 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Training Dynamics: Identifying Mislabeled Data Beyond Manually Designed Features
Dec 20, 2022



While mislabeled or ambiguously-labeled samples in the training set could negatively affect the performance of deep models, diagnosing the dataset and identifying mislabeled samples helps to improve the generalization power. Training dynamics, i.e., the traces left by iterations of optimization algorithms, have recently been proved to be effective to localize mislabeled samples with hand-crafted features. In this paper, beyond manually designed features, we introduce a novel learning-based solution, leveraging a noise detector, instanced by an LSTM network, which learns to predict whether a sample was mislabeled using the raw training dynamics as input. Specifically, the proposed method trains the noise detector in a supervised manner using the dataset with synthesized label noises and can adapt to various datasets (either naturally or synthesized label-noised) without retraining. We conduct extensive experiments to evaluate the proposed method. We train the noise detector based on the synthesized label-noised CIFAR dataset and test such noise detector on Tiny ImageNet, CUB-200, Caltech-256, WebVision and Clothing1M. Results show that the proposed method precisely detects mislabeled samples on various datasets without further adaptation, and outperforms state-of-the-art methods. Besides, more experiments demonstrate that the mislabel identification can guide a label correction, namely data debugging, providing orthogonal improvements of algorithm-centric state-of-the-art techniques from the data aspect.
Temporal Output Discrepancy for Loss Estimation-based Active Learning
Dec 20, 2022



While deep learning succeeds in a wide range of tasks, it highly depends on the massive collection of annotated data which is expensive and time-consuming. To lower the cost of data annotation, active learning has been proposed to interactively query an oracle to annotate a small proportion of informative samples in an unlabeled dataset. Inspired by the fact that the samples with higher loss are usually more informative to the model than the samples with lower loss, in this paper we present a novel deep active learning approach that queries the oracle for data annotation when the unlabeled sample is believed to incorporate high loss. The core of our approach is a measurement Temporal Output Discrepancy (TOD) that estimates the sample loss by evaluating the discrepancy of outputs given by models at different optimization steps. Our theoretical investigation shows that TOD lower-bounds the accumulated sample loss thus it can be used to select informative unlabeled samples. On basis of TOD, we further develop an effective unlabeled data sampling strategy as well as an unsupervised learning criterion for active learning. Due to the simplicity of TOD, our methods are efficient, flexible, and task-agnostic. Extensive experimental results demonstrate that our approach achieves superior performances than the state-of-the-art active learning methods on image classification and semantic segmentation tasks. In addition, we show that TOD can be utilized to select the best model of potentially the highest testing accuracy from a pool of candidate models.
A Contextual Master-Slave Framework on Urban Region Graph for Urban Village Detection
Nov 26, 2022



Urban villages (UVs) refer to the underdeveloped informal settlement falling behind the rapid urbanization in a city. Since there are high levels of social inequality and social risks in these UVs, it is critical for city managers to discover all UVs for making appropriate renovation policies. Existing approaches to detecting UVs are labor-intensive or have not fully addressed the unique challenges in UV detection such as the scarcity of labeled UVs and the diverse urban patterns in different regions. To this end, we first build an urban region graph (URG) to model the urban area in a hierarchically structured way. Then, we design a novel contextual master-slave framework to effectively detect the urban village from the URG. The core idea of such a framework is to firstly pre-train a basis (or master) model over the URG, and then to adaptively derive specific (or slave) models from the basis model for different regions. The proposed framework can learn to balance the generality and specificity for UV detection in an urban area. Finally, we conduct extensive experiments in three cities to demonstrate the effectiveness of our approach.
Multi-Job Intelligent Scheduling with Cross-Device Federated Learning
Nov 24, 2022



