 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Text Recognition with Semantics
Oct 19, 2022
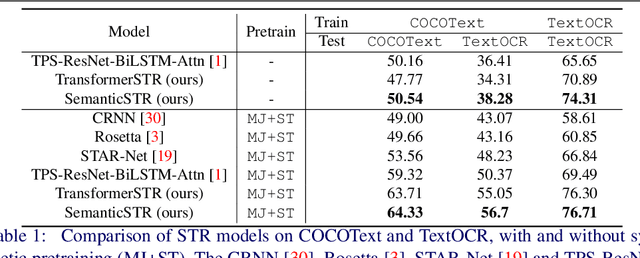
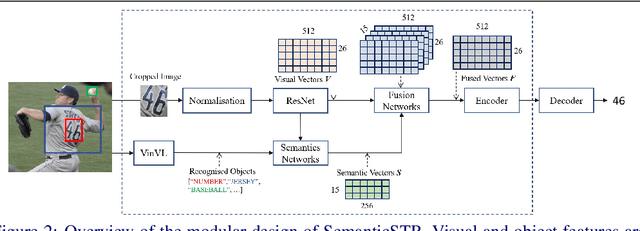
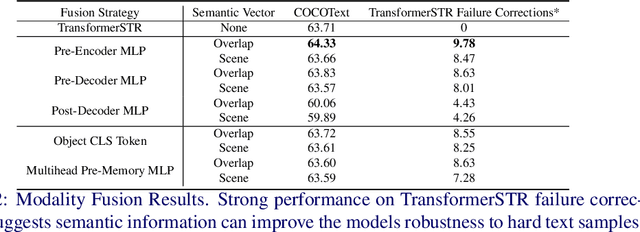
Scene Text Recognition (STR) models have achieved high performance in recent years on benchmark datasets where text images are presented with minimal noise. Traditional STR recognition pipelines take a cropped image as sole input and attempt to identify the characters present. This infrastructure can fail in instances where the input image is noisy or the text is partially obscured. This paper proposes using semantic information from the greater scene to contextualise predictions. We generate semantic vectors using object tags and fuse this information into a transformer-based architecture. The results demonstrate that our multimodal approach yields higher performance than traditional benchmark models, particularly on noisy instances.
Contrastive Video-Language Learning with Fine-grained Frame Sampling
Oct 10, 2022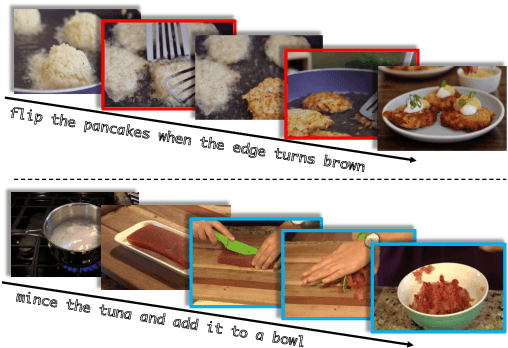
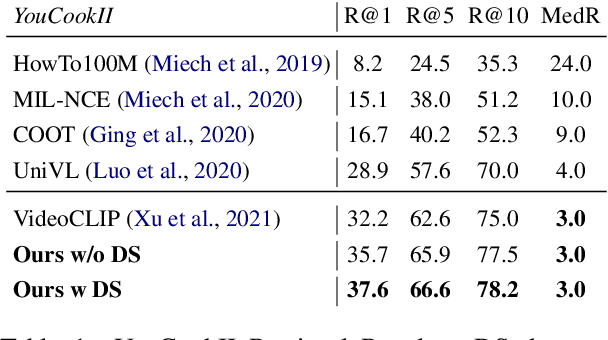
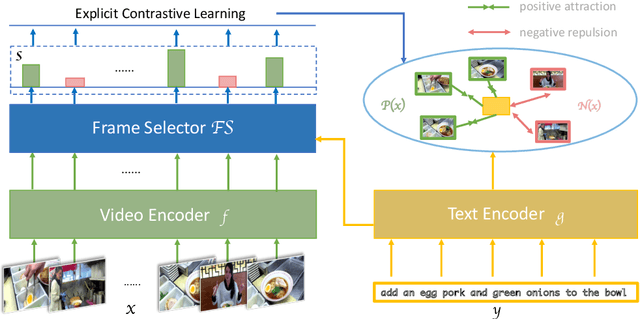
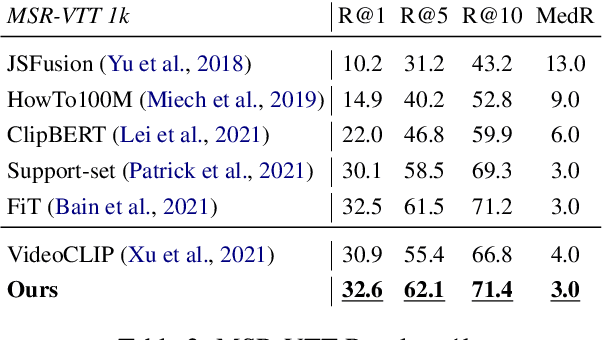
Despite recent progress in video and language representation learning, the weak or sparse correspondence between the two modalities remains a bottleneck in the area. Most video-language models are trained via pair-level loss to predict whether a pair of video and text is aligned. However, even in paired video-text segments, only a subset of the frames are semantically relevant to the corresponding text, with the remainder representing noise; where the ratio of noisy frames is higher for longer videos. We propose FineCo (Fine-grained Contrastive Loss for Frame Sampling), an approach to better