 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRollout Pass-Rate Control: Steering Binary-Reward RL Toward Its Most Informative Regime
May 06, 2026SWE-bench-style agentic reinforcement learning relies on expensive stateful trajectories, yet substantial compute is wasted on sampled rollout groups with skewed pass rates, where binary rewards provide a weak contrastive signal. We frame this inefficiency as a pass-rate control problem and show that a 50% pass rate is the most informative operating point: it maximizes reward entropy, the probability of surviving group filtering, RLOO advantage energy under GRPO, and success--failure contrastive structure. Guided by this principle, we propose Prefix Sampling (PS), which replays trajectory prefixes to steer skewed groups toward this regime: successful prefixes serve as head starts for mostly failing groups, while failing prefixes serve as handicaps for mostly passing groups. In stateful agent environments, prefix states are reconstructed through replay while replayed tokens are excluded from the loss, restricting optimization to continuations generated by the current policy. On SWE-bench-style agentic RL, PS delivers end-to-end wall-clock speedups of 2.01x on Qwen3-14B and 1.55x on Qwen3-32B while preserving or improving final verified performance. For 14B, the SWE-bench Verified peak rises from the baseline peak of 0.273 to 0.295 under PS. Additional mathematical reasoning experiments on AIME 2025 show the same pass-rate control pattern and decompose the gains into replay, bidirectional coverage, and adaptive control.
Detached Skip-Links and $R$-Probe: Decoupling Feature Aggregation from Gradient Propagation for MLLM OCR
Mar 20, 2026Multimodal large language models (MLLMs) excel at high-level reasoning yet fail on OCR tasks where fine-grained visual details are compromised or misaligned. We identify an overlooked optimization issue in multi-layer feature fusion. Skip pathways introduce direct back-propagation paths from high-level semantic objectives to early visual layers. This mechanism overwrites low-level signals and destabilizes training. To mitigate this gradient interference, we propose Detached Skip-Links, a minimal modification that reuses shallow features in the forward pass while stopping gradients through the skip branch during joint training. This asymmetric design reduces gradient interference, improving stability and convergence without adding learnable parameters. To diagnose whether fine-grained information is preserved and usable by an LLM, we introduce $R$-Probe, which measures pixel-level reconstructability of projected visual tokens using a shallow decoder initialized from the first quarter of the LLM layers. Across multiple ViT backbones and multimodal benchmarks, and at scales up to 7M training samples, our approach consistently improves OCR-centric benchmarks and delivers clear gains on general multimodal tasks.
Qianfan-OCR: A Unified End-to-End Model for Document Intelligence
Mar 11, 2026We present Qianfan-OCR, a 4B-parameter end-to-end vision-language model that unifies document parsing, layout analysis, and document understanding within a single architecture. It performs direct image-to-Markdown conversion and supports diverse prompt-driven tasks including table extraction, chart understanding, document QA, and key information extraction. To address the loss of explicit layout analysis in end-to-end OCR, we propose Layout-as-Thought, an optional thinking phase triggered by special think tokens that generates structured layout representations -- bounding boxes, element types, and reading order -- before producing final outputs, recovering layout grounding capabilities while improving accuracy on complex layouts. Qianfan-OCR ranks first among end-to-end models on OmniDocBench v1.5 (93.12) and OlmOCR Bench (79.8), achieves competitive results on OCRBench, CCOCR, DocVQA, and ChartQA against general VLMs of comparable scale, and attains the highest average score on public key information extraction benchmarks, surpassing Gemini-3.1-Pro, Seed-2.0, and Qwen3-VL-235B. The model is publicly accessible via the Baidu AI Cloud Qianfan platform.
SWE-Hub: A Unified Production System for Scalable, Executable Software Engineering Tasks
Feb 28, 2026Progress in software-engineering agents is increasingly constrained by the scarcity of executable, scalable, and realistic data for training and evaluation. This scarcity stems from three fundamental challenges in existing pipelines: environments are brittle and difficult to reproduce across languages; synthesizing realistic, system-level bugs at scale is computationally expensive; and existing data predominantly consists of short-horizon repairs, failing to capture long-horizon competencies like architectural consistency. We introduce \textbf{SWE-Hub}, an end-to-end system that operationalizes the data factory abstraction by unifying environment automation, scalable synthesis, and diverse task generation into a coherent production stack. At its foundation, the \textbf{Env Agent} establishes a shared execution substrate by automatically converting raw repository snapshots into reproducible, multi-language container environments with standardized interfaces. Built upon this substrate, \textbf{SWE-Scale} engine addresses the need for high-throughput generation, combining cross-language code analysis with cluster-scale validation to synthesize massive volumes of localized bug-fix instances. \textbf{Bug Agent} generates high-fidelity repair tasks by synthesizing system-level regressions involving cross-module dependencies, paired with user-like issue reports that describe observable symptoms rather than root causes. Finally, \textbf{SWE-Architect} expands the task scope from repair to creation by translating natural-language requirements into repository-scale build-a-repo tasks. By integrating these components, SWE-Hub establishes a unified production pipeline capable of continuously delivering executable tasks across the entire software engineering lifecycle.