Recent years have witnessed a large amount of decentralized data in various (edge) devices of end-users, while the decentralized data aggregation remains complicated for machine learning jobs because of regulations and laws. As a practical approach to handling decentralized data, Federated Learning (FL) enables collaborative global machine learning model training without sharing sensitive raw data. The servers schedule devices to jobs within the training process of FL. In contrast, device scheduling with multiple jobs in FL remains a critical and open problem. In this paper, we propose a novel multi-job FL framework, which enables the training process of multiple jobs in parallel. The multi-job FL framework is composed of a system model and a scheduling method. The system model enables a parallel training process of multiple jobs, with a cost model based on the data fairness and the training time of diverse devices during the parallel training process. We propose a novel intelligent scheduling approach based on multiple scheduling methods, including an original reinforcement learning-based scheduling method and an original Bayesian optimization-based scheduling method, which corresponds to a small cost while scheduling devices to multiple jobs. We conduct extensive experimentation with diverse jobs and datasets. The experimental results reveal that our proposed approaches significantly outperform baseline approaches in terms of training time (up to 12.73 times faster) and accuracy (up to 46.4% higher).
Textual Data Augmentation for Patient Outcomes Prediction
Nov 13, 2022



Deep learning models have demonstrated superior performance in various healthcare applications. However, the major limitation of these deep models is usually the lack of high-quality training data due to the private and sensitive nature of this field. In this study, we propose a novel textual data augmentation method to generate artificial clinical notes in patients' Electronic Health Records (EHRs) that can be used as additional training data for patient outcomes prediction. Essentially, we fine-tune the generative language model GPT-2 to synthesize labeled text with the original training data. More specifically, We propose a teacher-student framework where we first pre-train a teacher model on the original data, and then train a student model on the GPT-augmented data under the guidance of the teacher. We evaluate our method on the most common patient outcome, i.e., the 30-day readmission rate. The experimental results show that deep models can improve their predictive performance with the augmented data, indicating the effectiveness of the proposed architecture.
SDWPF: A Dataset for Spatial Dynamic Wind Power Forecasting Challenge at KDD Cup 2022
Aug 08, 2022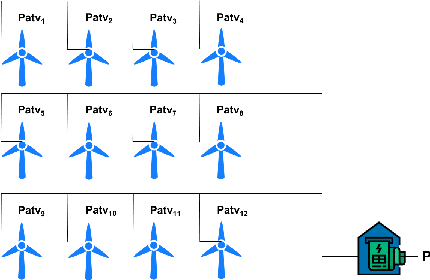


The variability of wind power supply can present substantial challenges to incorporating wind power into a grid system. Thus, Wind Power Forecasting (WPF) has been widely recognized as one of the most critical issues in wind power integration and operation. There has been an explosion of studies on wind power forecasting problems in the past decades. Nevertheless, how to well handle the WPF problem is still challenging, since high prediction accuracy is always demanded to ensure grid stability and security of supply. We present a unique Spatial Dynamic Wind Power Forecasting dataset: SDWPF, which includes the spatial distribution of wind turbines, as well as the dynamic context factors. Whereas, most of the existing datasets have only a small number of wind turbines without knowing the locations and context information of wind turbines at a fine-grained time scale. By contrast, SDWPF provides the wind power data of 134 wind turbines from a wind farm over half a year with their relative positions and internal statuses. We use this dataset to launch the Baidu KDD Cup 2022 to examine the limit of current WPF solutions. The dataset is released at https://aistudio.baidu.com/aistudio/competition/detail/152/0/datasets.
$\textbf{P$^2$A}$: A Dataset and Benchmark for Dense Action Detection from Table Tennis Match Broadcasting Videos
Jul 26, 2022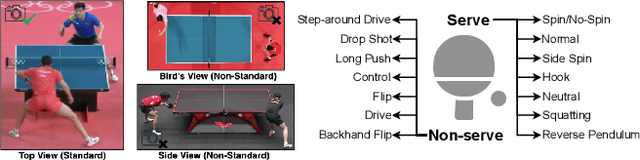
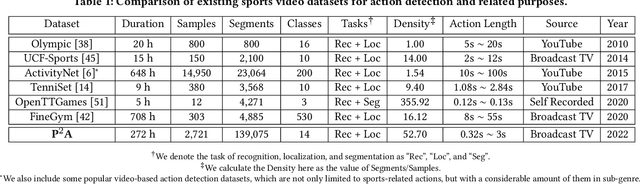