learn video and language representations with a fine-grained contrastive objective operating on video frames. It helps distil a video by selecting the frames that are semantically equivalent to the text, improving cross-modal correspondence. Building on the well established VideoCLIP model as a starting point, FineCo achieves state-of-the-art performance on YouCookII, a text-video retrieval benchmark with long videos. FineCo also achieves competitive results on text-video retrieval (MSR-VTT), and video question answering datasets (MSR-VTT QA and MSR-VTT MC) with shorter videos.
Logically Consistent Adversarial Attacks for Soft Theorem Provers
Apr 29, 2022
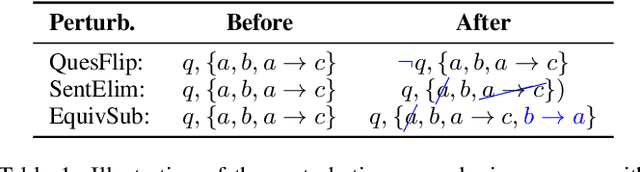
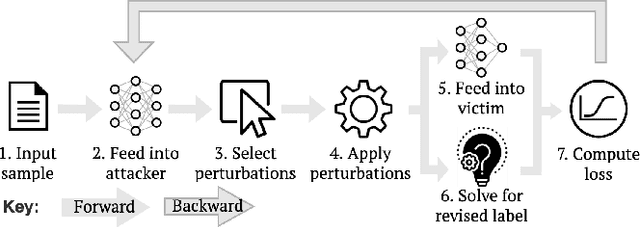
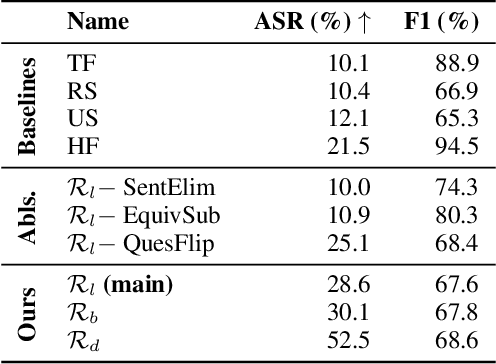
Recent efforts within the AI community have yielded impressive results towards "soft theorem proving" over natural language sentences using language models. We propose a novel, generative adversarial framework for probing and improving these models' reasoning capabilities. Adversarial attacks in this domain suffer from the logical inconsistency problem, whereby perturbations to the input may alter the label. Our Logically consistent AdVersarial Attacker, LAVA, addresses this by combining a structured generative process with a symbolic solver, guaranteeing logical consistency. Our framework successfully generates adversarial attacks and identifies global weaknesses common across multiple target models. Our analyses reveal naive heuristics and vulnerabilities in these models' reasoning capabilities, exposing an incomplete grasp of logical deduction under logic programs. Finally, in addition to effective probing of these models, we show that training on the generated samples improves the target model's performance.