QianfanHuijin Technical Report: A Novel Multi-Stage Training Paradigm for Finance Industrial LLMs
Dec 30, 2025Domain-specific enhancement of Large Language Models (LLMs) within the financial context has long been a focal point of industrial application. While previous models such as BloombergGPT and Baichuan-Finance primarily focused on knowledge enhancement, the deepening complexity of financial services has driven a growing demand for models that possess not only domain knowledge but also robust financial reasoning and agentic capabilities. In this paper, we present QianfanHuijin, a financial domain LLM, and propose a generalizable multi-stage training paradigm for industrial model enhancement. Our approach begins with Continual Pre-training (CPT) on financial corpora to consolidate the knowledge base. This is followed by a fine-grained Post-training pipeline designed with increasing specificity: starting with Financial SFT, progressing to Finance Reasoning RL and Finance Agentic RL, and culminating in General RL aligned with real-world business scenarios. Empirical results demonstrate that QianfanHuijin achieves superior performance across various authoritative financial benchmarks. Furthermore, ablation studies confirm that the targeted Reasoning RL and Agentic RL stages yield significant gains in their respective capabilities. These findings validate our motivation and suggest that this fine-grained, progressive post-training methodology is poised to become a mainstream paradigm for various industrial-enhanced LLMs.
Tree-of-Code: A Tree-Structured Exploring Framework for End-to-End Code Generation and Execution in Complex Task Handling
Dec 19, 2024Solving complex reasoning tasks is a key real-world application of agents. Thanks to the pretraining of Large Language Models (LLMs) on code data, recent approaches like CodeAct successfully use code as LLM agents' action, achieving good results. However, CodeAct greedily generates the next action's code block by relying on fragmented thoughts, resulting in inconsistency and instability. Moreover, CodeAct lacks action-related ground-truth (GT), making its supervision signals and termination conditions questionable in multi-turn interactions. To address these issues, we first introduce a simple yet effective end-to-end code generation paradigm, CodeProgram, which leverages code's systematic logic to align with global reasoning and enable cohesive problem-solving. Then, we propose Tree-of-Code (ToC), which self-grows CodeProgram nodes based on the executable nature of the code and enables self-supervision in a GT-free scenario. Experimental results on two datasets using ten popular zero-shot LLMs show ToC remarkably boosts accuracy by nearly 20% over CodeAct with less than 1/4 turns. Several LLMs even perform better on one-turn CodeProgram than on multi-turn CodeAct. To further investigate the trade-off between efficacy and efficiency, we test different ToC tree sizes and exploration mechanisms. We also highlight the potential of ToC's end-to-end data generation for supervised and reinforced fine-tuning.
Tree-of-Code: A Hybrid Approach for Robust Complex Task Planning and Execution
Dec 18, 2024The exceptional capabilities of large language models (LLMs) have substantially accelerated the rapid rise and widespread adoption of agents. Recent studies have demonstrated that generating Python code to consolidate LLM-based agents' actions into a unified action space (CodeAct) is a promising approach for developing real-world LLM agents. However, this step-by-step code generation approach often lacks consistency and robustness, leading to instability in agent applications, particularly for complex reasoning and out-of-domain tasks. In this paper, we propose a novel approach called Tree-of-Code (ToC) to tackle the challenges of complex problem planning and execution with an end-to-end mechanism. By integrating key ideas from both Tree-of-Thought and CodeAct, ToC combines their strengths to enhance solution exploration. In our framework, each final code execution result is treated as a node in the decision tree, with a breadth-first search strategy employed to explore potential solutions. The final outcome is determined through a voting mechanism based on the outputs of the nodes.
