each Gaussian or point can only have a single directional radiance without spatial variance, therefore an unnecessarily large number of them is required to represent complicated spatially varying texture, even for simple geometry. In contrast, we propose to model the body part with a neural texture that consists of coarse and pose-dependent fine colors. To properly render the body texture for each view and pose without accurate geometry nor UV mapping, we optimize another sparse set of Gaussians as anchors that constrain the neural warping field that maps image plane coordinates to the texture space. We demonstrate that Gaussian Head & Shoulders can fit the high-frequency details on the clothed upper body with high fidelity and potentially improve the accuracy and fidelity of the head region. We evaluate our method with casual phone-captured and internet videos and show our method archives superior reconstruction quality and robustness in both self and cross reenactment tasks. To fully utilize the efficient rendering speed of Gaussian splatting, we additionally propose an accelerated inference method of our trained model without Multi-Layer Perceptron (MLP) queries and reach a stable rendering speed of around 130 FPS for any subjects.
Differentiable Visual Computing for Inverse Problems and Machine Learning
Nov 21, 2023Originally designed for applications in computer graphics, visual computing (VC) methods synthesize information about physical and virtual worlds, using prescribed algorithms optimized for spatial computing. VC is used to analyze geometry, physically simulate solids, fluids, and other media, and render the world via optical techniques. These fine-tuned computations that operate explicitly on a given input solve so-called forward problems, VC excels at. By contrast, deep learning (DL) allows for the construction of general algorithmic models, side stepping the need for a purely first principles-based approach to problem solving. DL is powered by highly parameterized neural network architectures -- universal function approximators -- and gradient-based search algorithms which can efficiently search that large parameter space for optimal models. This approach is predicated by neural network differentiability, the requirement that analytic derivatives of a given problem's task metric can be computed with respect to neural network's parameters. Neural networks excel when an explicit model is not known, and neural network training solves an inverse problem in which a model is computed from data.
FrePolad: Frequency-Rectified Point Latent Diffusion for Point Cloud Generation
Nov 20, 2023



We propose FrePolad: frequency-rectified point latent diffusion, a point cloud generation pipeline integrating a variational autoencoder (VAE) with a denoising diffusion probabilistic model (DDPM) for the latent distribution. FrePolad simultaneously achieves high quality, diversity, and flexibility in point cloud cardinality for generation tasks while maintaining high computational efficiency. The improvement in generation quality and diversity is achieved through (1) a novel frequency rectification module via spherical harmonics designed to retain high-frequency content while learning the point cloud distribution; and (2) a latent DDPM to learn the regularized yet complex latent distribution. In addition, FrePolad supports variable point cloud cardinality by formulating the sampling of points as conditional distributions over a latent shape distribution. Finally, the low-dimensional latent space encoded by the VAE contributes to FrePolad's fast and scalable sampling. Our quantitative and qualitative results demonstrate the state-of-the-art performance of FrePolad in terms of quality, diversity, and computational efficiency.