Kubric: A scalable dataset generator
Mar 07, 2022

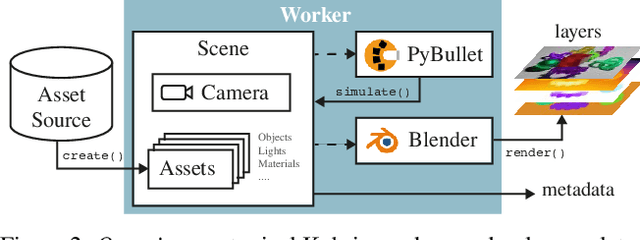
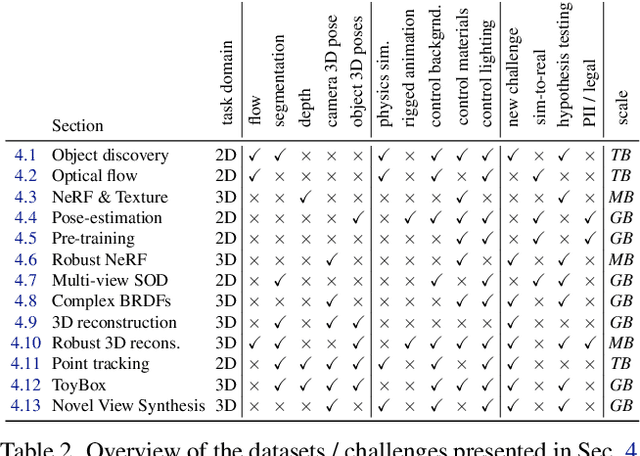
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Guiding Visual Question Generation
Oct 15, 2021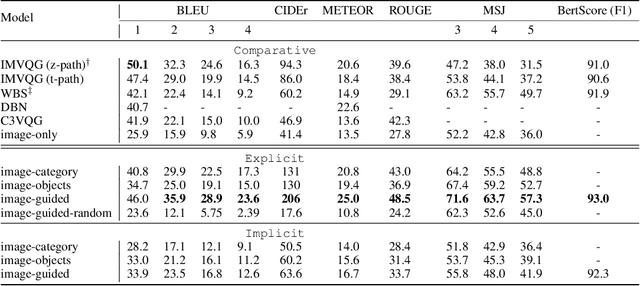
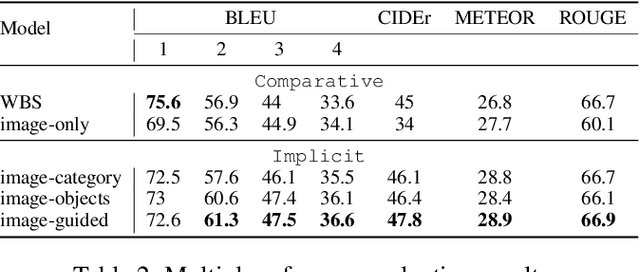


In traditional Visual Question Generation (VQG), most images have multiple concepts (e.g. objects and categories) for which a question could be generated, but models are trained to mimic an arbitrary choice of concept as given in their training data. This makes training difficult and also poses issues for evaluation -- multiple valid questions exist for most images but only one or a few are captured by the human references. We present Guiding Visual Question Generation - a variant of VQG which conditions the question generator on categorical information based on expectations on the type of question and the objects it should explore. We propose two variants: (i) an explicitly guided model that enables an actor (human or automated) to select which objects and categories to generate a question for; and (ii) an implicitly guided model that learns which objects and categories to condition on, based on discrete latent variables. The proposed models are evaluated on an answer-category augmented VQA dataset and our quantitative results show a substantial improvement over the current state of the art (over 9 BLEU-4 increase). Human evaluation validates that guidance helps the generation of questions that are grammatically coherent and relevant to the given image and objects.