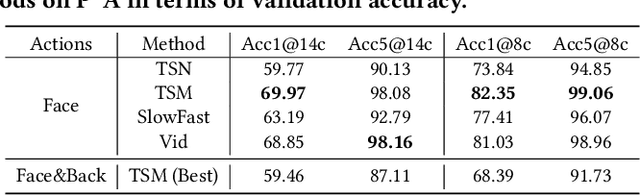
While deep learning has been widely used for video analytics, such as video classification and action detection, dense action detection with fast-moving subjects from sports videos is still challenging. In this work, we release yet another sports video dataset $\textbf{P$^2$A}$ for $\underline{P}$ing $\underline{P}$ong-$\underline{A}$ction detection, which consists of 2,721 video clips collected from the broadcasting videos of professional table tennis matches in World Table Tennis Championships and Olympiads. We work with a crew of table tennis professionals and referees to obtain fine-grained action labels (in 14 classes) for every ping-pong action that appeared in the dataset and formulate two sets of action detection problems - action localization and action recognition. We evaluate a number of commonly-seen action recognition (e.g., TSM, TSN, Video SwinTransformer, and Slowfast) and action localization models (e.g., BSN, BSN++, BMN, TCANet), using $\textbf{P$^2$A}$ for both problems, under various settings. These models can only achieve 48% area under the AR-AN curve for localization and 82% top-one accuracy for recognition since the ping-pong actions are dense with fast-moving subjects but broadcasting videos are with only 25 FPS. The results confirm that $\textbf{P$^2$A}$ is still a challenging task and can be used as a benchmark for action detection from videos.
Accelerated Federated Learning with Decoupled Adaptive Optimization
Jul 14, 2022
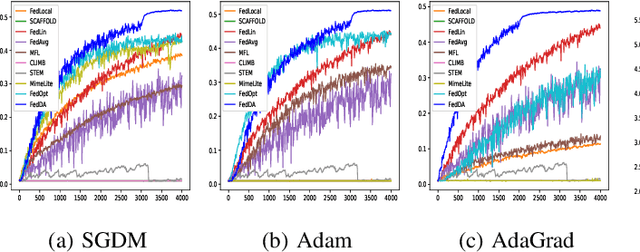
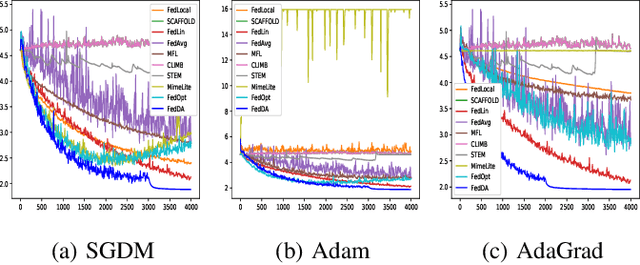
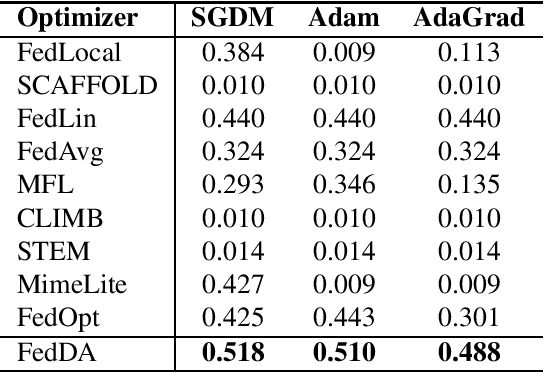
The federated learning (FL) framework enables edge clients to collaboratively learn a shared inference model while keeping privacy of training data on clients. Recently, many heuristics efforts have been made to generalize centralized adaptive optimization methods, such as SGDM, Adam, AdaGrad, etc., to federated settings for improving convergence and accuracy. However, there is still a paucity of theoretical principles on where to and how to design and utilize adaptive optimization methods in federated settings. This work aims to develop novel adaptive optimization methods for FL from the perspective of dynamics of ordinary differential equations (ODEs). First, an analytic framework is established to build a connection between federated optimization methods and decompositions of ODEs of corresponding centralized optimizers. Second, based on this analytic framework, a momentum decoupling adaptive optimization method, FedDA, is developed to fully utilize the global momentum on each local iteration and accelerate the training convergence. Last but not least, full batch gradients are utilized to mimic centralized optimization in the end of the training process to ensure the convergence and overcome the possible inconsistency caused by adaptive optimization methods.
Large-scale Knowledge Distillation with Elastic Heterogeneous Computing Resources
Jul 14, 2022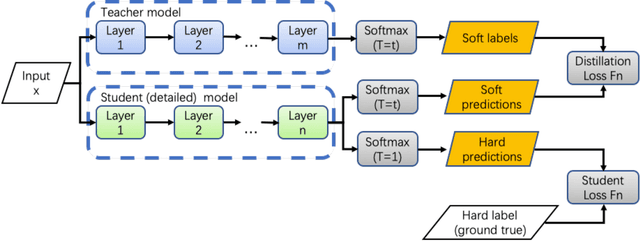