Warming Up Cold-Start CTR Prediction by Learning Item-Specific Feature Interactions
Jul 14, 2024In recommendation systems, new items are continuously introduced, initially lacking interaction records but gradually accumulating them over time. Accurately predicting the click-through rate (CTR) for these items is crucial for enhancing both revenue and user experience. While existing methods focus on enhancing item ID embeddings for new items within general CTR models, they tend to adopt a global feature interaction approach, often overshadowing new items with sparse data by those with abundant interactions. Addressing this, our work introduces EmerG, a novel approach that warms up cold-start CTR prediction by learning item-specific feature interaction patterns. EmerG utilizes hypernetworks to generate an item-specific feature graph based on item characteristics, which is then processed by a Graph Neural Network (GNN). This GNN is specially tailored to provably capture feature interactions at any order through a customized message passing mechanism. We further design a meta learning strategy that optimizes parameters of hypernetworks and GNN across various item CTR prediction tasks, while only adjusting a minimal set of item-specific parameters within each task. This strategy effectively reduces the risk of overfitting when dealing with limited data. Extensive experiments on benchmark datasets validate that EmerG consistently performs the best given no, a few and sufficient instances of new items.
ColdNAS: Search to Modulate for User Cold-Start Recommendation
Jun 06, 2023



Making personalized recommendation for cold-start users, who only have a few interaction histories, is a challenging problem in recommendation systems. Recent works leverage hypernetworks to directly map user interaction histories to user-specific parameters, which are then used to modulate predictor by feature-wise linear modulation function. These works obtain the state-of-the-art performance. However, the physical meaning of scaling and shifting in recommendation data is unclear. Instead of using a fixed modulation function and deciding modulation position by expertise, we propose a modulation framework called ColdNAS for user cold-start problem, where we look for proper modulation structure, including function and position, via neural architecture search. We design a search space which covers broad models and theoretically prove that this search space can be transformed to a much smaller space, enabling an efficient and robust one-shot search algorithm. Extensive experimental results on benchmark datasets show that ColdNAS consistently performs the best. We observe that different modulation functions lead to the best performance on different datasets, which validates the necessity of designing a searching-based method.
Large-scale Knowledge Distillation with Elastic Heterogeneous Computing Resources
Jul 14, 2022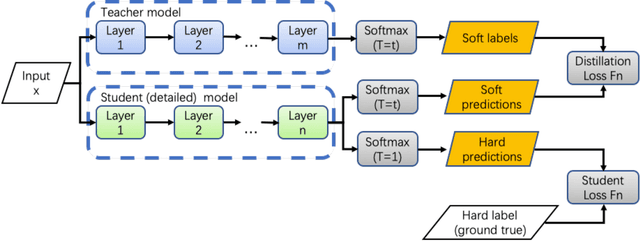

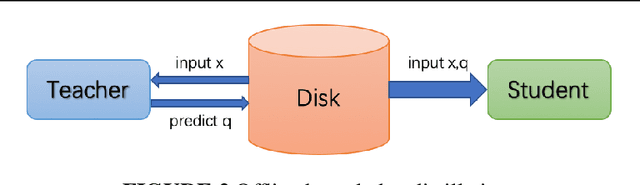
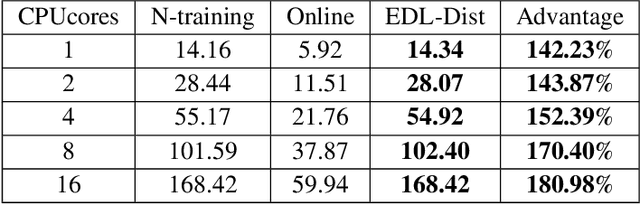
Although more layers and more parameters generally improve the accuracy of the models, such big models generally have high computational complexity and require big memory, which exceed the capacity of small devices for inference and incurs long training time. In addition, it is difficult to afford long training time and inference time of big models even in high performance servers, as well. As an efficient approach to compress a large deep model (a teacher model) to a compact model (a student model), knowledge distillation emerges as a promising approach to deal with the big models. Existing knowledge distillation methods cannot exploit the elastic available computing resources and correspond to low efficiency. In this paper, we propose an Elastic Deep Learning framework for knowledge Distillation, i.e., EDL-Dist. The advantages of EDL-Dist are three-fold. First, the inference and the training process is separated. Second, elastic available computing resources can be utilized to improve the efficiency. Third, fault-tolerance of the training and inference processes is supported. We take extensive experimentation to show that the throughput of EDL-Dist is up to 3.125 times faster than the baseline method (online knowledge distillation) while the accuracy is similar or higher.