Cross-Modal Generative Augmentation for Visual Question Answering
May 11, 2021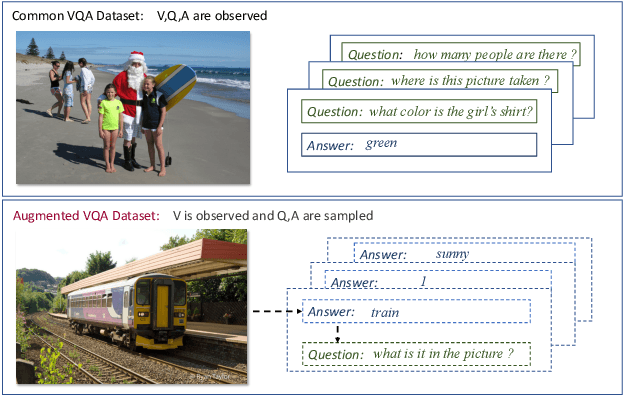
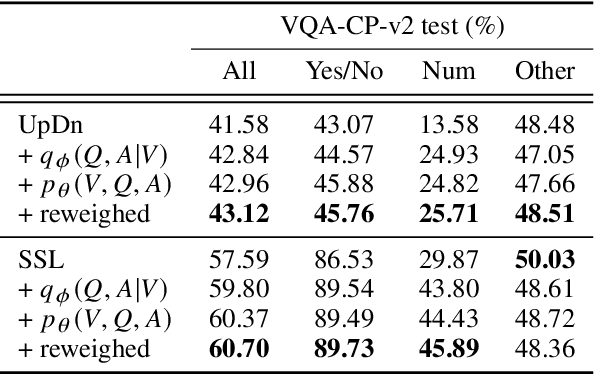
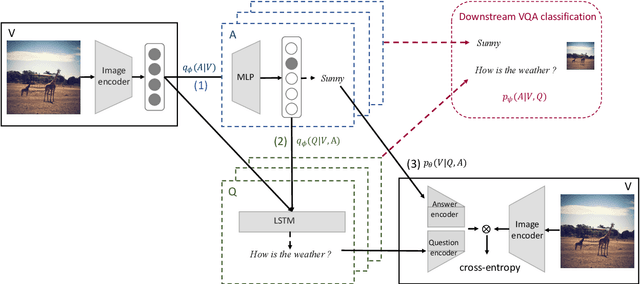
Data augmentation is an approach that can effectively improve the performance of multimodal machine learning. This paper introduces a generative model for data augmentation by leveraging the correlations among multiple modalities. Different from conventional data augmentation approaches that apply low level operations with deterministic heuristics, our method proposes to learn an augmentation sampler that generates samples of the target modality conditioned on observed modalities in the variational auto-encoder framework. Additionally, the proposed model is able to quantify the confidence of augmented data by its generative probability, and can be jointly updated with a downstream pipeline. Experiments on Visual Question Answering tasks demonstrate the effectiveness of the proposed generative model, which is able to boost the strong UpDn-based models to the state-of-the-art performance.