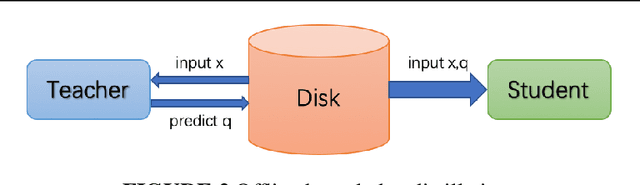
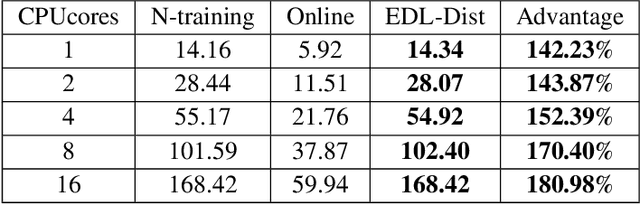
Although more layers and more parameters generally improve the accuracy of the models, such big models generally have high computational complexity and require big memory, which exceed the capacity of small devices for inference and incurs long training time. In addition, it is difficult to afford long training time and inference time of big models even in high performance servers, as well. As an efficient approach to compress a large deep model (a teacher model) to a compact model (a student model), knowledge distillation emerges as a promising approach to deal with the big models. Existing knowledge distillation methods cannot exploit the elastic available computing resources and correspond to low efficiency. In this paper, we propose an Elastic Deep Learning framework for knowledge Distillation, i.e., EDL-Dist. The advantages of EDL-Dist are three-fold. First, the inference and the training process is separated. Second, elastic available computing resources can be utilized to improve the efficiency. Third, fault-tolerance of the training and inference processes is supported. We take extensive experimentation to show that the throughput of EDL-Dist is up to 3.125 times faster than the baseline method (online knowledge distillation) while the accuracy is similar or higher.
Distilling Ensemble of Explanations for Weakly-Supervised Pre-Training of Image Segmentation Models
Jul 04, 2022While fine-tuning pre-trained networks has become a popular way to train image segmentation models, such backbone networks for image segmentation are frequently pre-trained using image classification source datasets, e.g., ImageNet. Though image classification datasets could provide the backbone networks with rich visual features and discriminative ability, they are incapable of fully pre-training the target model (i.e., backbone+segmentation modules) in an end-to-end manner. The segmentation modules are left to random initialization in the fine-tuning process due to the lack of segmentation labels in classification datasets. In our work, we propose a method that leverages Pseudo Semantic Segmentation Labels (PSSL), to enable the end-to-end pre-training for image segmentation models based on classification datasets. PSSL was inspired by the observation that the explanation results of classification models, obtained through explanation algorithms such as CAM, SmoothGrad and LIME, would be close to the pixel clusters of visual objects. Specifically, PSSL is obtained for each image by interpreting the classification results and aggregating an ensemble of explanations queried from multiple classifiers to lower the bias caused by single models. With PSSL for every image of ImageNet, the proposed method leverages a weighted segmentation learning procedure to pre-train the segmentation network en masse. Experiment results show that, with ImageNet accompanied by PSSL as the source dataset, the proposed end-to-end pre-training strategy successfully boosts the performance of various segmentation models, i.e., PSPNet-ResNet50, DeepLabV3-ResNet50, and OCRNet-HRNetW18, on a number of segmentation tasks, such as CamVid, VOC-A, VOC-C, ADE20K, and CityScapes, with significant improvements. The source code is availabel at https://github.com/PaddlePaddle/PaddleSeg.