Exploiting Multimodal Reinforcement Learning for Simultaneous Machine Translation
Feb 22, 2021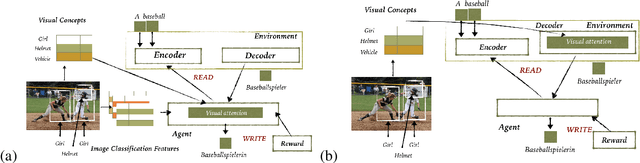
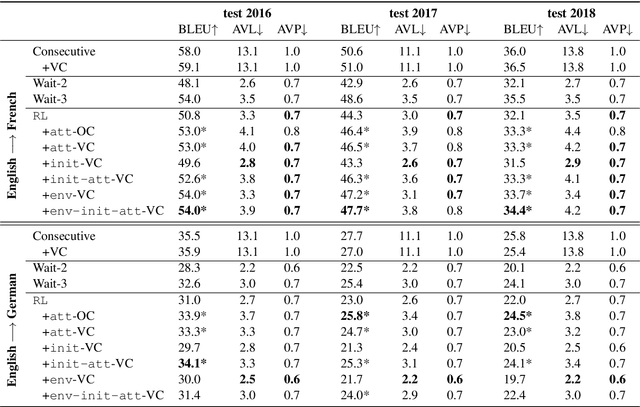
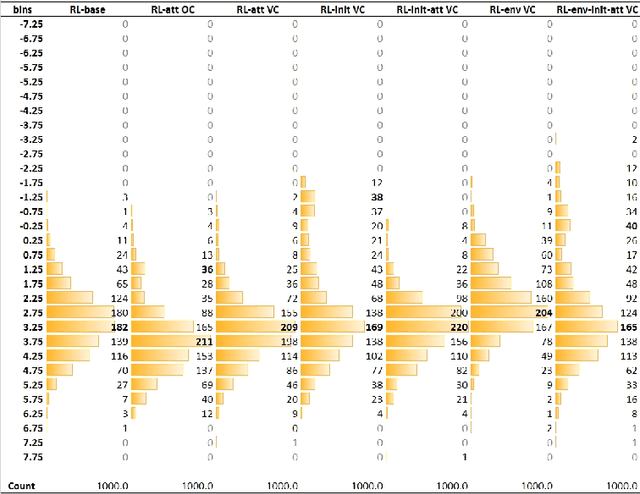

This paper addresses the problem of simultaneous machine translation (SiMT) by exploring two main concepts: (a) adaptive policies to learn a good trade-off between high translation quality and low latency; and (b) visual information to support this process by providing additional (visual) contextual information which may be available before the textual input is produced. For that, we propose a multimodal approach to simultaneous machine translation using reinforcement learning, with strategies to integrate visual and textual information in both the agent and the environment. We provide an exploration on how different types of visual information and integration strategies affect the quality and latency of simultaneous translation models, and demonstrate that visual cues lead to higher quality while keeping the latency low.
Latent Variable Models for Visual Question Answering
Jan 16, 2021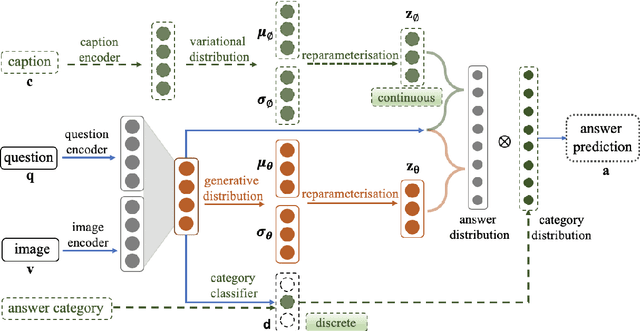
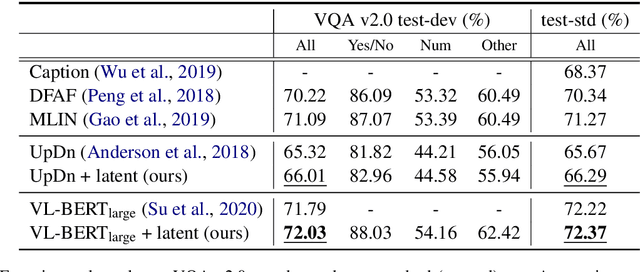

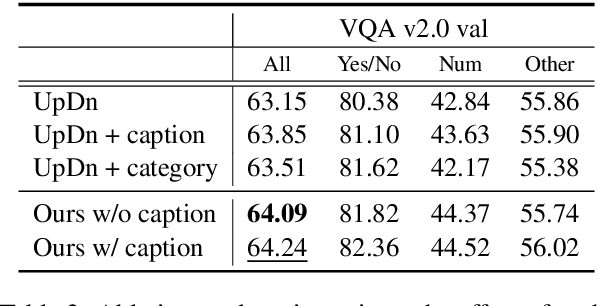
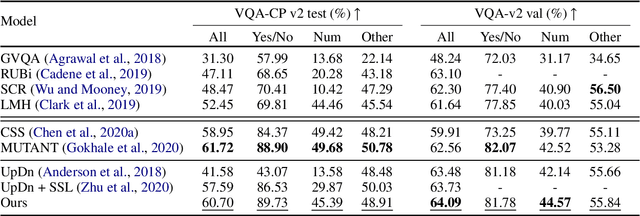
Conventional models for Visual Question Answering (VQA) explore deterministic approaches with various types of image features, question features, and attention mechanisms. However, there exist other modalities that can be explored in addition to image and question pairs to bring extra information to the models. In this work, we propose latent variable models for VQA where extra information (e.g. captions and answer categories) are incorporated as latent variables to improve inference, which in turn benefits question-answering performance. Experiments on the VQA v2.0 benchmarking dataset demonstrate the effectiveness of our proposed models in that they improve over strong baselines, especially those that do not rely on extensive language-vision pre-training.
Watch and Learn: Mapping Language and Noisy Real-world Videos with Self-supervision
Nov 19, 2020
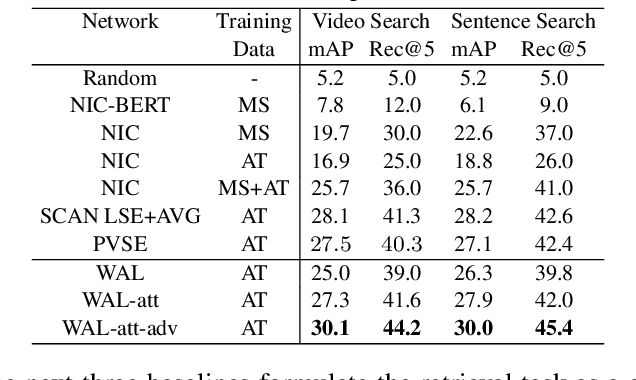
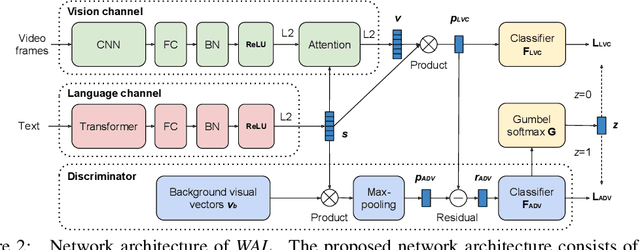
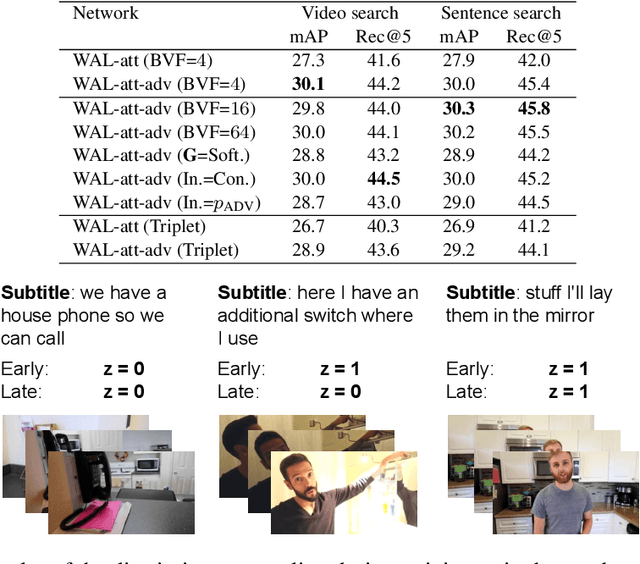
In this paper, we teach machines to understand visuals and natural language by learning the mapping between sentences and noisy video snippets without explicit annotations. Firstly, we define a self-supervised learning framework that captures the cross-modal information. A novel adversarial learning module is then introduced to explicitly handle the noises in the natural videos, where the subtitle sentences are not guaranteed to be strongly corresponded to the video snippets. For training and evaluation, we contribute a new dataset `ApartmenTour' that contains a large number of online videos and subtitles. We carry out experiments on the bidirectional retrieval tasks between sentences and videos, and the results demonstrate that our proposed model achieves the state-of-the-art performance on both retrieval tasks and exceeds several strong baselines. The dataset will be released soon.
Selective Sensor Fusion for Neural Visual-Inertial Odometry
Mar 04, 2019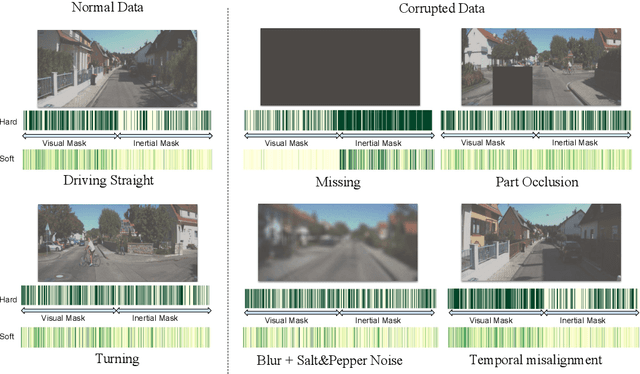
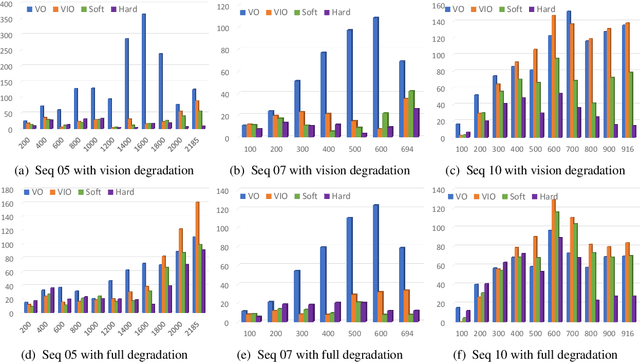
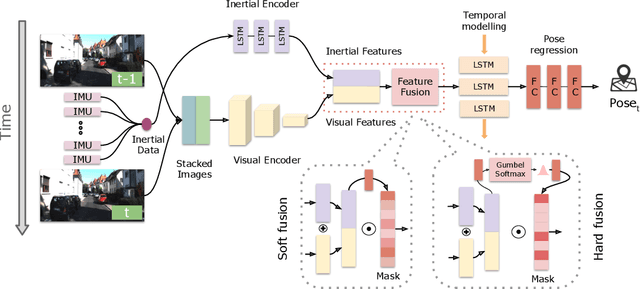
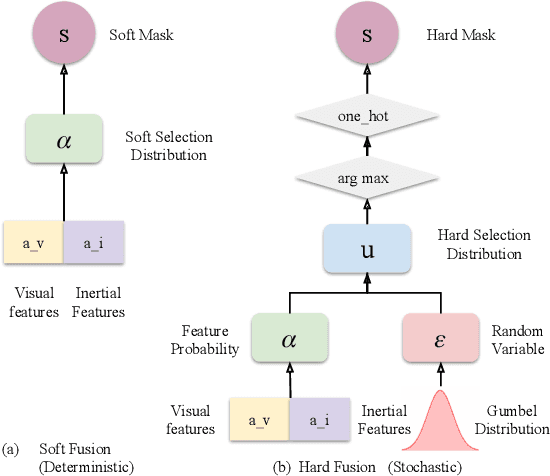
Deep learning approaches for Visual-Inertial Odometry (VIO) have proven successful, but they rarely focus on incorporating robust fusion strategies for dealing with imperfect input sensory data. We propose a novel end-to-end selective sensor fusion framework for monocular VIO, which fuses monocular images and inertial measurements in order to estimate the trajectory whilst improving robustness to real-life issues, such as missing and corrupted data or bad sensor synchronization. In particular, we propose two fusion modalities based on different masking strategies: deterministic soft fusion and stochastic hard fusion, and we compare with previously proposed direct fusion baselines. During testing, the network is able to selectively process the features of the available sensor modalities and produce a trajectory at scale. We present a thorough investigation on the performances on three public autonomous driving, Micro Aerial Vehicle (MAV) and hand-held VIO datasets. The results demonstrate the effectiveness of the fusion strategies, which offer better performances compared to direct fusion, particularly in presence of corrupted data. In addition, we study the interpretability of the fusion networks by visualising the masking layers in different scenarios and with varying data corruption, revealing interesting correlations between the fusion networks and imperfect sensory input data.